Demonstration of program crashes in the absence of memory barriers
Jeff Preshing has published an excellent demonstration of how normal C ++ code returns an unpredictable result on multi-core processors with Weakly-Ordered CPU, that is, on ARM processors. For example, on the iPhone or some modern Android device.
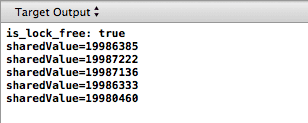
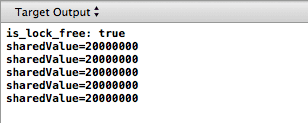
A simple C ++ program with two threads 20.000.000 times adds one to the value protected by the mutex - and each time the output results in a different result, which is less than 20.000.000!
')
As they say, our enemy is the CPU .
In his blog, Jeff Preshing has published many articles about lock-free programming, methods of non-blocking thread synchronization. He also talked a lot about using double-check locking and the need to set memory barriers. Now Jeff decided that one demonstration is better than a thousand words.
The code of the demo program in which each of the two streams adds 10,000,000 times one to the total value of the
Here's what a homemade mutex looks like: the simplest semaphore that takes the value 1 if it is busy, or 0 if it is free.
The use of the
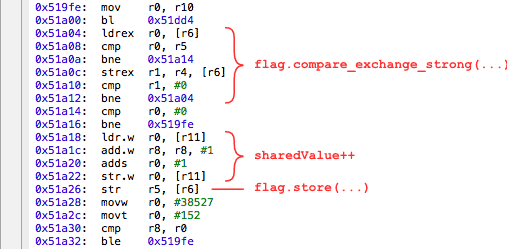
In his program, Jeff deliberately removed the
This is what Xcode generates.
The result of the launch of the program on the iPhone has already been shown.
Why is this happening? The fact is that processors with a Weakly-Ordered CPU can optimize the request queue, so your instructions will not be executed in the order in which you thought. For example, the diagram shows how the two threads from the above example on different CPUs use a common mutex to change the value of
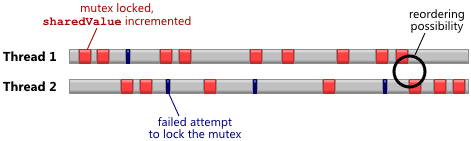
Successful attempts to block the mutex and change the value are shown in red, and black strokes are unsuccessful attempts to access a mutex that is blocked by another thread. The moment when one thread only freed the mutex, and the second is ready to block it, this moment is best suited for reordering the request queue, in terms of the CPU.
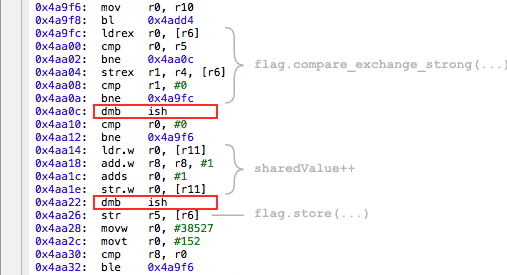
Why the CPU reorders the request queue is the topic of a separate article. You need to deal with this by installing memory barriers that separate a pair of adjacent instructions and ensure that they do not change places. This is what the
The compiler in this case inserts
And then the mutex is already beginning to perform its work normally and reliably protect the shared value of
We are now faced with the massive use of Weakly-Ordered processors. Previously, they were used only in servers or in high-performance "poppies" of the past, where there were multi-core PowerPCs. Now multi-core ARM - in every mobile phone. So this nuance needs to be considered when developing mobile applications.
In the “specially buggy” Preshing code, the probability of an error is 1 in 1000, and in a normal program it will be 1 in 1.000.000, that is, such glitches are extremely difficult to catch during testing. The program can work perfectly 999.999 times, and the next time it starts it will crash.
A simple C ++ program with two threads 20.000.000 times adds one to the value protected by the mutex - and each time the output results in a different result, which is less than 20.000.000!
')
As they say, our enemy is the CPU .
In his blog, Jeff Preshing has published many articles about lock-free programming, methods of non-blocking thread synchronization. He also talked a lot about using double-check locking and the need to set memory barriers. Now Jeff decided that one demonstration is better than a thousand words.
The code of the demo program in which each of the two streams adds 10,000,000 times one to the total value of the
sharedValue protected by the mutex.Here's what a homemade mutex looks like: the simplest semaphore that takes the value 1 if it is busy, or 0 if it is free.
int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // The lock succeeded } The use of the
memory_order_acquire and memory_order_release arguments may seem unnecessary to someone, but it is a necessary guarantee that a pair of threads change the semaphore value in a coordinated way. flag.store(0, memory_order_release); In his program, Jeff deliberately removed the
memory_order_acquire and memory_order_release to demonstrate what this might lead to: void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_relaxed)) { // Lock was successful sharedValue++; flag.store(0, memory_order_relaxed); count++; } } } This is what Xcode generates.
The result of the launch of the program on the iPhone has already been shown.
Why is this happening? The fact is that processors with a Weakly-Ordered CPU can optimize the request queue, so your instructions will not be executed in the order in which you thought. For example, the diagram shows how the two threads from the above example on different CPUs use a common mutex to change the value of
sharedValue .Successful attempts to block the mutex and change the value are shown in red, and black strokes are unsuccessful attempts to access a mutex that is blocked by another thread. The moment when one thread only freed the mutex, and the second is ready to block it, this moment is best suited for reordering the request queue, in terms of the CPU.
Why the CPU reorders the request queue is the topic of a separate article. You need to deal with this by installing memory barriers that separate a pair of adjacent instructions and ensure that they do not change places. This is what the
memory_order_acquire and memory_order_release arguments are for. We return them to the place. void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // Lock was successful sharedValue++; flag.store(0, memory_order_release); count++; } } } The compiler in this case inserts
dmb ish instructions that act as memory barriers in ARMv7.And then the mutex is already beginning to perform its work normally and reliably protect the shared value of
sharedValue .We are now faced with the massive use of Weakly-Ordered processors. Previously, they were used only in servers or in high-performance "poppies" of the past, where there were multi-core PowerPCs. Now multi-core ARM - in every mobile phone. So this nuance needs to be considered when developing mobile applications.
In the “specially buggy” Preshing code, the probability of an error is 1 in 1000, and in a normal program it will be 1 in 1.000.000, that is, such glitches are extremely difficult to catch during testing. The program can work perfectly 999.999 times, and the next time it starts it will crash.
Source: https://habr.com/ru/post/155507/
All Articles