We automate the collection of information about the program crashes.
Paraphrasing the well-known proverb: "he who does not code anything does not make any bugs." Each developer is able and likes to make bugs, but does not like to correct them later. Errors in the code in one case simply lead to incorrect data processing by the program, and in the other - to exceptions (departures, crashes, crashes). In this post I will talk about how you can automate the collection of data on the crash of the program, to greatly facilitate your life when parsing and eliminating errors.
Do you know what reaction I saw when I told a friend that I wanted to use a library in the project that automates the collection of error data? I literally heard the following: “Why does someone need such a complex system? Look, if something happens to me in the program, then the users write me a letter, which buttons they pressed and what they did. And then I reproduce the error and correct it. "
')
Yes, programmers are lazy. We want to convince ourselves that correct the errors found by the user, it is good at us and manually. In the same way, we convince ourselves that it is realistic to write high-quality code even without unit tests, and even without fixing the warnings that the compiler rolls when building a project. All the same, the customer needs to “be ready quickly,” and all errors will be identified and eliminated sometime later. Vaughn testers are sitting, let them catch bugs. There is always not enough time, deadlines are under pressure, the administration does not approve any “extra bells and whistles”.
Practice shows that such projects may be carried out in record time, and maybe most of the errors are caught by testers, but, nevertheless, after the release, users massively send letters to the support and complain about exceptions in the program. With the passage of time, the absence of a coherent architecture, comments on the code, unit tests and the like also makes itself felt. Each developer who makes changes to someone else's code generates new bugs and potential for exceptions, some of which are again caught by testers, and some of them are being released.
What do I usually do when a user sends an email asking for help?
When a user sends a letter to us to support, saying that a critical error occurs in our program installed on his machine, I usually ask the support to find out what version of the application he has and the version of the operating system. Because the software environment of the user's system is very important for identifying the causes of the error.
Firstly, I have to communicate with the user through an intermediary (support), who still needs to explain what I want, and secondly, I have to apply for technical information to a user who may be, and only knows how to turn on the computer and run office. Most of the users with whom I spoke, no offense to them will be told, can not express their thoughts and do not know the technical terms. They can not explain how to change such a registry key and see the file in a hidden folder LocalAppData.
When a user answers my request, I almost always have additional questions: “but try pressing such a button and changing such an option”. In response, I receive silence. The user simply does not have the patience to do this several times, until I get him all the information I need.
In my projects, regardless of the fact that this is a service or application with a window interface - I keep logs. In the log, I write error messages and current operations. The log file in theory should help get from the user the technical information about the application that the user does not know, and can not know.
When an error occurs in an application, I request a log file from the user. This is where the problems begin. It turns out that explaining to the user exactly where to get the log file and at what point in time he should get it is a non-trivial problem. Often, the user restarts the application after the error has occurred, after which the log file is overwritten and came to me empty, causing my bewilderment.
In general, when parsing a bug, my main goal is to reproduce this bug in my car. This will allow me to fix it. From the words of the user it is rarely clear how he makes the application fall, how does he manage to raise an exception in the application? It is difficult to answer this question, having only a bunch of text in the log before your eyes.
Therefore, the next step in my communication with the user is asking him to take a screenshot or record a video in which he would show his actions, how he achieves an error in the application. Think a lot of users send me a video? No, but, nevertheless, I met such craftsmen. And such a video was sometimes the most useful thing to reproduce the error.
So, the main disadvantage of manual data collection about a critical error in the application is that the user is lazy and tongue-tied. He will not test your hypotheses to establish the cause of the error — he has no desire, patience or technical knowledge to do this.

How, after all, it is better to collect information about the error - manually or automatically?
The idea of automatically collecting and delivering error reports appeared in Microsoft in the early 2000s [1], when they were puzzled by a hail of errors that occur in numerous products (including Windows and Office). The Windows development team developed a tool that allowed you to make a core dump of the system, which could then be analyzed.
Regardless, the Office development team created a tool that could catch unhandled exceptions and create minidumps . The minidump, in contrast to the dump, contained only small fragments of the virtual memory of the process, necessary to read a snapshot of the stack of the thread in which the exception occurred. The minidump was very convenient because it can be automatically sent over the Internet.
This development was called Windows Error Reporting (WER) and implemented in Windows XP. Since then, all Microsoft products have been catching WER errors. There are the following statistics [2] on the effectiveness of using WER in Microsoft products:
- correction of 20 percent of the "top" detected errors can solve 80 percent of customer problems;
- correcting the cause of only 1 percent of errors, you can fix 50 percent of customer problems.
Any developer can use WER to automate the collection of error data in their application. WER sends an error report to the Microsoft server, and the developer can access this server "for free". But for this you need to have a VeriSign certificate. Buying such a certificate costs from $ 500 a year. In fact, if you are developing for Windows, then you need to buy a certificate, so we assume that you can get access to the WER server for free.
In addition to WER, there are other free libraries for collecting data about program crashes. For example, in my C ++ projects under Windows, I use an open source library called CrashRpt [3]. I can advise Linux users to use breakpad [4], an open library of Google.
Personally, I prefer CrashRpt, because I write only under Windows. In addition, this library allows you to send error reporting files not only to the server via HTTP, but also as a letter to my mailbox, which is more convenient for me. Then I will tell you what else this library can do.
What error data can I collect automatically?
So, an exception occurred in the application. An exception can be triggered by many reasons: addressing at zero address in memory, stack overflow, memory exhaustion, and so on. In MSDN, you can find about a dozen functions that C run-time provides for intercepting (processing) exceptions. These functions and uses the library CrashRpt.
When an exception occurs, the CrashRpt handler is started, which, first of all, saves the exception pointers (this is the structure containing the address of the exception, its code and type). Next, CrashRpt launches a new process and passes exception pointers to it. The parent application in which the exception occurred may be unstable, and it is eliminated as soon as all error data is retrieved.

Minidamp
In the new process, and the main work is going on collecting data about the error.
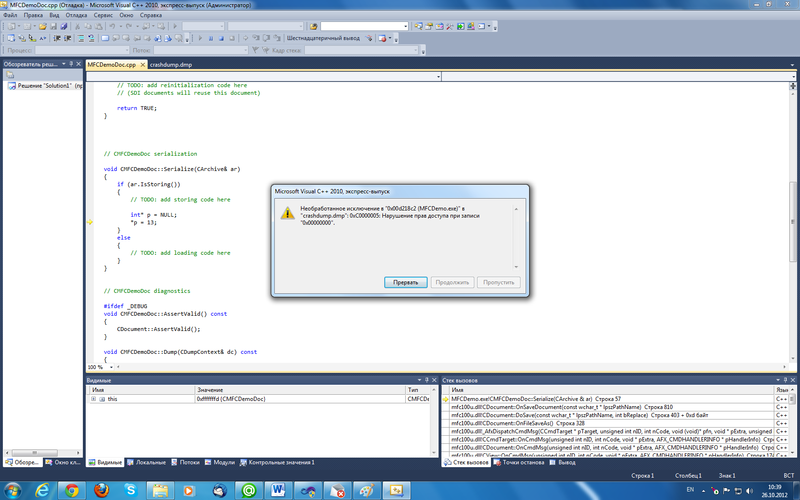
First, minidump is recorded using Microsoft's dbghelp.dll system library. To do this, all threads of the parent process are suspended, and the snapshot of the process is done. The names and versions of all DLL-modules loaded in the process are recorded. The identifiers of the threads that worked in the process are saved. For each thread, a stack snapshot is recorded. Also in minidump information about the version of the operating system, the number of CPUs and their brand is stored. Minidump weighs about several tens of kilobytes.
After we received the minidump file, we can open it in the Visual Studio environment and visually see the program status at the time of crash: determine the application version, operating system version and see the place in the code where the exception occurred (see figure below). Does truth make life easier?
Logs
Automating the collection of information about the program crashes does not force us to abandon the usual logs. We can, as before, record the current operations in the log, and when it is more beautiful, the log will automatically be added to the error report. This eliminates misunderstandings that might have occurred earlier with the “manual” log requests from the user. Now the log will always contain actual data at the time of the program crash, and the user will not have to explain how to open the hidden LocalAppData folder and which file to take from there.
In addition to logs, we can add to the error report and any other files that we wish.
Screenshots
What I don't like about minidumps and logs is that they often do not allow to reproduce the error. Yes, I can see the place in the program where the crash occurred, and I can build a hypothesis from which it could occur. For example, crashes often occur when a variable is not initialized, and a garbage address is addressed in memory.
But, as I fought, in most cases I will not be able to pick up actions that allow me to reproduce the crash on my machine. The point is not only that each user has his own unique software environment, different from the environment of my machine. The point is that users have their own patterns of work with your program. The way you use the program, what actions you perform with it, may be completely different from what the user does.
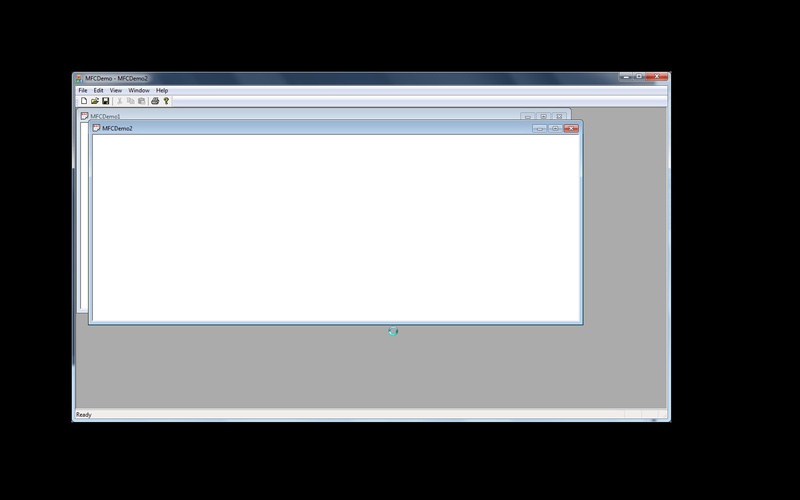
Therefore, a very useful information about the error is a screenshot of the user's screen at the time of the crash. The CrashRpt library allows you to automatically create such a screenshot, saving it in JPEG format (compression quality can be customized) or PNG. As a result, I can see which button the user pressed at the time of the error, which, believe me, helps a lot in reproducing the error.
In the figure below, I gave an example of a screenshot taken at the time of the crash of the application. The screenshot contains only the application window area, the remaining areas are automatically filled with black (we protect the user's privacy).
Videos
Remember, I said that a couple of times users sent me videos showing actions that they did immediately before the program crashed? So, with the library CrashRpt you do not have to beg the user to make a movie. The library itself will make them (with the consent of the user, of course).
It is clear that it is impossible to predict when a crash will occur. Therefore, CrashRpt periodically (at intervals that you specify) takes screenshots of the screen and saves them to disk in uncompressed form (like BMP files). When accumulating screenshots, old ones are deleted, and new ones take their place. In tests on my machine, it takes about 5-7% of CPU resources and several hundred megabytes of disk.
If an exception occurs, the recorded screenshots are compressed with the OGG Theora [5] codec, and a video file is obtained that can be opened in Chrome or Firefox, or in any video player.
Yes, the video recording operation is quite resource-intensive, but it is not necessary to always include it. You can, for example, enable it only if the proceedings with the user are at a deadlock, and the last opportunity to reproduce the error remains - to make a video.
Conclusion
I do not argue, you can fix bugs in the program that lead to crashes without automating the collection of error data. But automation allows you to do it really effectively. It makes life easier for the developer. And not only after the release. For example, we use automation even in the early stages of the beta testing program to make it easier for us to communicate with testers, who, after all (no offense to them will be told), do not always understand how to take a screenshot or record a video clip.
By the way, do you know what is the shortest falling program in C [6]?
main(){main();} Links
- Kirk Glerum et al. Debugging in the (Very) Large: Ten Years of Implementation and Experience. Proceedings of the 22nd ACM Symposium on Operating Systems Principles (SOSP '09), 2009.
- Windows Error Reporting: Getting Started , MSDN
- CrashRpt - a crash reporting system for Windows applications. Google Project Hosting.
- breakpad - crash reporting. Google Project Hosting.
- Theora video compression
- The shortest "falling" program on C , RSDN Forums
Source: https://habr.com/ru/post/156255/
All Articles