How does apache cassandra work?

In this topic, I would like to talk about how Cassandra ( cassandra ) is organized — a decentralized, fault-tolerant, and reliable key-value database. The storage itself will take care of the problems of single point of failure , server failure and data distribution between cluster nodes . Moreover, both in the case of servers in a single data center ( data center ), and in a configuration with many data centers separated by distances and, accordingly, network delays. Reliability is understood as total data consistency ( eventual consistency ) of data with the ability to set the level of data consistency ( tune consistency ) of each request.
NoSQL databases generally require a greater understanding of their internal structure than SQL . This article will describe the basic structure, and in the following articles you can consider: CQL and programming interface; engineering and optimization techniques; features of clusters located in many data centers.
Data model
In the terminology of cassandra, the application works with the keyspace , which corresponds to the concept of a database schema in the relational model. In this key space there can be several column families ( column family ), which corresponds to the concept of a relational table. In turn, column families contain columns ( column ), which are combined with a key ( row key ) in a record ( row ). A column consists of three parts: a name ( column name ), a timestamp, and a value . The columns within the record are ordered. Unlike a relational database, there are no restrictions on whether the records (and in terms of the database, these are lines) contain columns with the same names as in other records — no. Column families can be of several types, but in this article we will omit this detail. Also in the latest versions of Cassandra, it became possible to perform queries for defining and modifying data ( DDL , DML ) using the CQL language, as well as creating secondary indices ( secondary indices ).
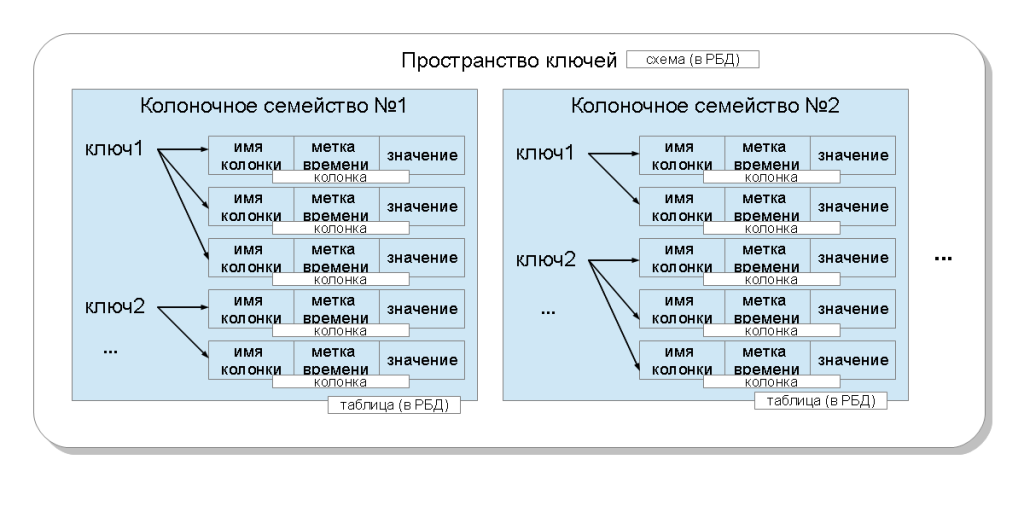
The specific value stored in the cassandra is identified by:
- key space is a binding to an application (subject area). Allows you to place data from different applications on one cluster;
- column family is a binding to the query;
- the key is binding to the cluster node. The key depends on which nodes will get saved columns;
- column name is a binding to an attribute in an entry. Allows you to store multiple values in one record.
')
Each value is associated with a time stamp — a user-defined number that is used to resolve conflicts during recording: the larger the number, the newer the column is considered, and it compares the old columns when comparing.
By data type: key space and column family are strings (names); The time stamp is a 64-bit number; and the key, column name, and column value are an array of bytes. Also, cassandra has the concept of data types ( data type ). These types can be optionally specified by the developer (optional) when creating a column family. For column names, this is called a comparator , for values and keys, a validator . The first determines which byte values are valid for column names and how to arrange them. The second is which byte values are valid for the values of columns and keys. If these data types are not specified, the cassandra stores the values and compares them as byte strings ( BytesType ) since, in fact, they are stored internally.
Data types are as follows:
- BytesType: any byte strings (without validation)
- AsciiType: ASCII string
- UTF8Type: UTF-8 string
- IntegerType: a number with an arbitrary size
- Int32Type: 4-byte number
- LongType: 8-byte number
- UUIDType: UUID of the 1st or 4th type
- TimeUUIDType: Type 1 UUID
- DateType: 8-byte timestamp value
- BooleanType: two values: true = 1 or false = 0
- FloatType: 4-byte floating point number
- DoubleType: 8-byte floating point number
- DecimalType: a number with an arbitrary size and a floating point
- CounterColumnType: 8-byte counter
In cassandra, all data writing operations are always rewriting operations, that is, if a column with the same key and name already exists in the column family, and the time stamp is greater than the one that is saved, the value is overwritten. The recorded values never change, they just come in newer columns with new values.
Writing to a cassandra works at a faster rate than reading. This changes the approach that is used in the design. If we consider cassandra from the point of view of designing a data model, then it is easier to imagine the column family not as a table, but as a materialized view ( materialized view ) - a structure that represents data of some complex query, but stores it on disk. Instead of trying to somehow compile the data using queries, it is better to try to keep everything in the finite family that may be needed for this query. That is, it is necessary to approach not from the side of relations between entities or relations between objects, but from the side of requests: which fields are required to choose; in what order the records should go; what data related to the main ones should be requested together - all this should already be stored in the column family. The number of columns in the record is theoretically limited to 2 billion. This is a brief digression, and in more detail - in the article on design and optimization techniques. And now let's delve into the process of storing data in Cassandra and reading them.
Data distribution
Consider how data is distributed, depending on the key across cluster nodes ( cluster nodes ). Cassandra allows you to set a data distribution strategy. The first such strategy distributes data depending on the md5 key value - a random partitioner . The second takes into account the bit representation of the key itself - a byte-ordered partitioner . The first strategy, for the most part, provides more benefits, since you do not need to worry about evenly distributing data between servers and similar problems. The second strategy is used in rare cases, for example, if range queries are necessary. It is important to note that the choice of this strategy is made before the cluster is created and, in fact, cannot be changed without a full data reload.
Cassandra uses a technique known as consistent hashing to distribute the data. This approach allows you to distribute data between nodes and make it so that when adding and deleting a new node, the amount of data being sent was small. For this, each node is assigned a label ( token ), which breaks into pieces the set of all md5 key values. Since in most cases the RandomPartitioner is used, consider it. As I said, the RandomPartitioner calculates a 128-bit md5 for each key. To determine in which nodes the data will be stored, all the labels of nodes from the smallest to the largest are sorted, and when the value of the label becomes greater than the md5 value of the key, then this node along with some number of subsequent nodes (in the order of labels) is selected for saving. The total number of nodes selected must be equal to the replication factor . The replication level is set for each key space and allows you to adjust data redundancy .
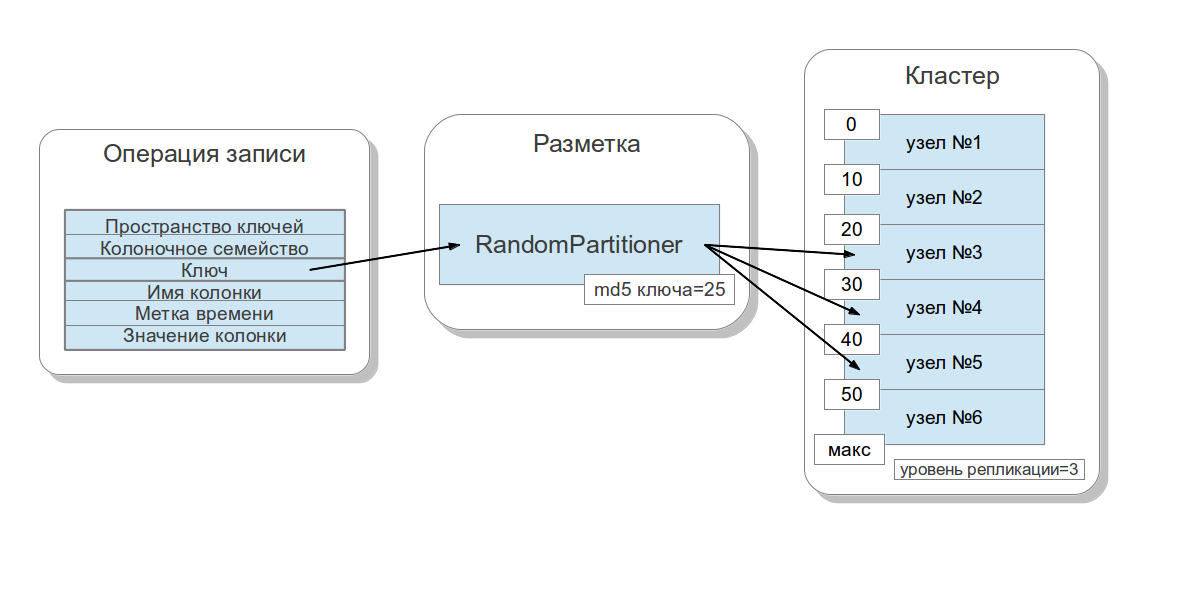
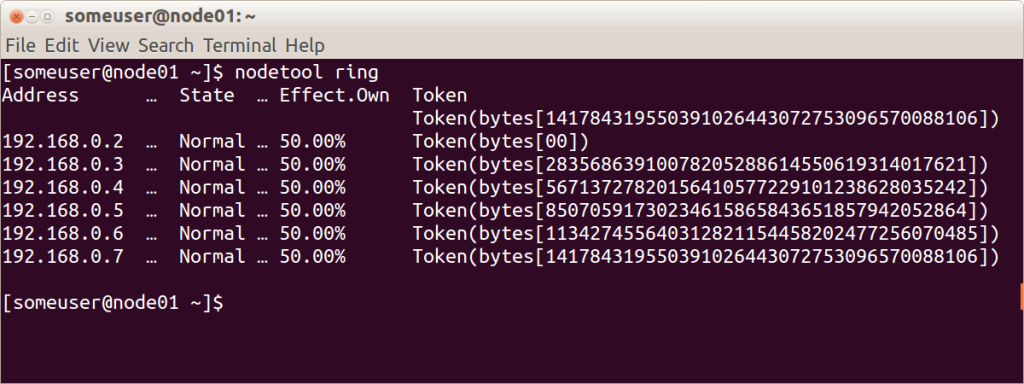
Before you add a node to the cluster, you must set a label for it. From what percentage of keys covers the gap between this label and the next, depends on how much data will be stored on the site. The entire label set for a cluster is called a ring .
Here is an illustration of a cluster ring consisting of 6 nodes with uniformly distributed labels using the nodetool integrated utility.
Data consistency
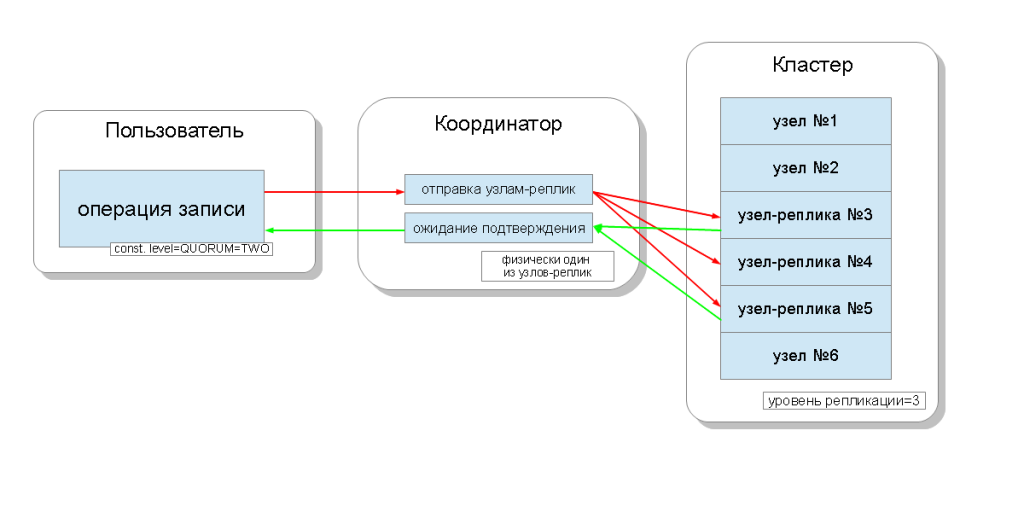
Cassandra cluster nodes are equal, and customers can connect to any of them, both for writing and reading. Requests go through a coordination stage, during which, having ascertained on which nodes the data should be located, the server sends requests to these nodes. We will call the node that coordinates - the coordinator ( coordinator ), and the nodes that are selected to save the record with this key - replica nodes ( replica nodes ). Physically, the coordinator can be one of the replica nodes - it depends only on the key, the marker and tags.
For each request, both for reading and writing, there is an opportunity to set the level of data consistency.
For the record, this level will affect the number of replica nodes from which confirmation of a successful completion of the operation (the data has been recorded) will be expected before returning control to the user. There are levels of consistency for recording:
- ONE - the coordinator sends requests to all replica nodes, but, after waiting for confirmation from the first node, returns control to the user;
- TWO is the same, but the coordinator waits for confirmation from the first two nodes before returning control;
- THREE - similar, but the coordinator waits for confirmation from the first three nodes before returning control;
- QUORUM - a quorum is collected: the coordinator waits for confirmation of the record from more than half of the replica nodes, namely round (N / 2) + 1, where N is the level of replication;
- LOCAL_QUORUM - the coordinator waits for confirmation from more than half of the replica nodes in the same data center where the coordinator is located (for each request, potentially its own). Allows you to get rid of the delays associated with sending data to other data centers. Multi-data center issues are discussed in this article in passing;
- EACH_QUORUM — The coorinator waits for confirmation from more than half of the replica nodes in each data center independently;
- ALL - the coordinator waits for confirmation from all replica nodes;
- ANY - allows you to write data, even if all nodes replicas do not respond. The coordinator waits for either the first response from one of the replica nodes, or when the data is saved using the hinted handoff at the coordinator.
For reading, the level of consistency will affect the number of replica nodes from which to read. There are levels of consistency to read:
- ONE - the coordinator sends requests to the nearest node-replica. The rest of the replicas are also read for the purpose of reading with a repair ( read repair ) with a probability set in the cassandra configuration;
- TWO is the same, but the coordinator sends requests to the two closest nodes. Selects the value that has a large time stamp;
- THREE - similar to the previous version, but with three nodes;
- QUORUM - a quorum is collected, that is, the coordinator sends requests to more than half of the replica nodes, namely round (N / 2) + 1, where N is the level of replication;
- LOCAL_QUORUM - a quorum is collected in the data center in which coordination takes place, and the data is returned with the last time stamp;
- EACH_QUORUM — The coordinator returns data after a quorum meeting at each data center;
- ALL - the coordinator returns data after reading all replica nodes.
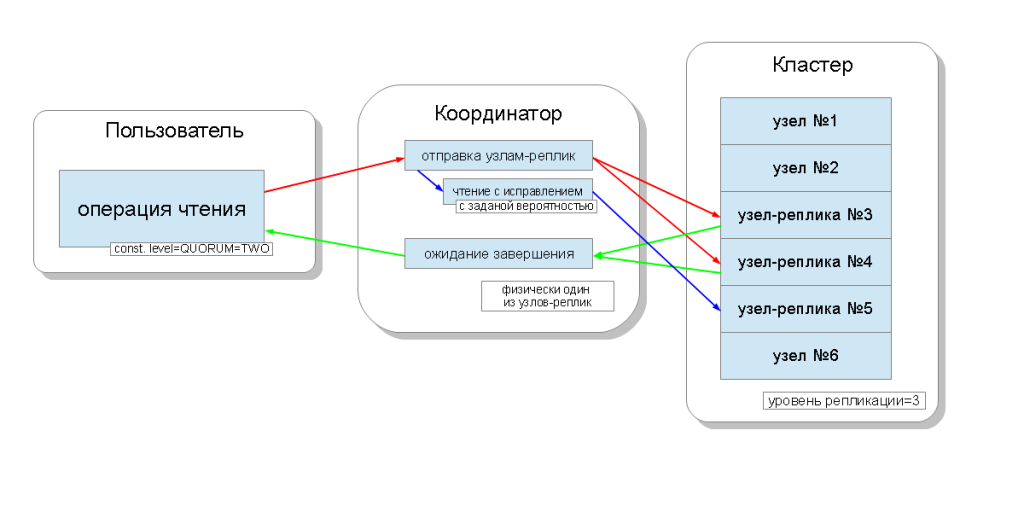
Thus, it is possible to adjust the time delays of read, write operations and adjust the consistency ( tune consistency ), as well as the availability ( availability ) of each type of operation. In fact, availability is directly dependent on the level of consistency of read and write operations, since it determines how many replica nodes can fail, and these operations will still be confirmed.
If the number of nodes from which confirmation of a record comes, in total with the number of nodes from which reading occurs, is greater than the replication level, then we have a guarantee that after writing a new value will always be read, and this is called strict consistency ( strong consistency ). In the absence of strict consistency, there is the possibility that the read operation will return outdated data.
In any case, the value eventually spreads between the replicas, but after the coordination wait ends. This distribution is called eventual consistency . If not all replica nodes will be available during recording, then sooner or later, recovery tools, such as reading with a fix and anti-entropy node repair, will be used. More on this later.
Thus, with the read and write QUORUM consistency level, strict consistency will always be maintained, and there will be some balance between the delay in the read and write operations. When writing ALL, and reading ONE there will be strict consistency, and reading operations will be performed faster and will have greater accessibility, that is, the number of failed nodes, at which reading will still be performed, may be greater than with QUORUM. For write operations, all replica work nodes will be required. When writing ONE, reading ALL, there will also be strict consistency, and write operations will be faster and write accessibility will be great, it will be enough just to confirm that the write operation went on at least one of the servers, and read more slowly and require all replica nodes . If the application does not have a requirement for strict consistency, then it becomes possible to speed up both read and write operations, as well as improve accessibility by setting lower levels of consistency.
Data recovery
Cassandra supports three data recovery mechanisms:
- read repair — during reading, data is requested from all replicas and compared after coordination is complete. The column that has the latest time stamp will be distributed to nodes where tags are obsolete.
- directional send ( hinted handoff ) - allows you to save information about the write operation on the coordinator in the event that the write to any of the nodes failed. Later, when it will be possible, the recording will be repeated. Allows you to quickly perform data recovery in the event of a short-term absence of a node in the cluster. In addition, at the level of consistency, ANY allows you to achieve full write access ( absolute write availability ), when even all replica nodes are not available, the write operation is confirmed, and the data is stored on the coordinator node.
- anti- entropy node repair is a kind of recovery process for all replicas that must be started regularly manually using the “nodetool repair” command and allows you to maintain the replica number of all data that may not have been restored by the first two methods, required level of replication.
Burn to disc
When data comes after coordination directly to the node for recording, they fall into two data structures: a table in memory ( memtable ) and a log of commit ( commit log ). A table in memory exists for each column family and allows you to memorize the value instantly. Technically, this is a hash table with simultaneous access ( concurrent access ) based on a data structure called “ skip list ”. The pinning log is one for the entire key space and is stored on disk. A log is a sequence of modification operations. It also breaks into pieces when it reaches a certain size.
Such an organization makes it possible to make the recording speed limited to the speed of sequential writing to the hard disk and at the same time guarantee data durability ( data durability ). The pinning log in case of an emergency stop of the node is read at the start of the cassandra service and restores all tables in memory. It turns out that the speed rests on the sequential write to the disk, and in modern hard drives it is about 100MB / s. For this reason, it is advisable to put a fixing journal on a separate disk medium.
It is clear that sooner or later the memory can be filled. Therefore, the table in memory must also be saved to disk. To determine the moment of saving, there is a limit on the size of the occupied tables in memory ( memtable_total_spacein_mb ), by default it is the maximum size of the Java heap ( Java heapspace ). When filling tables with more than this limit in memory, cassandra creates a new table and writes the old table in memory to disk as a saved table ( SSTable ). The stored table after creation is never modified again ( is immutable ). When saving to disk occurs, the parts of the log are marked as free, thus freeing up the disk space occupied by the journal. It is necessary to take into account that the journal has an interlaced structure from data of different column families in the key space, and some parts may not be released, since some areas will correspond to other data still in the tables in memory.
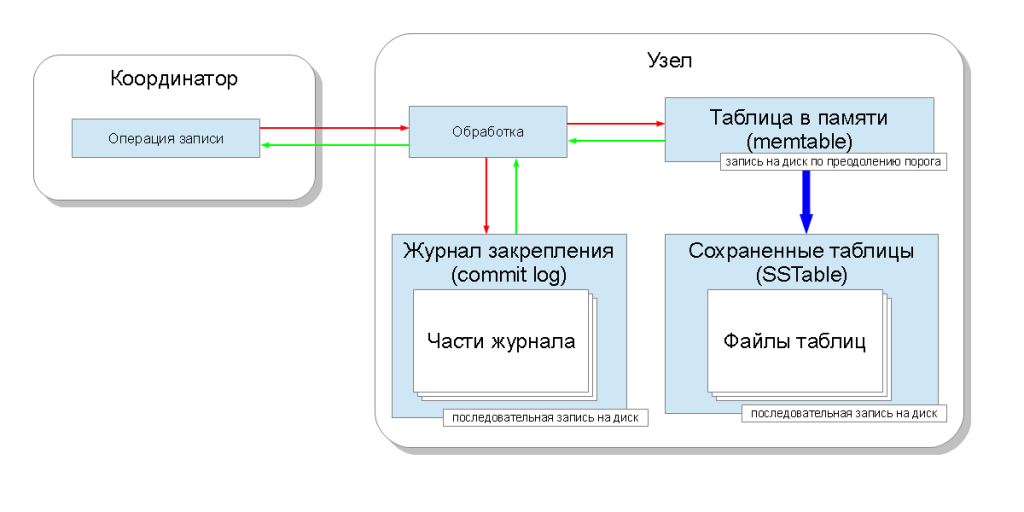
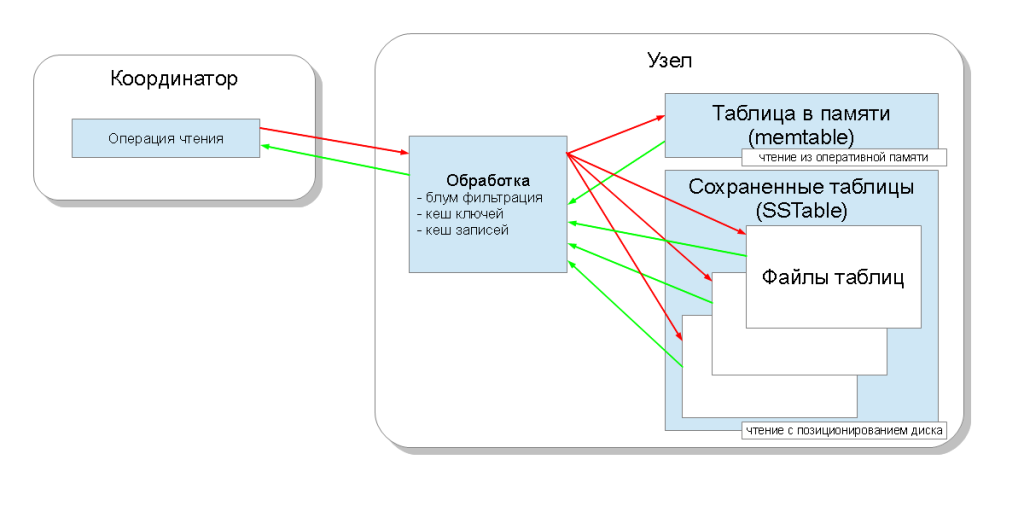
As a result, each column family corresponds to one table in memory and a number of saved tables. Now that the node is processing the read request, it needs to query all these structures and select the most recent value for the timestamp. To speed up this process, there are three mechanisms: bloom filtering ( bloom filter ), key cache ( key cache ) and write cache ( record cache ):
- The bloom filter is a data structure that takes up little space and allows you to answer the question: is the element contained, and in our case is it a key, in a set or not. Moreover, if the answer is “no”, then it is 100%, and if the answer is “yes”, then this is probably a false-positive answer. This allows you to reduce the number of reads from the saved tables;
- the key cache stores a position on the write disk for each key, thus reducing the number of positioning operations ( seek operations ) while searching the stored table;
- write cache keeps the entire record, allowing you to completely get rid of disk read operations.
Compaction
At a certain point in time, the data in the column family will be overwritten — columns will come that will have the same name and key. That is, a situation will arise when the older and newer stored table will contain old and new data. In order to guarantee integrity, Cassandra must read all these stored tables and select data with the latest timestamp. It turns out that the number of hard disk positioning operations when reading is proportional to the number of stored tables. Therefore, in order to free up the overwritten data and reduce the number of saved tables, there is a compaction process . It reads several stored tables in succession and writes a new saved table, which combines data by timestamps. When a table is fully recorded and put into use, cassandra can release source tables (the tables that formed it). Thus, if the tables contain overwritten data, then this redundancy is eliminated. It is clear that during such an operation the amount of redundancy increases - a new saved table exists on the disk along with the source tables, which means that the amount of disk space must always be such that it can be compacted.

Cassandra allows you to choose one of two compaction strategies:
- strategy of compacting saved tables of size-tiered compaction — this strategy compacts the two tables selected in a certain way. It is applied automatically as a background compaction ( minor compaction ) and in manual mode, for full compaction ( major compaction ). Allows the situation of finding the key in many tables and, accordingly, requires to perform a search operation for each such table.
- strategy compaction of saved tables with levels ( leveled compaction ) - compresses saved tables that are initially created small - 5 MB, grouping them into levels. Each level is 10 times greater than the previous one. Moreover, there are such guarantees: 90% of read requests will occur to a single saved table, and only 10% of the disk space will be used for outdated data. In this case, only 10-fold size of the table, that is, 50 MB, is sufficient to perform compression for a temporary table. More in this article
Delete operations
From the point of view of the internal device, the operation of deleting columns is the operation of writing a special value - a wiping value ( tombstone ). When such a value is obtained as a result of reading, it is skipped, as if such a value never existed. As a result of compaction, such values are gradually crowding out obsolete real values and, possibly, disappear altogether. If there are columns with real data with even newer time stamps, then they will grind, and in the end, these overwrite values.
Transactional
Cassandra supports transactionalization at the level of one record, that is, for a set of columns with one key. Here are four ACID requirements:
- atomicity - all columns in one record in one operation will be either recorded or not;
- consistency - as already mentioned above, it is possible to use requests with strict consistency instead of availability, and thereby fulfill this requirement;
- isolation ( isolation ) - starting with cassandra version 1.1, there is support for isolation, when, while recording the columns of one record, another user who reads the same record will see either the old version of the record or, after the end of the operation, the new version, not part of columns of one and part of the second;
- durability is ensured by the presence of a binding log that will be reproduced and will restore the node to the desired state in case of any failure.
Afterword
So, we looked at how the basic operations are arranged - reading and writing values to the cassandra.
In addition, in my opinion, important references:
- Page at apache.org cassandra.apache.org
- Documentation on datastax.com www.datastax.com/docs/1.1/index#apache-cassandra-1-1-documentation
- About BigTable research.google.com/archive/bigtable.html
- About Amazon Dynamo www.allthingsdistributed.com/2007/10/amazons_dynamo.html
- Just one of the blogs about the data model maxgrinev.com/2010/07/09/a-quick-introduction-to-the-cassandra-data-model
Please: comment on the spelling and ideas for improving the article expressed in a personal message.
Source: https://habr.com/ru/post/155115/
All Articles