Networks for the smallest. Part six. Dynamic routing
All issues
8. Networks for the smallest. Part Eight BGP and IP SLA
7. Networks for the smallest. Part Seven. VPN
6. Networks for the smallest. Part six. Dynamic routing
5. Networks for the smallest: Part Five. NAT and ACL
4. Networks for the smallest: Part Four. STP
3. Networks for the smallest: Part Three. Static routing
2. Networks for the smallest. Part two. Switching
1. Networks for the smallest. Part one. Connection to the equipment cisco
0. Networks for the smallest. Part zero. Planning
7. Networks for the smallest. Part Seven. VPN
6. Networks for the smallest. Part six. Dynamic routing
5. Networks for the smallest: Part Five. NAT and ACL
4. Networks for the smallest: Part Four. STP
3. Networks for the smallest: Part Three. Static routing
2. Networks for the smallest. Part two. Switching
1. Networks for the smallest. Part one. Connection to the equipment cisco
0. Networks for the smallest. Part zero. Planning
The network “Elevator Mi Up” together with its staff is growing along and across. Maintenance of the IT infrastructure was carried out in a separate specially created organization “Link me Up”.
Just recently, four more branches were bought in various cities and investors discovered new dimensions of the movement of elevators. And the network grew from four routers to ten at once. At the same time, the number of subnets has now increased from 9 to 20, not counting point-to-point links between routers. And then the entire economy rises up to its full height. Agree, adding routes to all networks manually on each node is a little fun.
The situation is complicated by the fact that the network in Kaliningrad already has its addressing and the dynamic routing protocol EIGRP is running on it.
So today:
- We understand the theory of dynamic routing protocols.
- We implement the OSPF protocol into the network “Elevator mi Up”
- Configure the transfer (redistribution) of routes between OSPF and EIGRP
- In this release, we add the “Tasks” section. Identify the course of their article will be such icons:
The difficulty level will be different. All tasks will have answers that can be viewed on the cycle website. In some of them you will need to think, in others read the documentation, in the third to understand the topology, and maybe even look at the debug information. If the task is not realizable in RT, we will make a special mark about it.
')
Theory of Dynamic Routing Protocols
For a start, let's deal with the concept of “dynamic routing”. Until now, we used the so-called static routing, that is, we wrote down the routing table on each router. The use of routing protocols allows us to avoid this tedious monotonous process and human error. As the name implies, these protocols are designed to build the routing tables themselves, automatically , based on the current network configuration. In general, the thing is necessary, especially when your network is not 3 routers, but 30, for example.
In addition to convenience, there are other aspects. For example, fault tolerance . Having a network with static routing, it will be extremely difficult for you to organize backup channels - there is no one to track the availability of one or another segment.

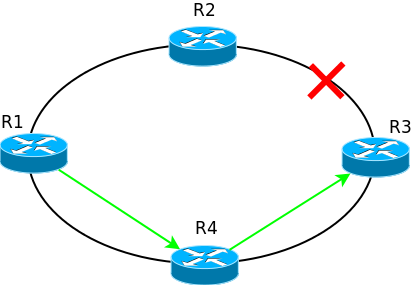
For example, if in such a network a link is broken between R2 and R3, then packets from R1 will still go to R2, where they will be destroyed, because they have nowhere to send.

Dynamic routing protocols within a few seconds (or even milliseconds) will learn about the problems on the network and rebuild their routing tables and in the above case, the packets will be sent along the actual route.
Another important point is traffic balancing . Dynamic routing protocols almost out of the box support this feature and you do not need to add redundant routes manually, calculating them.
Well, the introduction of dynamic routing greatly facilitates the scaling of the network . When you add a new element to a network or subnet on an existing router, you need to perform just a few actions to make it work and the probability of error is minimal, while information about changes instantly diverges across all devices. Exactly the same can be said about global topology changes.
All routing protocols can be divided into two large groups: external ( EGP - Exterior Gateway Protocol) and internal ( IGP - Interior Gateway Protocol). To explain the differences between them, we need the term “autonomous system”. In a general sense, an autonomous system (routing domain) is a group of routers that are under common control.
In the case of our updated network, AS will be:

So, internal routing protocols are used inside the autonomous system, and external - to connect autonomous systems with each other. In turn, the internal routing protocols are divided into Distance-Vector (RIP, EIGRP) and Link State (OSPF, IS-IS). In this article, we will not
The fundamental differences between the two species are as follows:
1) the type of information that routers exchange: the routing tables of Distance-Vector and the topology tables of Link State,
2) the process of choosing the best route,
3) the amount of network information that each router “keeps in mind”: Distance-Vector knows only its neighbors, Link State has an idea of the entire network.
As we can see, the number of routing protocols is small, but still not one or two. And what will happen if you run several protocols on the router at the same time? It may turn out that each protocol will have its own opinion on how best to get to a certain network. And if we also have static routes configured? Who will give preference to the router and whose route will add to the routing table? The answer to this question is related to the new term: administrative distance (for our taste, rather mediocre tracing from the English administrative distance, but weren't better able to invent). The administrative distance is an integer from 0 to 255, expressing the router’s “measure of confidence” to this route. The smaller the AD, the more trust. Here is a sign of such trust from a Cisco perspective:
| Protocol | Administrative distance |
|---|---|
| Connected interface | 0 |
| Static route | one |
| Enhanced Interior Gateway Routing Protocol (EIGRP) summary route | five |
| External Border Gateway Protocol (BGP) | 20 |
| Internal EIGRP | 90 |
| IGRP | 100 |
| Ospf | 110 |
| Intermediate System-to-Intermediate System (IS-IS) | 115 |
| Routing Information Protocol (RIP) | 120 |
| Exterior Gateway Protocol (EGP) | 140 |
| On Demand Routing (ODR) | 160 |
| External EIGRP | 170 |
| Internal BGP | 200 |
| Unknown | 255 |
In today's article, we will analyze OSPF and EIGRP. The first you will meet everywhere and constantly, and the second is very good in networks where only Cisco equipment is present.
Each of them has its advantages and disadvantages. It can be said that EIGRP wins before OSPF, but all advantages are leveled by its proprietaryity. EIGRP is a proprietary Cisco protocol and no one else supports it.
In fact, EIGRP has many shortcomings, but this is not particularly spread in popular articles. Here is just one of the problems: SIA
So let's get started.
Ospf
Articles and videos on how to configure OSPF mountains. Much less descriptions of the principles of work. In general, there is such a thing that OSPF can be simply configured according to the manuals, without even knowing about the SPF algorithms and incomprehensible LSAs. And everything will work and even, most likely, work fine - that's what it is designed for. That is, it’s not like vlans, where you had to know the theory down to the format of the title.
But the engineer from the enikeyschik is distinguished by the fact that he understands why his network functions this way and not otherwise, and OSPF knows what route will be chosen by the protocol just as well as it does.
Within the article, which already at this moment is 8,000 characters, we will not be able to plunge into the depths of the theory, but we will consider the fundamental points.
It is very simple and understandable, by the way, it is written about OSPF on xgu.ru or in the English Wikipedia .
So, OSPFv2 works over IP, and specifically, it is sharpened only for IPv4 (OSPFv3 does not depend on Layer 3 protocols and therefore can work with IPv6).
Consider his work on the example of such a simplified network:

To begin with, it must be said that in order to establish friendship (adjacency) between routers, the following conditions must be met:
1) in OSPF, the same Hello Interval must be configured on those routers that are connected to each other. The default is 10 seconds on Broadcast networks, such as Ethernet. This is a kind of keepalive message. That is, every 10 seconds each router sends a Hello packet to its neighbor to say: “Hey, I'm alive”,
2) The same should be the Dead Interval on them. This is usually 4 Hello intervals - 40 seconds. If during this time Hello is not received from the neighbor, then it is considered inaccessible and
3) Interfaces connected to each other must be on the same subnet
4) OSPF reduces the CPU load on routers by dividing the Autonomous System into zones. So the zone numbers must also match,
5) Each router participating in the OSPF process has its own unique identifier - Router ID . If you do not take care of it, the router will automatically select it based on the information about the connected interfaces (the highest address is selected from the interfaces that were active at the time the OSPF process started). But again, a good engineer has everything under control, so a Loopback interface is usually created, which is assigned an address with a / 32 mask and it is he who is assigned a Router ID. It is convenient for maintenance and troubleshooting.
6) Must match MTU size
Next, the play in eight parts.
1) Calm. OSPF Status - DOWN
In this short moment, nothing happens on the network - everyone is silent.

2) The wind rises: the router sends Hello packets to the multicast address 224.0.0.5 from all interfaces where OSPF is running. The TTL of such messages is equal to one, so only routers in the same network segment will receive them. R1 goes to the INIT state.

The package contains the following information:
- Router ID
- Hello Interval
- Dead interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- DR and BDR Router Addresses
- Authentication password
We are interested in the first four, or more precisely in general, only Router ID and Neighbors.
Hello message from R1 carries its Router ID and does not contain Neighbors, because it does not have them yet.
After receiving this multicast message, R2 adds R1 to its neighbor table (if all the necessary parameters match).

And it sends a new Hello message to R1 already unicast, which contains the Router ID of this router, and all its neighbors are listed in the Neigbors list. Among the other neighbors in this list is Router ID R1, that is, R2 already considers it a neighbor.

3) Friendship. When R1 receives this Hello message from R2, it scrolls through the list of neighbors and finds its own Router ID in it, it adds R2 to its list of neighbors.
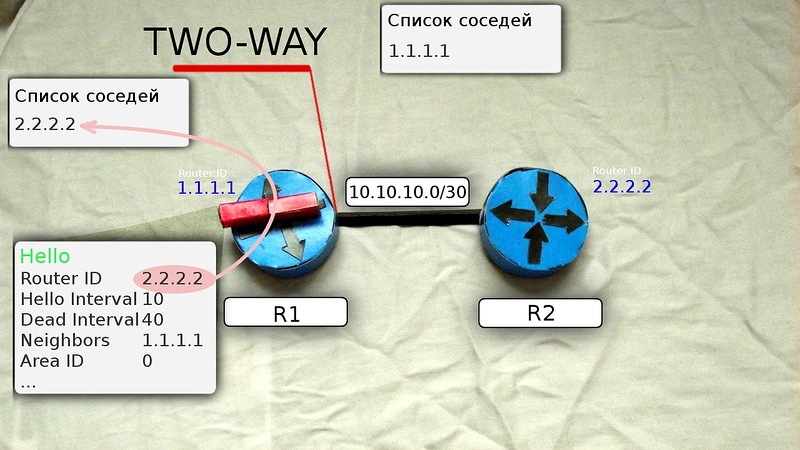
Now R1 and R2 are each other’s mutual neighbors - this means that they have an adjacency relationship and R1 enters the TWO WAY state.

Next comes the choice of DR and BDR , but we will not stop there, even though these are quite important things.
4) Calm before the storm. Then everything goes into the EXSTART state. Here, all the neighbors decide among themselves who the boss is. It becomes the router with the highest Router ID - R2.
5) When Dad is selected, neighbors go to the Exchange state and exchange DBD messages (or DD) - Data Base Description, which contain the description of LSDB (Link State Data Base), they say, I know about such subnets.
Here it is necessary to clarify what LSDB is. If you translate into Russian literally: a database on the state of links. In the initial state, the router knows only those links (interfaces) on which the OSPF process is running. As the play progresses, each router collects all the information about the network and compiles a topology. That it will be LSDB, which should be the same on all members of the zone.
The first one sends its DBD router selected as the main one on this interface - 2.2.2.2. 1.1.1.1 does the same after it.
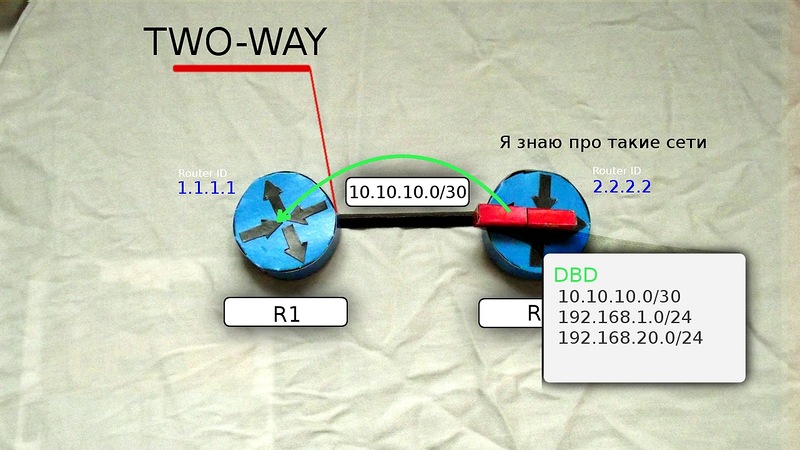
6) After receiving the message, the routers R1 and R2 send a confirmation of the reception of DBD (LSAck), and then compare the new information with that contained in the LSDB and, if there are differences, send the LSR (Link State Request) to each other, thereby moving to the new state of LOADING . In the LSR they say - “I don’t know anything about this network. Tell me more. ”
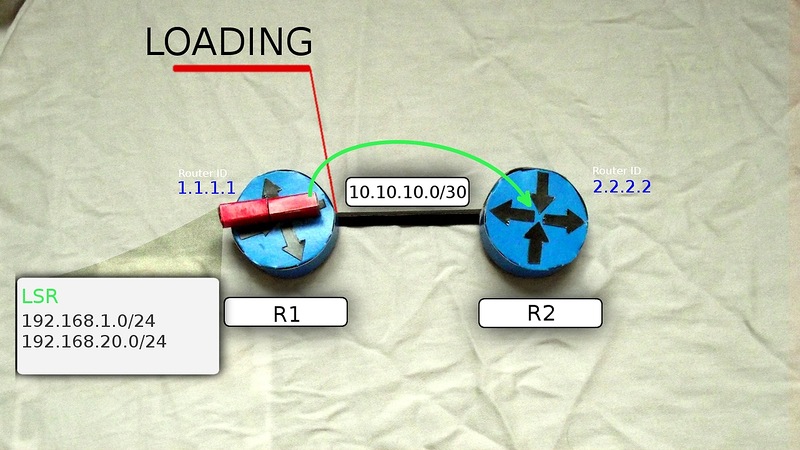
7) R2, receiving LSR from R1, sends LSU (Link State Update), which contain LSA (Link State Advertisement) with detailed information about the required subnets.
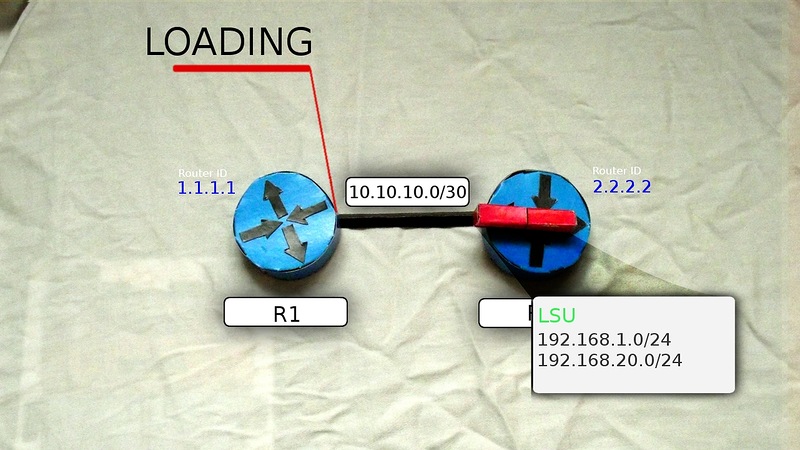
And so, as soon as R1 receives the last piece of data on all subnets and forms its LSDB, it enters its final state FULL STATE .
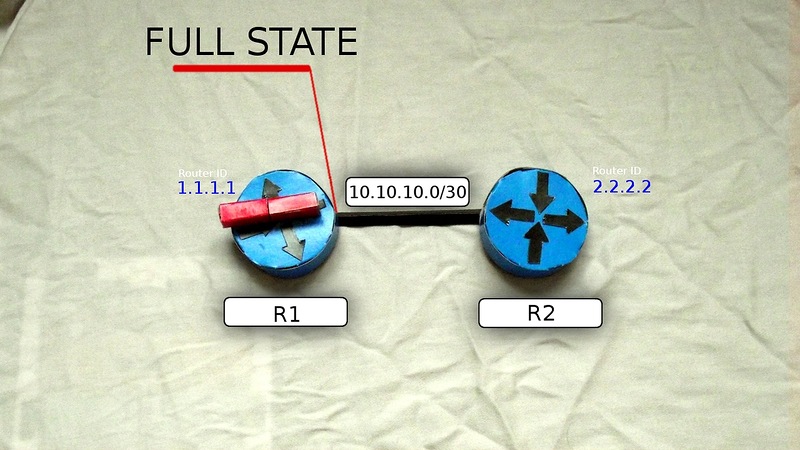
By that moment, as all the routers in the zone will come to the Full State state, all of them should have completely the same LSDB - they have studied the same network. That is, in fact, this means that the router knows your entire network, what, how and where it is connected.
The authors realize that it is quite difficult to understand and remember all these abbreviations and rules, but after reading this 5-7 times in different places with a certain frequency, it will be possible to get an idea of how OSPF works.
8) So, now we have all the routers know everything about the network, but this knowledge does not help in routing.
The next step OSPF, using Dijkstra's algorithm (or also called SPF - Shortest Path First), calculates the shortest route to each router in the zone - he knows the whole topology. This helps him metrics. The lower it is, the better the route. Metric - is the cost of movement on the route.

For example, in such a network from R1 to R3 can be reached directly or through R2.
Naturally the first option will cost less. But this is assuming that you have the same type of interface everywhere. And if, for example, between R1 and R3 do you have a 56k modem connection or an extremely unstable GPRS link? Then they will have a very high cost and OSPF will prefer a longer, but faster way.
The path found is then added to the routing table.
Now every 10 seconds each router will send Hello-packets, and LSA is sent every 30 minutes - this type of data is already considered obsolete, it would be necessary to update it, even if there were no changes.
In an ideal world, this would be a balance. But we live in a cruel and indifferent world, where an engineer is an engineer, and even a computer programmer in general, and elevators have learned to ride down just three issues ago. And in this everyday world passions are boiling: they tear optics, cut down food, mice gnaw through the legs of processors (or is it not in this world?) - in other words, the topology is constantly changing. And the larger the network, the more frequent and global changes.
Of course, it would be somewhat strange to wait 40 seconds (Dead Interval) and only then begin to rebuild the table. This would be excusable for RIP, but not for the protocol used in a huge number of modern networks. So, as soon as any of the links falls (or several), the router changes its LSDB and generates the LSU, assigning it a number greater than it was before (each LSDB has a number that is taken from the last LSA received).
This LSU message is sent to the multicast address 224.0.0.5. The routers that receive it check the LSA number contained in the LSU.
1) If the number is greater than the current LSA number of the router, the LSDB changes. (The LSDB version is old, the information is new),
2) If the number is the same, nothing happens. This router has already received this LSA in some other way,
3) If the number of received LSA is less than local LSDB, this means that the router has more up-to-date information, and it sends a new LSA (based on its LSDB) to the sender of the previous one.
After the produced (or non-generated) actions to the neighbor from which the LSU came, LSAck is sent (they say, “the package was received - everything is in order”), and the original LSU is sent to other neighbors unchanged. The SPF algorithm is run again on this router and, if necessary, the routing table is updated.
In general, all this happens in order to maintain the relevance of information on all devices - LSDB should be the same for all.
Here we must make a reservation that the router notices changes only when directly connected to its neighbor. If there is, for example, a switch between them, the device will not detect a drop in the physical interface and will not do anything. For such situations there are two solutions.
1) Set up timers. For OSPF, they can be reduced to the ms level.
2) Use the very cool BFD ( Bidirectional Forwarding Detection ) protocol. It allows you to track the status of the links also at the millisecond level. In the configuration, the BFD communicates with other protocols and allows you to very quickly inform anyone that there are problems on the network. Specifically with the BFD we will understand the other part.
As you have noticed, there are confirmations to all messages: either this is LSAck or the Hello response to Hello. This is a fee for rejecting TCP - somehow you have to make sure of successful delivery.
In total there are 7 types of LSA, which are very tied to zones, of which there are also 5 pieces. Routers also come in four types. And there are also concepts of Designated Router (DR) and Backup DR (BDR), ABR and ASBR. There are formulas for calculating metrics and so on and so forth. We leave it for independent study.
OSPF practice
Remember how we suffered when setting up the routing last time: on each device, up to each network and God forbid something to forget. Now it's in the past - long live the IGP!
Let's not waste time explaining the commands separately, but immediately plunge into the wonderful world of configuration.
Tax, there is now the following logical scheme:
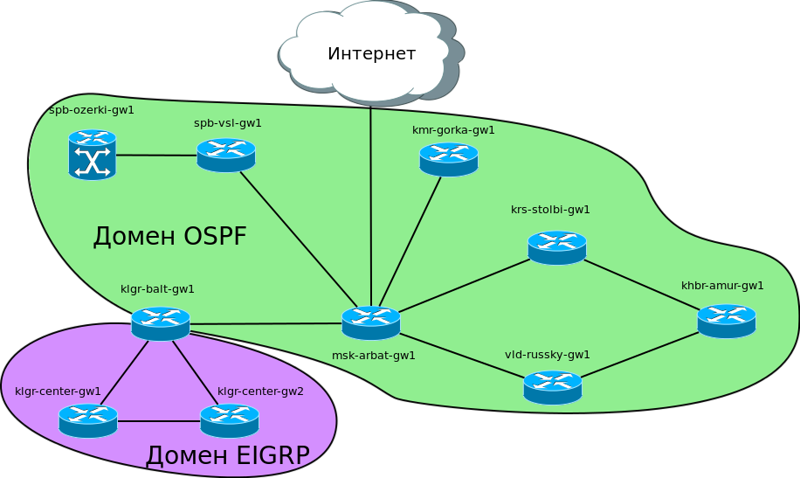
While we are interested in this big Siberian ring through Krasnoyarsk, Khabarovsk and Vladivostok. Here and on our already built network, we will run OSPF. Where there was static before, we will have to abandon it and smoothly switch to dynamic protocols.
Suppose that Krasnoyarsk is also connected via Balagan Telecom, as well as the previous points, and then through different providers we have links to other cities. The ring is closed in Moscow through the provider “Filkin certificate”. Suppose that everywhere between cities we bought L2-VPN and IP traffic flows transparently.
What does the implementation of IGP give specifically to our network?
1) Easy configuration, of course. At each node, you need to know only local networks, OSPF will be puzzled by the question of their distribution.
2) Redundant links that will provide us with redundant communication channels. If, for example, the homeless people cut off the optics between Moscow and Krasnoyarsk, not a single branch will remain without communication: all traffic will go through Vladivostok
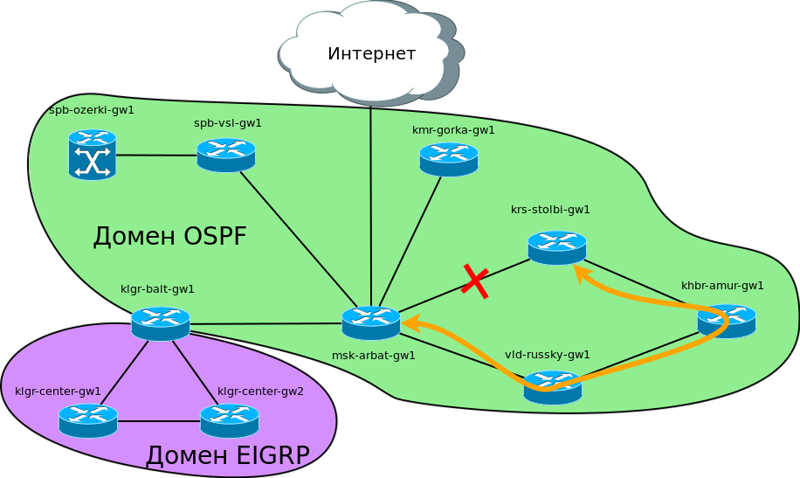
3) Automatic detection of problems, rebuilding the topology and changing the routing table. That is what makes it possible to comply with paragraph 2.
4) There is no danger of creating a routing loop when we have a packet to rush between two nodes until the TTL expires. With static tuning, this situation is more than possible.
5) Convenience expansion. Imagine that you need to add a new branch, for example in Tomsk and you will connect it through Kemerovo. Then you will have to register static routes in Moscow, Kemerovo and in Tomsk itself. When using speakers, you only set up a new router ... and that's it.
We already prepared the IP-plan of the subnets for the branches and the Point-to-Point links. Suppose that all the initial settings were also performed on all the nodes:
- hostname
- security settings (telnet passwords, ssh)
- IP addresses of link interfaces
- IP addresses of LAN subnets
- IP addresses of Loopback interfaces.
We are here introducing a new concept of a Loopback interface. It will be configured on each router. For this, a special subnet 172.16.255.0/24 is allocated. We need it now for OSPF, and in the future it may be needed for BGP, MPLS.
Hand on heart, he himself did not understand the meaning of these interfaces for a long time. Generally speaking, it is a virtual interface, the state of which is always UP, regardless of the state of the physical interfaces (unless shutdown is done on it). We will try to explain one of his roles:
Here, for example, you have a monitoring server Nagios. R1 FE0/0 — 10.1.0.1.
— . , .
, , FE0/1. Nagios' , , . , IP- .
Nagios' Loopback-, , .
IP- Loopback- /32, 11111111.11111111.11111111.1111111 — — .


Since all preparations have already been completed, we are faced with a very simple task: walk through all the routers and activate the OSPF process.
1) The first thing we need to do is start the OSPF process of the router:
msk-arbat-gw1 (config) # router OSPF 1
The first word is to indicate that we are launching a dynamic routing protocol, then we specify which one and last of all the process number (theoretically there can be several of them on the same router).
Immediately after this, the router ID is automatically assigned. By default this is the highest address of the Loopback-interfaces.
2) Do not leave this thing to chance. Main rule: Router ID must be unique. No, you, of course, can make them the same, but in this case you will begin to have oddities.
One of my applications was this: the equipment ends with LDP tags. Of the eight thousand with the hook, there was only one free. No new VPNs were created or worked. Understood, understood and as a result saw that process OSPF creates and deletes thousands records in a minute in the routing table. The topology is constantly being rebuilt, and for each such rebuilding new LDP tags are allocated, and then not released. And the thing is randomly configured identical Router ID.
You can configure it, in principle, as you like, you can not even configure it, the router will assign it itself, but for order we will do it - in the future it will be easier to maintain. We assign it according to the address of the Loopback interface.
msk-arbat-gw1 (config-router) # router-id 172.16.255.1
3) , ( OSPF). , wildcard- , ACL
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
. network , , , .
, IP 172.16.0.0 0.0.255.255 (172.16.0.0-172.16.255.255), .
:
) Hello-, .
) OSPF . 172.16.0.0 0.0.255.255, , ,
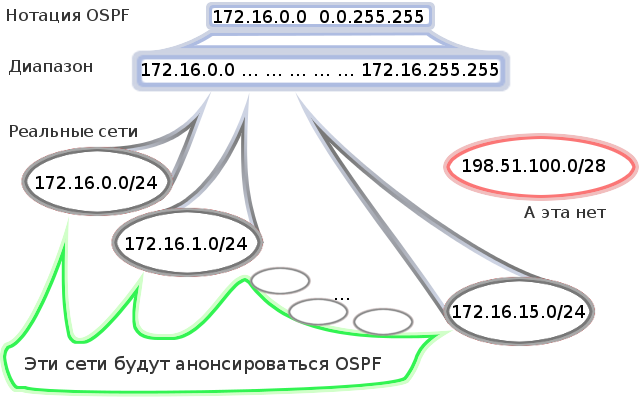
:
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
or
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.15.255 area 0
or
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.1.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.2.0 0.0.255.255 area 0
……
msk-arbat-gw1(config-router)#network 172.16.15.0 0.0.255.255 area 0
All these commands will work the same way in our case.
Since all local networks have addresses from the 172.16.0.0/16 network, we will use the most general entry. At the same time, of course, the external interface will not get into FastEthernet0 / 1.6 Internet, because its address - 198.51.100.2 - is not from this range.
With this setting, any new interface where you specify an address from the range 172.16.0.0 - 172.16.255.255 automatically becomes a participant in the OSPF process. Good or bad, depends on your desires.
area 0 means that these subnets belong to the zone with the number zero (in our examples only this will be).
Area 0 is not a simple area - this is the so-called Backbone-area. This means that it unites all other zones, i.e. A packet going from any non-zero zone to any non-zero zone must pass through area 0
As soon as you specify the network command, the words of greeting are sent from the correct interfaces, but there is no one to answer them - there are no neighbors:
msk-arbat-gw1 # sh ip OSPF neighbor
msk-arbat-gw1 #
Now let's write the OSPF settings in Kemerovo (router ID = IP address of the Loopback interface, taken from the IP plan):
kmr-gorka-gw1 (config) #router OSPF 1
kmr-gorka-gw1 (config-router) # router-id 172.16.255.48
kmr-gorka-gw1 (config-router) #network 172.16.0.0 0.0.255.255 area 0
And right after that you see a message in the console.
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.1 on FastEthernet0/0.5 from LOADING to FULL, Loading Done
:
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.48 on FastEthernet0/1.5 from LOADING to FULL, Loading Done.
, LSA. LSDB.
:
msk-arbat-gw1#sh ip OSPF neighbor detail
Neighbor 172.16.255.48 , interface address 172.16.2.18
In the area 0 via interface FastEthernet0/1.5
Neighbor priority is 1, State is FULL , 4 state changes
DR is 172.16.2.17 BDR is 172.16.2.18
Options is 0x00
Dead timer due in 00:00:38
Neighbor is up for 00:02:51
Index 1/1, retransmission queue length 0, number of retransmission 0
First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0)
Last retransmission scan length is 0, maximum is 0
Last retransmission scan time is 0 msec, maximum is 0 msec
:
router-id (172.16.255.48), loopback, , (172.16.2.18), (FastEthernet0/1.5), (FULL) Dead timer. , . , , ! 40. 10 Hello
show ip route , :
msk-arbat-gw1#show ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 17 subnets, 5 masks
C 172.16.0.0/24 is directly connected, FastEthernet0 / 0.3
C 172.16.1.0/24 is directly connected, FastEthernet0 / 0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0 / 1.7
C 172.16.2.128/30 is directly connected, FastEthernet0 / 1.8
C 172.16.2.196/30 is directly connected, FastEthernet1 / 0.911
C 172.16.3.0/24 is directly connected, FastEthernet0 / 0.101
C 172.16.4.0/24 is directly connected, FastEthernet0 / 0.102
C 172.16.5.0/24 is directly connected, FastEthernet0 / 0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S * 0.0.0.0/0 [1/0] via 198.51.100.1
In addition to the previously known networks (C - directly connected and S - Static), we have two new routes labeled O (OSPF). Everything should be clear here, but an observant reader will ask: “Why are there two routes to the network 172.16.24.0 in the routing table? Why won't the more preferred static one remain? ”And it will be right. Generally speaking, only the best route to the network gets to the routing table - the default is one. But note that the static route goes to subnet 172.16.24.0/22, and received from OSPF to 172.16.24.0/24. These are different subnets, so both of them found a place before the sun. The fact is that OSPF has no idea what you planned there and what range you selected - it operates with real data, that is, an IP address and mask:
interface FastEthernet0 / 0.2
ip address 172.16.24.1 255.255.255.0
:
kmr-gorka-gw1#sh ip route
Gateway of last resort is 172.16.2.17 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 14 subnets, 3 masks
O 172.16.0.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.1.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.0/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.2.16/30 is directly connected, FastEthernet0/0.5
O 172.16.2.32/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.128/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.196/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.3.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.4.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.5.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.6.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.24.0/24 is directly connected, FastEthernet0/0.2
O 172.16.255.1/32 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.255.48/32 is directly connected, Loopback0
S* 0.0.0.0/0 [1/0] via 172.16.2.17
, , .
:
S* 0.0.0.0/0 [ 1/0 ]
O 172.16.6.0/24 [ 110/2 ]
The first digit is the administrative distance, which is much longer for OSPF than for static and, accordingly, the priority is lower.
In fact, to the subnet 172.16.24.0/24, the traffic has already taken the route provided by OSPF, because it has a narrower mask (24 vs. 22).
But let's try to remove static routes and see what happens.
Quite predictably everything works:
msk-arbat-gw1 # ping 172.16.24.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.24.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min / avg / max = 8/10/15 ms
And it is beautiful.
Configure OSPF in St. Petersburg:
spb-vsl-gw1 (config) #router OSPF 1
spb-vsl-gw1 (config-router) # router-id 172.16.255.32
spb-vsl-gw1 (config-router) #network 172.16.0.0 0.0.255.255 area 0
, , . , OSFP , , .
msk-arbat-gw1
msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:39 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DROTHER 00:00:31 172.16.2.18 FastEthernet0/1.5
( ) :
spb-vsl-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.1 1 FULL/DR 00:00:34 172.16.2.1 FastEthernet1/0.4
, , spb-vsl-gw1 kmr-gorka-gw1 msk-arbat-gw1, .
— spb-ozerki-gw1 , . — Router ID. .
№1. Hello 3 , , 12 Hello .
Answer
:
, :
— , ?
— ?
, , , , , , , .
- .
On a real network, when choosing a range of advertised subnets, one should be guided by regulations and immediate needs.
Before we proceed to testing the backup links and speeds, let's do one more useful thing.
If we had the opportunity to catch traffic on the interface FE0 / 0.2 msk-arbat-gw1, which looks towards the servers, then we would see that Hello messages fly into the unknown every 10 seconds. There is no one to answer Hello, there is no one to establish an adjacency relationship, therefore there is no sense in trying to send messages from here.
Turning it off is very simple:
msk-arbat-gw1 (config) #router OSPF 1
msk-arbat-gw1 (config-router) # passive-interface fastEthernet 0 / 0.2
This command should be given for all interfaces on which there are definitely no OSPF neighbors (including towards the Internet).
As a result, you will have the following picture:
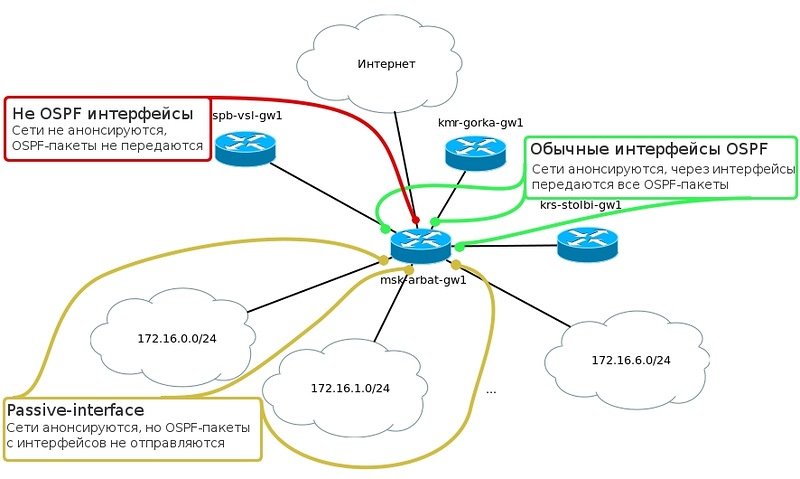
* I don’t imagine how you are still not confused *
In addition, this command improves security - none of this network pretends to be a router and will not try to break us completely.
Now let's do the most interesting - testing.
There is nothing difficult in setting up OSPF on all routers in the Siberian ring - you will do it yourself.
And after that the picture should be as follows:
msk-arbat-gw1 # sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL / DR 00:00:31 172.16.2.2 FastEthernet0 / 1.4
172.16.255.48 1 FULL / DR 00:00:31 172.16.2.18 FastEthernet0 / 1.5
172.16.255.80 1 FULL / BDR 00:00:36 172.16. 2.130 FastEthernet0 / 1.8
172.16.255.112 1 FULL / BDR 00:00:37 172.16.2.197 FastEthernet1 / 0.911
Peter, Kemerovo, Krasnoyarsk and Vladivostok are directly connected.
msk-arbat-gw1 # sh ip route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
C 172.16.0.0/24 is directly connected, FastEthernet0 / 0.3
C 172.16.1.0/24 is directly connected, FastEthernet0 / 0.2
C 172.16.2.0/30 is directly connected, FastEthernet0 / 1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0 / 1.5
C 172.16.2.32/30 is directly connected, FastEthernet0 / 1.7
C 172.16.2.128/30 is directly connected, FastEthernet0 / 1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1 / 0.911
C 172.16.3.0/24 is directly connected, FastEthernet0 / 0.101
C 172.16.4.0/24 is directly connected, FastEthernet0 / 0.102
C 172.16.5.0/24 is directly connected, FastEthernet0 / 0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:04:18, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:04:28, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S * 0.0.0.0/0 [1/0] via 198.51.100.1
.
? , krs-stolbi-gw1 :
msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.1
1 172.16.2.130 35 msec 8 msec 5 msec

, .
5 , :
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1
vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1
msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.1
1 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
That is, now Krasnoyarsk traffic reaches this way:

As soon as you lift the link, the routers re-connect, exchange their bases, recalculate the shortest paths and enter into the routing table.
In the video all this is more obvious. I recommend to get acquainted .
Problem number 2After setting up OSPF on routers in the Siberian ring, all networks that are located behind the router at the central office in Moscow (msk-arbat-gw1) are available to Khabarovsk along two routes (through Krasnoyarsk and through Vladivostok). But, since the channel through Krasnoyarsk is better, it is necessary to change the default settings so that Khabarovsk uses the channel through Krasnoyarsk when it is available. And he switched to Vladivostok only if something happened to the channel to Krasnoyarsk.
Answer
Like any good protocol, OSPF supports authentication — two neighbors can verify the authenticity of received OSPF messages before establishing neighborhood ratios. Leaving for self-study is quite simple.
Task number 3An unpleasant story happened with the provider "Filkin Certificate". Due to their error in the VPN settings, some strange routes began to arrive at the router in Vladivostok, probably from another client or the internal network of the provider. Some networks intersected with local networks and communication with some parts of the network was lost. After this incident, it was decided to protect against such situations for the future.
The situation, generally speaking, is far-fetched and unlikely, but it will work as a problem.
In the area between Moscow and Vladivostok, it is necessary to configure routers so that they, when establishing neighborhood relations, also check the set password. The password should be: MskVladPass and it should be transmitted in the form of hash md5 (key number 1).
Answer
EIGRP
Now let's do another very important protocol.
So how good is EIGRP?
- easy to configure
- quick switch to pre-calculated backup route
- requires less router resources (compared to OSPF)
- summation of routes on any router (in OSPF only on ABR \ ASBR)
- balancing traffic on unequal routes (OSPF only on equivalent)
We decided to translate one of the blog entries of Ivan Pepelnyak, which deals with a number of popular myths about EIGRP:
“EIGRP is a hybrid routing protocol.” If I remember correctly, it started with the first EIGRP presentation many years ago and is usually understood as “EIGRP took the best from the link-state and distance-vector protocols”. This is absolutely not true. EIGRP has no distinctive features of the link-state. It will correctly say “EIGRP is an advanced distance-vector- routing protocol”.
“EIGRP is the distance-vector protocol.” Not bad, but not completely true either. EIGRP differs from other DVs in the way it handles lost routes (or routes with an increasing metric). All other protocols passively wait for updates from a neighbor (some, for example, RIP, even block the route to prevent routing loops), while EIGRP behaves more actively and requests information itself.
“EIGRP is difficult to implement and maintain.” Not true. At one time, EIGRP in large networks with low-speed links was difficult to implement correctly, but just before stub routers were introduced. With them (as well as several fixes of the DUAL algorithm), it is not nearly as good as OSPF.
“Like the LS protocols, EIGRP stores the table of the topology of the routes it exchanges.” It's amazing how wrong it is. EIGRP has no idea what is next of the nearest neighbors, while the LS protocols know the topology of the entire area to which they are connected.
“EIGRP is a DV protocol that acts like LS.” Not a bad attempt, but still, absolutely wrong. LS protocols build a routing table by going through the following steps:
- each router describes a network based on information available locally to it (its links, the subnets in which it is located, the neighbors it sees) through a packet (or several) called LSA (in OSPF) or LSP (IS-IS)
- LSA distributed over the network. Each router should receive each LSA created on its network. The information obtained from the LSA is recorded in the topology table.
- each router independently analyzes its topology table and runs an SPF algorithm to calculate the best routes to each of the other routers
The behavior of EIGRP doesn’t even closely resemble these steps, so it’s unclear why it “acts like LS”
The only thing that EIGRP does is that it stores information received from a neighbor (the RIP immediately forgets that it cannot be used at the moment). In this sense, it is similar to BGP, which also stores everything in the BGP table and selects the best route from there. The topology table (containing all the information received from the neighbors) gives EIGRP an advantage over RIP — it can contain information about the backup (not currently used) route.
Now a little closer to the theory of work:
Each EIGRP process serves 3 tables:
- The table of neighbors (neighbor table), which contains information about the “neighbors”, i.e. other routers directly connected to the current and participating in the exchange of routes. You can view it using the show ip eigrp neighbors command
- The network topology table (topology table), which contains information about routes received from neighbors. We are watching with the show ip eigrp topology command
- Routing table (routing table), on the basis of which the router makes decisions about packet forwarding. View through show ip route
Metrics.
To assess the quality of a particular route, a certain number is used in the routing protocols, reflecting its various characteristics or a set of characteristics — a metric. The characteristics taken into account may vary - starting with the number of routers on a given route and ending with the arithmetic average of all interfaces along the route. Regarding the EIGRP metric, we quote Jeremy Cioara: “I had the impression that the creators of EIGRP, with a critical eye on their creation, decided that everything was too simple and worked well. And then they came up with the formula of the metric, that everyone would say “WOW, it really is difficult and professional looking.” Behold the complete formula for calculating the EIGRP metric: (K1 * bw + (K2 * bw) / (256 - load) + K3 * delay) * (K5 / (reliability + K4)), in which:
- bw is not just bandwidth, but (10,000,000 / smallest bandwidth along the route route in kilobits) * 256
- delay is not just a delay, but the sum of all delays on the way in tens of microseconds * 256 (delay in the show interface, show ip eigrp topology and other commands is shown in microseconds!)
- K1-K5 are the coefficients that serve to ensure that this or that parameter is “included” in the formula.
Fearfully? it would be if it all worked as written. In fact, of all 4 possible terms of the formula, only two are used by default: bw and delay (the coefficients K1 and K3 = 1, the rest are zero), which greatly simplifies it - we simply add these two numbers (not forgetting that still considered by their formulas). It is important to remember the following: the metric is considered to be the worst throughput indicator along the entire length of the route .
An interesting thing to do with MTU: quite often you can find information that MTU is related to the EIGRP metric. Indeed, the MTU values are transmitted when exchanging routes. But, as we can see from the complete formula, there is no mention of MTU. The fact is that this indicator is taken into account in quite specific cases: for example, if the router has to discard one of the routes that are equivalent in other characteristics, it will choose the one with the lowest MTU. Although not everything is so simple (see comments).
We define the terms used within EIGRP. Each route in EIGRP is characterized by two numbers: Feasible Distance and Advertised Distance (instead of Advertised Distance, you can sometimes find Reported Distance, which is one and the same). Each of these numbers represents a metric, or the cost (the more, the worse) of the route from different measurement points: FD is “from me to the destination”, and AD- “from the neighbor who told me about this route to the place destination. The answer to the legitimate question “Why do we need to know the cost from a neighbor, if it is already included in FD?” - just below (as long as you can stop and break your head if you want).
Each subnet that EIGRP knows about, on each router, there exists a Successor router from among its neighbors, through which the best (with a smaller metric), according to the protocol, route to this subnet. In addition, a subnet may also have one or several alternate routes (the router-neighbor through which such a route goes is called Feasible Successor). EIGRP is the only routing protocol that stores backup routes (they are in OSPF, but are contained, so to speak, in a “raw form” in the topology table — they still need to be processed using the SPF algorithm), which gives it a plus in speed: as soon as the protocol determines that the main route (via successor) is not available, it immediately switches to the backup. In order for a router to become a feasible successor for a route, its AD must be less than the FD successor of this route (this is why we need to know AD). This rule applies to avoid routing rings.
The previous paragraph blew the brain? The material is difficult, so once again by example. We have this network:
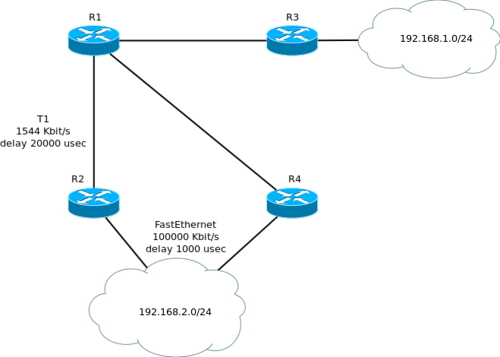
From the point of view of R1, R2 is Successor for the 192.168.2.0/24 subnet. To become a FS for this subnet, R4 requires its AD to be less than FD for this route. FD is here ((10000000/1544) * 256) + (2100 * 256) = 2195456, AD in R4 (from his point of view, this is FD, that is, how much he should get to this network) = ((10000000/100000 ) * 256) + (100 * 256) = 51200. Everything converges, AD at R4 is less than the FD route, it becomes FS. * here is the brain and says: “BIDISH” *. Now we look at R3 - it announces its network 192.168.1.0/24 to its neighbor R1, which, in turn, tells about it to its neighbors R2 and R4. R4 does not know that R2 knows about this subnet, and decides to tell it. R2 transmits information that it has access through R4 to the subnet 192.168.1.0/24 further on to R1. R1 strictly looks at the FD route and AD, which R2 boasts (which, as it is easy to understand by the scheme, will obviously be more FD, as it includes it too) and drives it away so that it does not climb with all sorts of nonsense. This situation is rather improbable, but it can occur under certain circumstances, for example, when the split-horizon mechanism is turned off. And now to a more likely situation: Imagine that R4 is connected to the 192.168.2.0/24 network not via FastEthernet, but via a 56k modem (the dialup delay is 20,000 usec), respectively, it’s worth it ((10000000/56) * 256 ) + (2000 * 256) = 46226176. This is more than the FD for this route, so R4 will not become a Feasible Successor. But this does not mean that EIGRP will not use this route at all. Just switching to it will take more time (more on this later).
neighborhood
Routers do not talk about routes with just anyone - before they begin to exchange information, they must establish a neighborhood relationship. After the process has been enabled by the router eigrp command, indicating the autonomous system number, we tell the network command which interfaces will be involved at the same time and which networks we want to distribute. Immediately, hello-packets to the multicast address 224.0.0.10 start to be sent through these interfaces (by default, every 5 seconds for ethernet). All routers with EIGRP enabled receive these packets, then each receiving router does the following:
- verifies the address of the sender of the hello packet with the address of the interface from which the packet was received, and verifies that they are from the same subnet
- compares the values of the K-coefficients obtained from the packet (in other words, which variables are used in the calculation of the metric) with its own. It is clear that if they are different, then metrics for routes will be considered according to different rules, which is unacceptable.
- checks the autonomous system number
- optional: if authentication is configured, it checks the compliance of its type and keys.
If the recipient is satisfied with everything, he adds the sender to the list of his neighbors, and sends him (already a unicast) an update-package, which contains a list of all the routes known to him (aka full-update). The sender, having received such a packet, in turn, does the same. For exchanging routes, EIGRP uses the Reliable Transport Protocol (RTP, not to be confused with the Real-time Transport Protocol, which is used in IP-telephony), which implies a delivery confirmation, therefore each of the routers, having received an update package, responds with an ack-packet ( from acknowledgement- confirmation). So, the neighborhood relationship is established, the routers learned from each other comprehensive information about the routes, what next? Then they will continue to send multicast hello-packages to confirm that they are in touch, and in case of a change in the topology, update-packages containing information only about changes (partial update).
Now back to the previous scheme with a modem.

R2 for some reason has lost touch with 192.168.2.0/24. Before this subnet, it has no spare routes (i.e., no FS). Like every responsible router with EIGRP, he wants to reconnect. To do this, he begins to send special messages (query packets) to all his neighbors, who, in turn, not finding the right route for themselves, ask all their neighbors, and so on. When the wave of requests reaches R4, it says “wait a minute, I have a route to this subnet! Bad, but at least something. Everyone forgot about him, but I remember something. ” He packs all this into a reply-packet and sends it to his neighbor, from whom he received the request (query), and further along the chain. Understandably, it all takes more time than just switching to the Feasible Successor, but in the end, we get a connection to the subnet.
But now is a dangerous moment: maybe you have already noticed and are on the alert, having read the moment about this fan mailing list. The fall of one interface causes something similar to a broadcasting storm on the network (not on such a scale, of course, but still), and the more routers it has, the more resources will be spent on all these requests and responses. But this is still half the trouble. The situation is even worse: imagine that the routers shown in the picture are only part of a large and distributed network, i.e. some may be located many thousands of kilometers from our R2, on bad canals, and so on. So, the trouble is that by sending a query to a neighbor, the router must wait for a reply from it. It doesn't matter what the answer is, he must come. Even if the router has already received a positive response, as in our case, it cannot put this route into operation until it receives an answer to all its requests. And requests, maybe somewhere else in Alaska, wander. This state of the route is called stuck-in-active. Here we need to get acquainted with the terms that reflect the state of the route in the EIGRP: active \ passive route. Usually they are misleading. Common sense dictates that active means the route is “active”, enabled, working. However, the opposite is true: passive is “all is well”, and the active state means that this subnet is not available, and the router is actively searching for another route, sending a query and waiting for a reply. So, the stuck-in-active state (stuck in the active state) can last up to 3 minutes! After this period, the router terminates the neighborhood relationship with the neighbor, from which it cannot wait for an answer, and can use the new route through R4. Details about the problem
History, chilling network engineer. 3 minutes downtime is not a joke. How can we avoid a
Generally speaking, there is another way out, and it is called route filtering. But this is such a voluminous topic that a separate article is written under it, and we already have a half-book this time. Therefore, at your discretion.
As we already mentioned, in EIGRP, summation of routes can be performed on any router. To illustrate, imagine that our long-suffering R2 is connected to the subnet from 192.168.0.0/24 to 192.168.7.0/24, which is very handy summed up in 192.168.0.0/21 (remember binary math). The router announces this summary route, and everyone else knows: if the destination address starts at 192.168.0-7, then this is it. What will happen if one of the subnets disappears? The router will send query-packets with the address of this network (specific, for example, 192.168.5.0/24), but the neighbors, instead of continuing the vicious distribution on their own behalf, will immediately send a sobering replay, they say, this is your subnet you and understand.
The second option is the stub configuration. Figuratively speaking, stub means “end of the path”, “dead end” in EIGRP, that is, to get into some subnet that is not connected directly to such a router, you will have to go back. A router configured as a stub will not forward traffic between subnets known to it from EIGRP (in other words, which are marked with the letter D in show ip route). In addition, his neighbors will not send him query packets. The most common use case is hub-and-spoke topologies, especially with redundant links. Let's take such a network: on the left - branches, on the right - the main site, main office, etc. For fault tolerance redundant links. EIGRP launched with default settings.
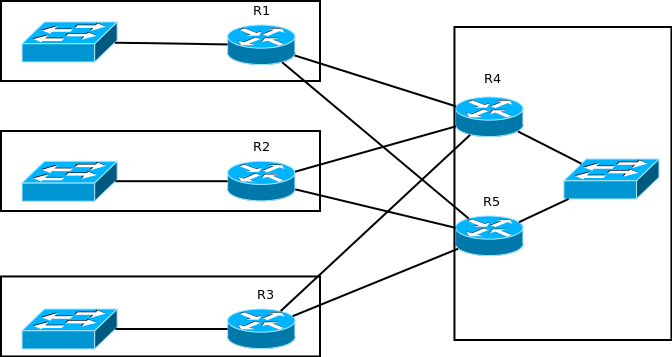
And now “attention, question”: what happens if R1 loses connection with R4 and R5 loses LAN? R1 R1->R5->R2( R3)->R4. ? Not. R1, R2 ( R3), - . - stub. , , “ ”, . stub', , -, “ ”, , -, query- .
stub-, eigrp stub:
R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
By default, if you just give the eigrp stub command, the connected and summary modes are enabled. Of interest is the receive-only mode, in which the router does not announce any networks, only listens to what the neighbors are saying (in the RIP there is a passive interface command that does the same, but in EIGRP it completely disables the protocol on the selected interface, which does not allow set the neighborhood).
Important points in the theory of EIGRP, not included in the article:
- EIGRP can be configured to authenticate neighbors
- Concept graceful shutdown
- Load balancing
EIGRP Practice
“ ” . : , . — — .

— EIGRP . — 10.0.0.0/8. ( , ) , , , — — , IP- 172.16.32.0/20.
:
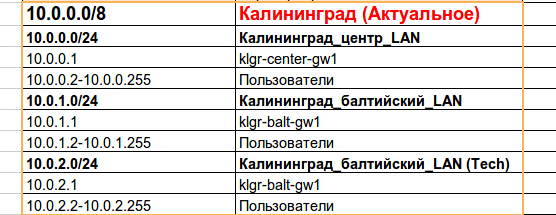

? , :
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
EIGRP , , , (16 B — 172.16.0.0 8 8 — 10.0.0.0)
. router eigrp, №1. ( OSPF).
EIGRP : ( IOS 15).
:
10.0.0.1/24 klgr-center-gw1 :
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
10.0.1.0/24 10.0.2.0/24/
klgr-balt-gw1 10.0.1.0/24 10.0.2.0/24, 10.0.0.0/24 - .
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
10.0.0.0/8 next hop Null0.
klgr-center-gw2 , 10.0.0.0/8 WAN .
D 10.0.0.0/8 [90/30720] via 172.16.2.41, 00:42:49, FastEthernet0 / 1
[90/30720] via 172.16.2.45, 00:38:05, FastEthernet0 / 0
Something very strange is going on.
But, if you check the configuration of this router, you will probably notice:
router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
. EIGRP. , . klgr-center-gw1 klgr-balt-gw1 10.0.0.0/8, , .
, , msk-balt-gw1 10.0.1.0/24 10.0.2.0/24, : 10.0.0.0/8. , msk-balt-gw1 .
, , balt-gw1 10.0.50.243, ? Blackhole-:
10.0.0.0/8 is a summary, 00:42:05, Null0
. .
blackhole- . , … auto-summary.
, EIGRP:
router eigrp 1
no auto-summary
. :
klgr-center-gw1:
10.0.0.0/24 is subnetted, 3 subnets
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw1
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
Task №4Due to the settings of various QoS mechanisms on Kaliningrad routers, the bandwidth value on the interfaces was changed, these values do not correspond to reality now. Therefore, it was decided that it is necessary to change the calculation of the EIGRP metrics on Kaliningrad routers so that only delay is taken into account and does not take into account the interface bandwidth.
Answer
Configuring the transfer of routes between different protocols
: OSPF EIGRP , .
() .
, . msk-arbat-gw1 klgr-balt-gw1. .
EIGRP OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
msk-arbat-gw1:
msk-arbat-gw1 # sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 [110/20] via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0 / 0.3
C 172.16.1.0/24 is directly connected, FastEthernet0 / 0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0 / 1.7
O E2 172.16.2.36/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0 / 1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1 / 0.911
C 172.16.3.0/24 is directly connected, FastEthernet0 / 0.101
C 172.16.4.0/24 is directly connected, FastEthernet0 / 0.102
C 172.16.5.0/24 is directly connected, FastEthernet0 / 0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S * 0.0.0.0/0 [1/0] via 198.51.100.1
, 2 — . 2 — , 2- ( External ), OSPF
OSPF EIGRP. :
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
( ) , .
EX 170, 90 :
klgr-gw2#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [ 170 /33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [ 90 /30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
[90/30720] via 172.16.2.46, 00:38:59, FastEthernet0/1
...
, , — , .
— , . — , .
№5 ( ). 1 .
, 30 , , . , , . , , .
Answer
. , , (, ):
PC>ping linkmeup.ru
Pinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
, spb-ozerki-gw1, spb-vsl-gw1, - , msk-arbat-gw1, .
, :
msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
, .
:
PC>tracert linkmeup.ru
Tracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2
Trace complete.
№6 ( )klgr-balt-gw1 EIGRP OSPF. 20, . , , , .
Answer
1) show ip ospf neighbor
msk-arbat-gw1:
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5
172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7
172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911
2) EIGRP: show ip eigrp neighbors
IP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58
3) show ip protocols .
klgr-balt-gw1:
Routing Protocol is «EIGRP 1 »
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
Routing Information Sources:
Gateway Distance Last Update
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170
Routing Protocol is «OSPF 1»
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4) :
debug ip OSPF events
debug ip OSPF adj
debug EIGRP packets
, , .
№7.
, OSPF.
. , EIGRP OSPF , , , EIGRP.
, , , , , SPF .
The answer is .
IP-,
useful links
XGU.ru
OSPF cisco
Ospf
Inter-domain Routing Loops
Features of the External Type 1 and External Type 2 routes in OSPF. Part 1
Features of the External Type 1 and External Type 2 routes in OSPF. Part 2
Other
Cisco
— linkmeup.ru . , .
— theGluck . JDima , . Antuan . .
PS
. , .
Pps
Packet Tracer . — - . ? IOU vs GNS.
Source: https://habr.com/ru/post/156695/
All Articles