Machine translation and automatic dictionary in Yandex
Each large product includes many complex and interesting technologies that people, often devoting their whole life to them, worked on. And Yandex has implemented many of our colleagues' developments, which may remain unnoticed by non-specialists and appear to be insignificant details. For example, one of the cloud technologies of Yandex, which are integrated into the browser, has become our own translator.
Yandex.Transfer itself came out of beta a few months ago. It is distinguished from other few similar services by its auto dictionary, the unique technology of which was developed by a team of linguists and programmers of Yandex. During its development, it was possible to combine modern statistical approaches of machine translation and traditional linguistic tools.
')
To understand how important a step in the development of machine translation is the appearance of an autos-dictionary, it is worth remembering that syntax translators were distributed 20 years ago, for which phrase matching tables in different languages were compiled manually. The process of their creation began to change only in the late 1990s, when the first statistical translators appeared. Parallel texts were used to teach their translation models. Documents in which the same thing is written in different languages have been extracted, for example, from diplomatic documentation. A large base of parallel texts became UN documents. But it was impossible to create a general translator in such a lexicon, because he translated even informal texts in a dry diplomatic language.
The solution to the problem of learning a universal translation model was the use of parallel documents extracted from search engine indices. And these are not only multilingual sites that were originally created in several languages. For example, a document appeared on the Internet with text about some event. For him, a kind of “passport” is created with characteristic (contrasting) words, which is then compared with passports of other documents, and if they coincide, it is concluded that this is a text about the same, but in different languages. This process requires significant computational resources because it has to process billions of web documents.
Naturally, not all sentences in such texts will be consecutive translations of each other. In order to create correspondence tables of words and phrases with all possible translations, you need to do a special alignment and throw out those that accidentally got there. As a result, it turns out that, for example, 20–30 English correspond to each Russian word.
Virtually the entire process described above is based on statistical methods and probability theory. An automatic translator knows the magnitude of the probability of each translation and, based on it, quickly makes his choice on the language model from dozens of options, and sometimes hundreds.
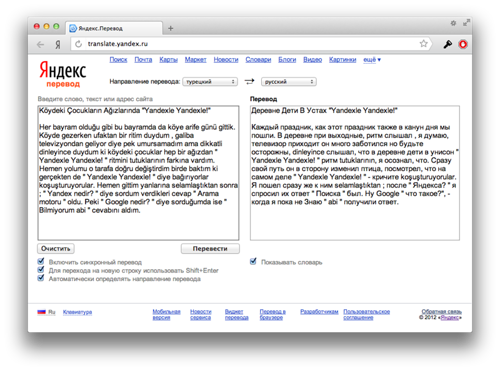
It seems that for the accuracy of the translation and the accounting of the text stylistics, you only need to show the variants of the translations to the person and he will select the word that is most suitable for the context and style. But these are statistical fragments of the text, which in themselves can not carry any meaning for a simple user. At least, because he can see thousands of options for one word, which does not help him. Especially if the person does not know very well the language into which he translates.
An autoscript solves the problem of choice by choosing only the most suitable translations and showing them in a form that is readable for the simple user. To this end, our team of specialists carried out complex and resource-intensive work. First, we made the auto dictionary display the dictionary form of the word. Secondly, they taught us to identify from the entire set of phrases really stable phrases that a person can then formulate.
There are other difficulties in compiling an automatic dictionary. For example, when a user requests a word to be translated without a context, then in order to group variations in another language, one has to display all its meanings. And often in a language that is unfamiliar to him. To help a person navigate through the translation options, you need not only to show all the main meanings of a word, but also to group them by their meanings.
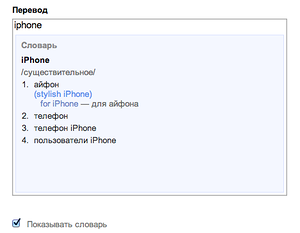 For this, a dictionary of synonyms is used, which is also based on the statistical data accumulated by us in the process of building a translation model. Due to the fact that there are both directions of translation in Yandex.Translate, we know that different words of one language often translate into the same word of another language. This suggests that they are synonymous. Thus, we automatically form groups of translations, each of which has its own meaning.
For this, a dictionary of synonyms is used, which is also based on the statistical data accumulated by us in the process of building a translation model. Due to the fact that there are both directions of translation in Yandex.Translate, we know that different words of one language often translate into the same word of another language. This suggests that they are synonymous. Thus, we automatically form groups of translations, each of which has its own meaning.
As a result, the Yandex.Translate user does not need to additionally view articles from ordinary dictionaries in order to select a more accurate translation. An autoscript will show him an automatically generated article in which there will even be examples of the use of the word. In addition, based on statistics of word usage on the Internet, the automatic dictionary is updated faster. Thanks to all this, translations made with the help of a Yandex machine translator will be much better.
Yandex.Transfer itself came out of beta a few months ago. It is distinguished from other few similar services by its auto dictionary, the unique technology of which was developed by a team of linguists and programmers of Yandex. During its development, it was possible to combine modern statistical approaches of machine translation and traditional linguistic tools.
')
To understand how important a step in the development of machine translation is the appearance of an autos-dictionary, it is worth remembering that syntax translators were distributed 20 years ago, for which phrase matching tables in different languages were compiled manually. The process of their creation began to change only in the late 1990s, when the first statistical translators appeared. Parallel texts were used to teach their translation models. Documents in which the same thing is written in different languages have been extracted, for example, from diplomatic documentation. A large base of parallel texts became UN documents. But it was impossible to create a general translator in such a lexicon, because he translated even informal texts in a dry diplomatic language.
The solution to the problem of learning a universal translation model was the use of parallel documents extracted from search engine indices. And these are not only multilingual sites that were originally created in several languages. For example, a document appeared on the Internet with text about some event. For him, a kind of “passport” is created with characteristic (contrasting) words, which is then compared with passports of other documents, and if they coincide, it is concluded that this is a text about the same, but in different languages. This process requires significant computational resources because it has to process billions of web documents.
Naturally, not all sentences in such texts will be consecutive translations of each other. In order to create correspondence tables of words and phrases with all possible translations, you need to do a special alignment and throw out those that accidentally got there. As a result, it turns out that, for example, 20–30 English correspond to each Russian word.
Virtually the entire process described above is based on statistical methods and probability theory. An automatic translator knows the magnitude of the probability of each translation and, based on it, quickly makes his choice on the language model from dozens of options, and sometimes hundreds.
It seems that for the accuracy of the translation and the accounting of the text stylistics, you only need to show the variants of the translations to the person and he will select the word that is most suitable for the context and style. But these are statistical fragments of the text, which in themselves can not carry any meaning for a simple user. At least, because he can see thousands of options for one word, which does not help him. Especially if the person does not know very well the language into which he translates.
An autoscript solves the problem of choice by choosing only the most suitable translations and showing them in a form that is readable for the simple user. To this end, our team of specialists carried out complex and resource-intensive work. First, we made the auto dictionary display the dictionary form of the word. Secondly, they taught us to identify from the entire set of phrases really stable phrases that a person can then formulate.
There are other difficulties in compiling an automatic dictionary. For example, when a user requests a word to be translated without a context, then in order to group variations in another language, one has to display all its meanings. And often in a language that is unfamiliar to him. To help a person navigate through the translation options, you need not only to show all the main meanings of a word, but also to group them by their meanings.
For this, a dictionary of synonyms is used, which is also based on the statistical data accumulated by us in the process of building a translation model. Due to the fact that there are both directions of translation in Yandex.Translate, we know that different words of one language often translate into the same word of another language. This suggests that they are synonymous. Thus, we automatically form groups of translations, each of which has its own meaning.As a result, the Yandex.Translate user does not need to additionally view articles from ordinary dictionaries in order to select a more accurate translation. An autoscript will show him an automatically generated article in which there will even be examples of the use of the word. In addition, based on statistics of word usage on the Internet, the automatic dictionary is updated faster. Thanks to all this, translations made with the help of a Yandex machine translator will be much better.
Source: https://habr.com/ru/post/156187/
All Articles