Scaling basics
After reading this blog about client-side balancing , I decided to publish my article, which describes the basic principles of scaling for web-projects. I hope it will be interesting for the habra people to read.
Scalability - the ability of a device to increase its
opportunities
by increasing the number of functional blocks,
performing one and
the same tasks.
Glossary.ru
')
Usually they start thinking about scaling when one
The server does not cope with the work assigned to it. What exactly is he not
cope? The work of any web server by and large comes down to the main
computer occupation - data processing. Response to HTTP (or any other) request
implies some operations on certain data. Respectively,
we have two main entities - these are data (characterized by their volume) and
calculations (characterized by complexity). The server can not cope with its
due to the large amount of data (they may not physically fit on
server), or because of the large computational load. It comes here,
Of course, about the total load - the complexity of processing a single request can be
It is small, but a large number of them can "fill up" the server.
We will mainly talk about scaling by example
typical growing web project, but the principles described here are also suitable for
other applications. First we look at the architecture of the project and the simple
distributing its components to multiple servers, and then talk about
scaling calculations and data.
The life of a typical site begins with a very simple architecture.
- this is one web server (usually Apache is in its role),
who does all the work on HTTP requests,
coming from visitors. He gives customers the so-called "static", then
there are files that are on the server disk and do not require processing: pictures (gif,
jpg, png), style sheets (css), client scripts (js, swf). Same server
responds to queries requiring computation - usually this formation
html pages, though sometimes images and other documents are created on the fly.
Most often the answers to such requests are generated by scripts written in php,
perl or other languages.
The disadvantage of such a simple scheme of work is that
the nature of requests (return files from disk and computational work of scripts)
processed by the same web server. Computational queries require
keep a lot of information in the server’s memory (script language interpreter,
the scripts themselves, the data they work with) and can take a lot
computing resources. Issuing statics, on the contrary, requires few resources.
processor, but may take a long time if the client has a low
communication speed The internal structure of the Apache server assumes that each
connection is processed by a separate process. This is convenient for scripting,
however, it is not optimal for handling simple requests. It turns out that heavy (from
scripts and other data) Apache processes spend a lot of time waiting (first when receiving
request, then when sending a response), wasting memory of the server.
The solution to this problem is the distribution of the processing work.
requests between two different programs - i.e. division into frontend and
backend. The lightweight frontend server performs static stat and the rest
requests redirects (proxies) to the backend where the formation is performed
pages. Waiting for slow clients also takes on the frontend, and if it uses
multiplexing (when one process serves multiple clients - so
work, for example, nginx or lighttpd), then waiting for almost nothing
worth it.
Of the other components of the site should be noted database
which is usually stored the basic data of the system - the most popular here
free MySQL and PostgreSQL DBMS. Often separately allocated storage
binary files that contain images (for example, illustrations to articles
site, avatars and user photos) or other files.
Thus, we obtained an architecture diagram consisting of
several components.

Usually at the beginning of the life of the site all components of the architecture
are located on the same server. If he stops coping with the load, then
there is a simple solution - move the most easily detachable parts to another
server. The easiest place to start is from the database - transfer it to a separate server and
change access details in scripts. By the way, at this moment we are faced with
the importance of proper software code architecture. If working with a database
rendered into a separate module common to the whole site - then correct the parameters
connections will be easy.
Ways of further separation of components are also understandable - for example, you can take the frontend to a separate server. But usually frontend
requires few system resources and at this stage the takeaway will not provide significant
performance gains. Most often, the site rests on performance
Scripting - the formation of a response (html-page) takes too long.
Therefore, the next step is usually scaling the backend server.
A typical situation for a growing site - the database is already
rendered to a separate machine, the division into frontend and backend is done,
However, attendance continues to increase and the backend does not have time to process
requests. This means that we need to distribute the calculations to several
servers. Make it simple - just buy a second server and put it on
it programs and scripts needed to work backend.
After that, you need to make sure that user requests are distributed.
(balanced) between the received servers. About different methods of balancing
it will be said below, but for the time being we note that this is usually done by the frontend
which is configured so that it evenly distributes the requests between
servers.
It is important that all backend servers are capable
respond to requests. Usually this requires that each of them work with
the same relevant data set. If we store all information in a single
database, the DBMS itself will provide shared access and consistency of data.
If some data is stored locally on the server (for example, php-session
client), it is worth thinking about transferring them to a shared storage, or more
complex query distribution algorithm.
Distribute across multiple servers can not only work
scripts, but also calculations performed by the database. If the DBMS performs a lot
complex queries, taking up server CPU time, you can create several
database copies on different servers. This raises the issue of synchronization
data with changes, and several approaches are applicable here.
There are various options for the distribution of the system servers.
For example, we may have one database server and several backend (quite
typical scheme), or vice versa - one backend and several databases. And if we scale
and the backend server and database, you can combine the backend and a copy of the database
one car. In any case, as soon as we have a few copies.
any server, the question arises how to distribute between them correctly
load.
Suppose we have created several servers (for any purpose - http, database, etc.), each of which can handle requests. Before
we have a task - how to distribute work among them, how to find out on which
server to send a request? There are two main ways to distribute requests.
Of course, there are combinations of these approaches. For example,
A known load balancing method, such as DNS balancing, is based on
that when determining the site’s IP address, a client is issued
address of one of several identical servers. Thus, the DNS appears in
the role of the balancing node from which the client receives the “distribution”. but
the very structure of DNS servers implies the absence of a point of failure due to
duplication - that is, the merits of the two approaches are combined. Of course, this
There are also disadvantages to the balancing method - for example, such a system is difficult to dynamically
rebuild.
Work with the site is usually not limited to one request.
Therefore, when designing, it is important to understand whether sequential queries can
client to be correctly processed by different servers, or the client must be
tied to one server while working with the site. This is especially important if
The site stores temporary information about the user's session (in this
free distribution is also possible in case of accident
sessions in general for all servers storage). "Bind" the visitor to
specific server can be on its IP-address (which, however, may vary),
or by cookie (in which the server identifier is pre-recorded), or even
just redirecting it to the desired domain.
On the other hand, computing servers may not be equal.
In some cases it is beneficial to do the opposite, allocate a separate server for
processing requests of one type - and get vertical separation
functions. Then the client or balancing node will choose the server in
depending on the type of request received. This approach allows you to separate
important (or vice versa, not critical, but heavy) requests from the rest.
We learned how to distribute calculations, so a large
attendance is not a problem for us. However, data volumes continue to grow,
it becomes more difficult to store and process them - which means it's time to build
distributed data storage. In this case, we will not have one or
multiple servers containing a complete copy of the database. Instead, the data
will be distributed across different servers. What are the possible distribution schemes?
To select the correct data distribution scheme
carefully analyze the structure of the base. Existing tables (and possibly
individual fields) can be classified by frequency of access to records, by frequency
updates and interrelationships (the need to take samples from several
tables).
As mentioned above, besides a database, a site is often required
storage for binary files. Distributed File Storage Systems
(in fact, file systems) can be divided into two classes.
It should be noted that the distribution of data decides not only
the issue of storage, but also partly the issue of load distribution - at each
server gets fewer records, and therefore they are processed faster.
The combination of methods for distributing calculations and data allows you to build
potentially unlimitedly scalable architecture capable of working with
any amount of data and any load.
Summarizing the above, we formulate the conclusions in the form of brief theses.
You can continue to study this topic on interesting English-speaking sites and blogs:
PS Comments, of course, are welcome ;)
Scaling basics
Scalability - the ability of a device to increase its
opportunities
by increasing the number of functional blocks,
performing one and
the same tasks.
Glossary.ru
')
Usually they start thinking about scaling when one
The server does not cope with the work assigned to it. What exactly is he not
cope? The work of any web server by and large comes down to the main
computer occupation - data processing. Response to HTTP (or any other) request
implies some operations on certain data. Respectively,
we have two main entities - these are data (characterized by their volume) and
calculations (characterized by complexity). The server can not cope with its
due to the large amount of data (they may not physically fit on
server), or because of the large computational load. It comes here,
Of course, about the total load - the complexity of processing a single request can be
It is small, but a large number of them can "fill up" the server.
We will mainly talk about scaling by example
typical growing web project, but the principles described here are also suitable for
other applications. First we look at the architecture of the project and the simple
distributing its components to multiple servers, and then talk about
scaling calculations and data.
Typical site architecture
The life of a typical site begins with a very simple architecture.
- this is one web server (usually Apache is in its role),
who does all the work on HTTP requests,
coming from visitors. He gives customers the so-called "static", then
there are files that are on the server disk and do not require processing: pictures (gif,
jpg, png), style sheets (css), client scripts (js, swf). Same server
responds to queries requiring computation - usually this formation
html pages, though sometimes images and other documents are created on the fly.
Most often the answers to such requests are generated by scripts written in php,
perl or other languages.
The disadvantage of such a simple scheme of work is that
the nature of requests (return files from disk and computational work of scripts)
processed by the same web server. Computational queries require
keep a lot of information in the server’s memory (script language interpreter,
the scripts themselves, the data they work with) and can take a lot
computing resources. Issuing statics, on the contrary, requires few resources.
processor, but may take a long time if the client has a low
communication speed The internal structure of the Apache server assumes that each
connection is processed by a separate process. This is convenient for scripting,
however, it is not optimal for handling simple requests. It turns out that heavy (from
scripts and other data) Apache processes spend a lot of time waiting (first when receiving
request, then when sending a response), wasting memory of the server.
The solution to this problem is the distribution of the processing work.
requests between two different programs - i.e. division into frontend and
backend. The lightweight frontend server performs static stat and the rest
requests redirects (proxies) to the backend where the formation is performed
pages. Waiting for slow clients also takes on the frontend, and if it uses
multiplexing (when one process serves multiple clients - so
work, for example, nginx or lighttpd), then waiting for almost nothing
worth it.
Of the other components of the site should be noted database
which is usually stored the basic data of the system - the most popular here
free MySQL and PostgreSQL DBMS. Often separately allocated storage
binary files that contain images (for example, illustrations to articles
site, avatars and user photos) or other files.
Thus, we obtained an architecture diagram consisting of
several components.
Usually at the beginning of the life of the site all components of the architecture
are located on the same server. If he stops coping with the load, then
there is a simple solution - move the most easily detachable parts to another
server. The easiest place to start is from the database - transfer it to a separate server and
change access details in scripts. By the way, at this moment we are faced with
the importance of proper software code architecture. If working with a database
rendered into a separate module common to the whole site - then correct the parameters
connections will be easy.
Ways of further separation of components are also understandable - for example, you can take the frontend to a separate server. But usually frontend
requires few system resources and at this stage the takeaway will not provide significant
performance gains. Most often, the site rests on performance
Scripting - the formation of a response (html-page) takes too long.
Therefore, the next step is usually scaling the backend server.
Calculation Distribution
A typical situation for a growing site - the database is already
rendered to a separate machine, the division into frontend and backend is done,
However, attendance continues to increase and the backend does not have time to process
requests. This means that we need to distribute the calculations to several
servers. Make it simple - just buy a second server and put it on
it programs and scripts needed to work backend.
After that, you need to make sure that user requests are distributed.
(balanced) between the received servers. About different methods of balancing
it will be said below, but for the time being we note that this is usually done by the frontend
which is configured so that it evenly distributes the requests between
servers.
It is important that all backend servers are capable
respond to requests. Usually this requires that each of them work with
the same relevant data set. If we store all information in a single
database, the DBMS itself will provide shared access and consistency of data.
If some data is stored locally on the server (for example, php-session
client), it is worth thinking about transferring them to a shared storage, or more
complex query distribution algorithm.
Distribute across multiple servers can not only work
scripts, but also calculations performed by the database. If the DBMS performs a lot
complex queries, taking up server CPU time, you can create several
database copies on different servers. This raises the issue of synchronization
data with changes, and several approaches are applicable here.
- Synchronization at the application level . In this case, our
scripts independently write changes to all copies of the database (and they themselves carry
responsibility for the correctness of the data). This is not the best option since it
requires caution in implementation and is highly error-tolerant. - Replication - that is, automatic replication
changes made on one server to all other servers. Usually when
When using replication, changes are always recorded on the same server - it is called master, and the remaining copies are slave. Most DBMS have
Built-in or external replication tools. Distinguish
synchronous replication - in this case, a data change request will wait
until the data is copied to all servers, and only then it is completed successfully - and asynchronous - in this case, the changes are copied to the slave-server from
delay, but the write request completes faster. - Multi-master replication. This approach is similar
previous, but here we can make changes to the data, referring not to
to one specific server, and to any copy of the database. With this change
synchronously or asynchronously get on other copies. Sometimes such a scheme is called
the term "database cluster".
There are various options for the distribution of the system servers.
For example, we may have one database server and several backend (quite
typical scheme), or vice versa - one backend and several databases. And if we scale
and the backend server and database, you can combine the backend and a copy of the database
one car. In any case, as soon as we have a few copies.
any server, the question arises how to distribute between them correctly
load.
Balancing methods
Suppose we have created several servers (for any purpose - http, database, etc.), each of which can handle requests. Before
we have a task - how to distribute work among them, how to find out on which
server to send a request? There are two main ways to distribute requests.
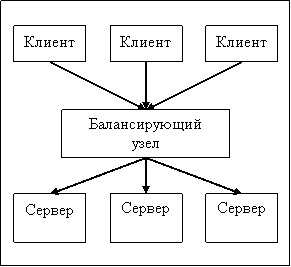
- Balancing node . In this case, the client sends a request for one
fixed, known to him the server, and he already redirects the request to one of
working servers. A typical example is a site with one frontend and several
backend servers to which requests are proxied. However, the “client” may
be inside our system - for example, the script can send a request to
to the database proxy server, which forwards the request to one of the DBMS servers.
The balancing node itself can work both on a separate server and on one
from working servers.
The advantages of this approach are
that the client does not need to know anything about the internal structure of the system - about the number
servers, their addresses and features - all this information knows only
balancer. However, the disadvantage is that the balancing node is one
system failure point - if it fails, the whole system will be
inoperable. In addition, with a heavy load, the balancer can simply stop
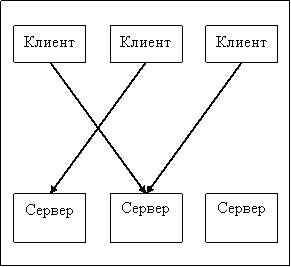
cope with their work, so this approach is not always applicable. - Client side balancing . If we want to avoid
single point of failure, there is an alternative option - to instruct the choice of server
to the client himself. In this case, the client should know about the internal structure of our
systems to be able to choose the right server to access.
The undoubted advantage is the absence of a point of failure - if one of the
server, the client will be able to contact others. However, the price for this is
increased client logic and less balancing flexibility.
Of course, there are combinations of these approaches. For example,
A known load balancing method, such as DNS balancing, is based on
that when determining the site’s IP address, a client is issued
address of one of several identical servers. Thus, the DNS appears in
the role of the balancing node from which the client receives the “distribution”. but
the very structure of DNS servers implies the absence of a point of failure due to
duplication - that is, the merits of the two approaches are combined. Of course, this
There are also disadvantages to the balancing method - for example, such a system is difficult to dynamically
rebuild.
Work with the site is usually not limited to one request.
Therefore, when designing, it is important to understand whether sequential queries can
client to be correctly processed by different servers, or the client must be
tied to one server while working with the site. This is especially important if
The site stores temporary information about the user's session (in this
free distribution is also possible in case of accident
sessions in general for all servers storage). "Bind" the visitor to
specific server can be on its IP-address (which, however, may vary),
or by cookie (in which the server identifier is pre-recorded), or even
just redirecting it to the desired domain.
On the other hand, computing servers may not be equal.
In some cases it is beneficial to do the opposite, allocate a separate server for
processing requests of one type - and get vertical separation
functions. Then the client or balancing node will choose the server in
depending on the type of request received. This approach allows you to separate
important (or vice versa, not critical, but heavy) requests from the rest.
Data distribution
We learned how to distribute calculations, so a large
attendance is not a problem for us. However, data volumes continue to grow,
it becomes more difficult to store and process them - which means it's time to build
distributed data storage. In this case, we will not have one or
multiple servers containing a complete copy of the database. Instead, the data
will be distributed across different servers. What are the possible distribution schemes?
- Vertical distribution (vertical partitioning) - in the simplest case
is the removal of separate database tables to another server. With
this we will need to change the scripts to access different servers for
different data. In the limit, we can store each table on a separate server.
(although in practice it is unlikely to be profitable). Obviously, with such
distribution, we lose the ability to make SQL queries that combine data from
two tables located on different servers. If necessary, you can implement
merge logic in an application, but it will not be as efficient as in a DBMS.
Therefore, when splitting a database, you need to analyze the relationships between the tables,
to spread as independent tables as possible.
More difficult case
the vertical distribution of the base is the decomposition of a single table, when part of
its columns are on one server, and some - on the other. Such reception
is less common, but it can be used, for example, to separate small
and frequently updated data from a large amount of rarely used. - Horizontal distribution (horizontal partitioning) - is
distribution of data from one table across multiple servers. In fact on
each server creates a table of the same structure, and stores in it
a certain piece of data. You can distribute data across servers
criteria: by range (records with id <100000 go to server A, the rest - to server B), according to the list of values (records of the type “ZAO” and “OJSC” are saved to the server
A, the rest - to server B) or by the value of a hash function from some field
records Horizontal data partitioning allows you to store unlimited
the number of records, however, complicates the selection. Most effectively you can choose
records only when it is known on which server they are stored.
To select the correct data distribution scheme
carefully analyze the structure of the base. Existing tables (and possibly
individual fields) can be classified by frequency of access to records, by frequency
updates and interrelationships (the need to take samples from several
tables).
As mentioned above, besides a database, a site is often required
storage for binary files. Distributed File Storage Systems
(in fact, file systems) can be divided into two classes.
- Operating at the operating system level . At the same time for
applications work with files in such a system is no different from the usual work with
files. The exchange of information between the servers takes over the operating system.
Examples of such file systems include the long-known
NFS family or less well-known, but more modern Luster system. - Implemented at the application level distributed
the repositories imply that the work on information exchange is done by
attachment. Usually the functions of working with the storage for convenience are made in
separate library. One of the clearest examples of such a repository is MogileFS, developed by
creators of LiveJournal. Another common example is the use of
WebDAV protocol and its supporting repository.
It should be noted that the distribution of data decides not only
the issue of storage, but also partly the issue of load distribution - at each
server gets fewer records, and therefore they are processed faster.
The combination of methods for distributing calculations and data allows you to build
potentially unlimitedly scalable architecture capable of working with
any amount of data and any load.
findings
Summarizing the above, we formulate the conclusions in the form of brief theses.
- The two main (and related) tasks of scaling are distribution of calculations and distribution of data.
- Typical site architecture implies separation of roles and
includes frontend, backend, database and sometimes file storage - With small amounts of data and heavy loads apply
database mirroring - synchronous or asynchronous replication - When large amounts of data is necessary to distribute the database - split
her vertically or horizontally - Binary files are stored in distributed file systems.
(implemented at the OS level or in the application) - Balancing (distribution of requests) can be uniform or
with separation by functionality; with balancing node or on client side - The correct combination of methods will allow to keep any load;)
Links
You can continue to study this topic on interesting English-speaking sites and blogs:
- http://www.highscalability.com/
- http://www.royans.net/arch/
- http://poorbuthappy.com/ease/… -bloglines-vox-and-more
- http://www.possibility.com/epowiki/Wiki.jsp?page=Scalability
PS Comments, of course, are welcome ;)
Source: https://habr.com/ru/post/15362/
All Articles