ConcurrentDictionary as a cache
 Many developers often face a dilemma - to receive data only from the database or to keep the cache for a number of tables. Basically, these are some reference books that contain few records and are always needed at hand. This holivarny question will not be addressed in this article.
Many developers often face a dilemma - to receive data only from the database or to keep the cache for a number of tables. Basically, these are some reference books that contain few records and are always needed at hand. This holivarny question will not be addressed in this article.The same problem arose in front of me when designing a high-loaded transport monitoring system server on .NET. In the end, it was decided that the caches - to be. Dictionary caches were stored in wrappers over ConcurrentDictionary. This option was taken without much research, as it is the standard .NET tool for thread-safe dictionaries. Now it's time to check the performance of this solution. About this, in fact, the article. Also at the end of the article there will be a small study of how the ConcurrentDictionary is arranged.
')
Formulation of the problem
A thread-safe collection of key-value pairs that can do the following is required:
- An object request by key-identifier is, of course, used most often;
- Changing, deleting and adding new elements is rare, but it is necessary to ensure thread safety;
- Work with values - request of all values, search by properties of the value object.
Point 3 is not typical for collections of dictionaries and therefore is the main brake on this design. However, if caching of reference tables is used, such situations are inevitable (for example, it would be trite to display the entire dictionary in the admin panel for editing).
Let's try to consider the different systems in which the cache will be used. They will differ in the frequency of dictionary operations. We formalize the types of these operations:
- GET - request object by key,
- ADD - adding a new object by a new key (if such a key already exists, overwrite it),
- UPDATE - the new value for the existing key (if there is no key, we do nothing)
- SEARCH - work with an iterator, in this case - search for the first suitable value
List of test participants
- ConcurrentDictionary . This is a turnkey solution from Microsoft with built-in thread safety. Implements convenient TryGetValue, TryAdd, TryUpdate, AddOrUpdate, TryDelete methods that allow you to conveniently set a conflict resolution policy. Features of implementation will be discussed at the end of the article.
- Dictionary with blocking via Monitor . The most that there is no solution to the forehead - all non-thread-safe operations are wrapped in a lock construct.
- Dictionary with blocking through ReaderWriterLock . Optimization of the previous solution - operations are divided into read and write operations. Accordingly, several streams can be read simultaneously, and exclusive access is required for writing.
- Dictionary with blocking through ReaderWriterLockSlim . In essence, the same, but using a newer class (recursion control settings added). In the context of this task, it is unlikely that something different from ReaderWriterLock should be shown.
- Dictionary with blocking via OneManyResourceLocker from Wintellect's PowerThreading library is a tricky implementation of Jeff Richter's ReaderWriterLock. I’ll clarify that the version from the official site was used, not the NuGet package - the version is different there and I didn’t like it.
- Hashtable.Synchronized . Too ready solution from Microsoft - provides a thread-safe indexer. It is inconvenient to use due to the fact that it is a non-generic collection (boxing, readability is worse), and there are no methods with the Try prefix (it is impossible to establish a policy of simultaneous addition / update).
Briefly tell you exactly how handlers are implemented.
- GET operation : all participants use the thread safe TryGetValue method from the IDictionary. For Hashtable, an index with a type cast is used.
- ADD operation: for ConcurrentDictionary - AddOrUpdate, for Dictionary - write lock and add via indexer, for Hashtable - add via indexer without lock.
- UPDATE operation: for ConcurrentDictionary — TryGetValue first, then TryUpdate.
This method is interesting in that a parallel update can occur between these two methods (which was what manifested itself during testing). It is for this case that OldValue is passed to TryUpdate so that in this rare case rewriting fails. For Dictionary, we check for availability through ContainsKey and, if successful, put a lock on the record and overwrite the value. There is no convenient TryUpdate for Hashtable, so I didn’t bother checking the key and, as in the case of adding, the value is overwritten through the indexer (for this collection it doesn’t matter - it was still pretty bad). - Operation SEARCH : LINOs FirstOrDefault is used for ConcurrentDictionary, for the rest, the read lock and the same FirstOrDefault is used.
Test stand
A console application has been created for testing ( link ).
- A set of handlers is created that can handle operations of all defined types;
- A dictionary of N elements is created (10 000 by default);
- Creates a collection of tasks of different types in the amount of M (10,000 by default);
- Each processor handles parallel processing of all tasks using the generated dictionary (common for all processors);
- The experience (points 2-4) is carried out a specified number of times (10 by default) and the resulting time is averaged. Measurements were made on a machine with a Core 2 Quad 2.66GHz and 8GB of memory.
The default values are quite small, however, if you increase them, nothing fundamentally changes.
Test results
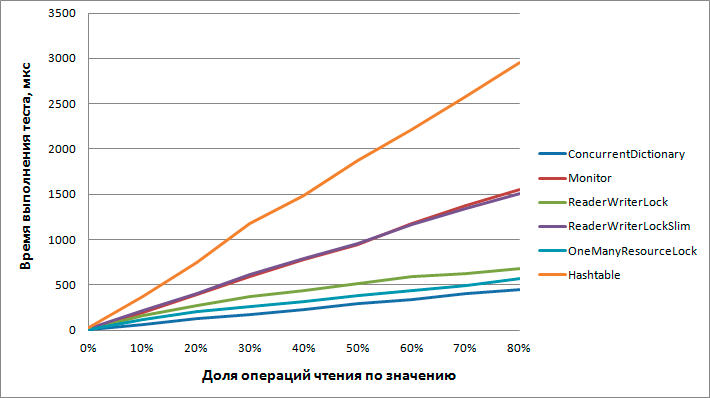
Testing was carried out with different distribution options for the types of operations and the table turned out to be too large, you can see it in its entirety here ( link ). For clarity, I will give a graph of the test run time in microseconds depending on the percentage of reading by value of the total number of operations (20% of the write operations are fixed, the rest are read by key).
findings
The performance of all participants falls linearly on the number of reads by value, regardless of the number of write operations.
- ConcurrentDictionary . Experiments have shown that this tool is best suited for this task. Reading by value significantly beats the performance, but it still remains faster than the other participants.
- Dictionary + Monitor . Significantly slower, expected results.
- Dictionary + ReaderWriterLock . Optimization of the previous version, everything is also expected.
It should be noted that the more write operations prevail - the smaller the difference. From a certain point on, the Monitor becomes even more preferable due to the lower overhead of the blocking process itself. - Dictionary + ReaderWriterLockSlim . For some reason, he managed to lose even a simple monitor. Either the extended functionality (compared to the previous version) affected the performance, or I do not know how to cook it.
- Dictionary + OneManyResourceLock . Richter seems to have squeezed everything out of the read / write lock. According to test results, this is the fastest use of the Dictionary But ConcurrentDictionary is still faster.
- Hashtable . Expected failure. Perhaps I used it incorrectly, but I do not think that it was possible to get a result comparable with other participants. And generally it’s somehow sad to work with non-generic collections.
Inside the ConcurrentDictionary
Let's take a closer look at the winner in more detail, namely: let's look at the sources of ConcurrentDictionary.
At creation of this class 2 parameters are set: Capacity and ConcurrencyLevel . The first ( Capacity ) is customary for collections and sets the number of elements that can be written without expanding the internal collections. In this case, linked lists are created (m_buckets, therefore we will call them baskets (well, not buckets, yes?)) In the number of Capacity, and then the elements are added relatively evenly to them. The default value is 31.
The second parameter ( ConcurrencyLevel ) determines the number of threads that can simultaneously write to our dictionary. This is accomplished by creating a collection of objects for blocking by monitors. Each such blocking object is responsible for approximately the same number of baskets. The default is Environment.ProcessorCount * 4.
Thus, each object in the dictionary is uniquely associated with a basket, where it lies, and the blocking object for writing. This is done by the following method:
/// <summary> /// Computes the bucket and lock number for a particular key. /// </summary> private void GetBucketAndLockNo( int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount) { bucketNo = (hashcode & 0x7fffffff) % bucketCount; lockNo = bucketNo % lockCount; Assert(bucketNo >= 0 && bucketNo < bucketCount); Assert(lockNo >= 0 && lockNo < lockCount); } Curiously, even with ConcurrencyLevel = 1, the ConcurrentDictionary still works faster than a regular lock dictionary. It is also worth noting that the class is optimized for use through an iterator (as shown by tests). In particular, when calling the ToArray () method, locking is performed on all baskets, and the iterator is used relatively cheaply.
For example: it’s better to use dictionary.Select (x => x.Value) .ToArray () than dictionary.Values.ToArray ().
The article is written by the leading developer of the company.
Thanks for attention!
Source: https://habr.com/ru/post/156125/
All Articles