Fluid Data: a “small” win in storing “big” data
A remarkable amount of discoveries helps people to make nature. The flight of dragonfly inspired aircraft designers, the crowns of deciduous trees - the creators of solar cells. And water is a unique substance - inspired Dell engineers to create a fundamentally new technology for Dell Compellent storage systems, dubbed Fluid Data.
The main problem with most storage systems is not new - data management at the volume level. This approach initially limits not only flexibility, but also the performance of the complex. Immediately make a reservation that even though the problem is the main one, it is by no means the only one. But first things first.
')
There is a joke in the circle of webmasters: “Let's do everything quickly, efficiently, inexpensively. Choose any two items. ” Until recently, it was to some extent true for data storage systems. If the information needed quick access, it should be stored on the SSD. But their Achilles heel was a high cost with relatively low capacities. On the other hand, traditional solutions had opposite advantages: low price and large volume. Yes, only with the speed of access compared to the SSD was a disaster. Dell Compellent has become a logical evolutionary step in the development of storage, combining both approaches through the new dynamic architecture of Fluid Data. The latter in the active mode intelligently manages the data not at the volume level, but at the block level. A variety of information about each of them is continuously collected "on the fly" and is used for the functions of dynamic storage, migration and data recovery. Collecting this data creates minimal additional load on the system and allows you to get detailed information about its characteristics such as the type of data stored and the disks used, the level of RAID, the recording time, the frequency of accessing data, etc. The profit is obvious: information is always available and protected, applications are deployed much faster, and new technologies are promptly supported. But let's see how it works.
The first thing Dell engineers decided to fight in the storage system was the inefficient use of disk space when creating volumes. Traditionally, administrators calculate how much capacity is required for a particular application, then they throw it over just in case, and eventually create a volume with an advance excess volume. In general, the approach is correct, but the problem lies in the impossibility of redistributing unused capacity. That is, if you created a volume per gigabyte, then this entire gigabyte will be available only to one application, while the others “will remain with the nose”. Often, in practice, applications use less than half of the capacity allocated to them, and as a result, stocks of “frozen” space are spent in the corporate vault, in which money was wasted. However, for the sake of reinsurance, many companies are still taking this step.
Is it good? Hardly. Administrators are forced to buy more capacity than they originally needed. At the same time, after some time, when the capacity will be spent, they will have to re-buy new drives, because of which, you may need to install additional racks in the storage. And this is not to mention the energy supply, cooling and control of the expanding “brainchild”.
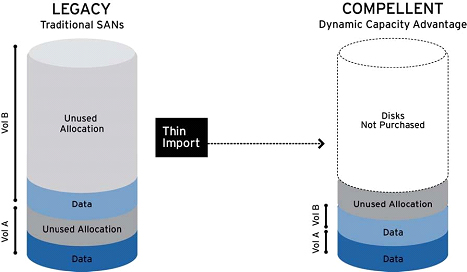
To solve these problems, Dell Compellent uses Dynamic Capacity software, which completely separates the allocation of resources from their use. The function itself is called Thin Provisioning. Its essence lies in the fact that immediately after the installation of the system, administrators can allocate a virtual volume of any size, but the physical capacity is consumed only when data is written to disk. This means that now customers can buy exactly as much capacity as they need to store data today, and then (if necessary) gradually purchase it as the business needs grow. In most cases, with Thin Provisioning, companies can save from 40 to 60 percent of disk space compared to traditional growth capacity. And with the Thin Import feature, you can even free up unused capacity of volumes that were created on legacy storage systems.
So, when we figured out the effective distribution of the place, it is time to say a few words about it.
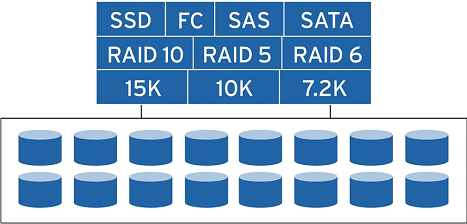
Data management at the block level allows Dell Compellent systems to virtualize disk-level storage, which significantly improves system flexibility. Administrators no longer need to distribute specific disks between specific servers - instead, a shared pool of resources is created that covers all the disks in the system. Servers “see” storage resources simply as available capacity regardless of disk type, RAID level, or connection to servers. Thus, all storage resources at any time are available for all servers. A special feature is the ability of the system to automatically expand volumes if the application does not have enough capacity.
With this architecture, read / write operations are distributed across all disks, so you can handle multiple I / O requests in parallel. As a result, the bottlenecks of traditional storage systems are eliminated. As capacity is added to the pool, data is automatically redistributed across all available disks and the administrator does not need to manually do load balancing and performance tuning.
Storage virtualization significantly improves the effect of server virtualization deployment — users can quickly create hundreds of virtual volumes to support any server platform.
For dessert, as always, it was decided to leave the most "tasty", namely the technology of dynamic classification and data migration. We assume that we have already learned how to effectively store data. The next step is to organize access to this data no less efficiently. To understand the essence of the problem, consider the following analogy.
Remember where in the apartment you keep your socks? Surely somewhere nearby: in a closet, drawer or just scattered on the floor within sight. Now, remember where the beach umbrella or air mattress is stored? On the balcony, at the entresol? Finally, the final question: why don't you keep these things the other way around? The answer is obvious. Socks are used much more often, and, therefore, access to them should be as convenient and fast as possible. The technology of dynamic classification and data migration uses the same principle.

New data is written to SAS / FC 15K disks at the first Tier 1 storage level. Then the frequency of hits is analyzed and as it decreases, less active data blocks migrate to FC or SAS disks of the second storage level. After some time, data that has not been accessed for a long time is written to high-capacity SAS or SATA disks in the third storage level. Additionally, different types of RAID are used at each level, and data is dynamically moved through it within the level (for example, from RAID10 to RAID5).
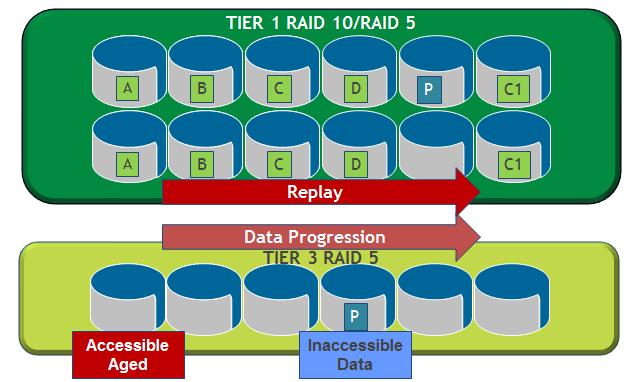
In addition, to increase access speed, the most active data is stored on the external sectors of each disk. The system logic works both ways. That is, if there are several hits to the passive data, then they are moved to a higher level. Administrators only adjust the algorithm for moving between levels in accordance with the specific tasks of their company, or use the factory default values.
Of course, this is not all the advantages and capabilities of Fluid Data. A separate story stands and data replication to remote sites, and features of protection and recovery, and platform scalability, and even the interface. But if you try to shove it all into one article, on the one hand, we risk either terrifying the respected habrovcans with the volume of such material, or create a sort of encyclopedia in which “everything, but a little bit”. Fortunately, we are not obliged to choose one of the two options, and therefore, as in the case of Fluid Data, we will invent our own, breaking the story about the technology into two parts. To be continued…
The main problem with most storage systems is not new - data management at the volume level. This approach initially limits not only flexibility, but also the performance of the complex. Immediately make a reservation that even though the problem is the main one, it is by no means the only one. But first things first.
Operating principle
')
There is a joke in the circle of webmasters: “Let's do everything quickly, efficiently, inexpensively. Choose any two items. ” Until recently, it was to some extent true for data storage systems. If the information needed quick access, it should be stored on the SSD. But their Achilles heel was a high cost with relatively low capacities. On the other hand, traditional solutions had opposite advantages: low price and large volume. Yes, only with the speed of access compared to the SSD was a disaster. Dell Compellent has become a logical evolutionary step in the development of storage, combining both approaches through the new dynamic architecture of Fluid Data. The latter in the active mode intelligently manages the data not at the volume level, but at the block level. A variety of information about each of them is continuously collected "on the fly" and is used for the functions of dynamic storage, migration and data recovery. Collecting this data creates minimal additional load on the system and allows you to get detailed information about its characteristics such as the type of data stored and the disks used, the level of RAID, the recording time, the frequency of accessing data, etc. The profit is obvious: information is always available and protected, applications are deployed much faster, and new technologies are promptly supported. But let's see how it works.
The first thing Dell engineers decided to fight in the storage system was the inefficient use of disk space when creating volumes. Traditionally, administrators calculate how much capacity is required for a particular application, then they throw it over just in case, and eventually create a volume with an advance excess volume. In general, the approach is correct, but the problem lies in the impossibility of redistributing unused capacity. That is, if you created a volume per gigabyte, then this entire gigabyte will be available only to one application, while the others “will remain with the nose”. Often, in practice, applications use less than half of the capacity allocated to them, and as a result, stocks of “frozen” space are spent in the corporate vault, in which money was wasted. However, for the sake of reinsurance, many companies are still taking this step.
Is it good? Hardly. Administrators are forced to buy more capacity than they originally needed. At the same time, after some time, when the capacity will be spent, they will have to re-buy new drives, because of which, you may need to install additional racks in the storage. And this is not to mention the energy supply, cooling and control of the expanding “brainchild”.
To solve these problems, Dell Compellent uses Dynamic Capacity software, which completely separates the allocation of resources from their use. The function itself is called Thin Provisioning. Its essence lies in the fact that immediately after the installation of the system, administrators can allocate a virtual volume of any size, but the physical capacity is consumed only when data is written to disk. This means that now customers can buy exactly as much capacity as they need to store data today, and then (if necessary) gradually purchase it as the business needs grow. In most cases, with Thin Provisioning, companies can save from 40 to 60 percent of disk space compared to traditional growth capacity. And with the Thin Import feature, you can even free up unused capacity of volumes that were created on legacy storage systems.
So, when we figured out the effective distribution of the place, it is time to say a few words about it.
Virtual joys
Data management at the block level allows Dell Compellent systems to virtualize disk-level storage, which significantly improves system flexibility. Administrators no longer need to distribute specific disks between specific servers - instead, a shared pool of resources is created that covers all the disks in the system. Servers “see” storage resources simply as available capacity regardless of disk type, RAID level, or connection to servers. Thus, all storage resources at any time are available for all servers. A special feature is the ability of the system to automatically expand volumes if the application does not have enough capacity.
With this architecture, read / write operations are distributed across all disks, so you can handle multiple I / O requests in parallel. As a result, the bottlenecks of traditional storage systems are eliminated. As capacity is added to the pool, data is automatically redistributed across all available disks and the administrator does not need to manually do load balancing and performance tuning.
Storage virtualization significantly improves the effect of server virtualization deployment — users can quickly create hundreds of virtual volumes to support any server platform.
Data flow
For dessert, as always, it was decided to leave the most "tasty", namely the technology of dynamic classification and data migration. We assume that we have already learned how to effectively store data. The next step is to organize access to this data no less efficiently. To understand the essence of the problem, consider the following analogy.
Remember where in the apartment you keep your socks? Surely somewhere nearby: in a closet, drawer or just scattered on the floor within sight. Now, remember where the beach umbrella or air mattress is stored? On the balcony, at the entresol? Finally, the final question: why don't you keep these things the other way around? The answer is obvious. Socks are used much more often, and, therefore, access to them should be as convenient and fast as possible. The technology of dynamic classification and data migration uses the same principle.
New data is written to SAS / FC 15K disks at the first Tier 1 storage level. Then the frequency of hits is analyzed and as it decreases, less active data blocks migrate to FC or SAS disks of the second storage level. After some time, data that has not been accessed for a long time is written to high-capacity SAS or SATA disks in the third storage level. Additionally, different types of RAID are used at each level, and data is dynamically moved through it within the level (for example, from RAID10 to RAID5).
In addition, to increase access speed, the most active data is stored on the external sectors of each disk. The system logic works both ways. That is, if there are several hits to the passive data, then they are moved to a higher level. Administrators only adjust the algorithm for moving between levels in accordance with the specific tasks of their company, or use the factory default values.
To be continued
Of course, this is not all the advantages and capabilities of Fluid Data. A separate story stands and data replication to remote sites, and features of protection and recovery, and platform scalability, and even the interface. But if you try to shove it all into one article, on the one hand, we risk either terrifying the respected habrovcans with the volume of such material, or create a sort of encyclopedia in which “everything, but a little bit”. Fortunately, we are not obliged to choose one of the two options, and therefore, as in the case of Fluid Data, we will invent our own, breaking the story about the technology into two parts. To be continued…
Source: https://habr.com/ru/post/154135/
All Articles