Optical character recognition in Linux
Introduction
This is not just a review of existing OCRs (we’ll only talk about three ) and not an installation guide (although the installation will be described). This article was created in order to understand what and how can really recognize the Russian and English languages in Linux.
A few words in order to understand the essence of the described processes.
OCR - optical character recognition.
Technology is needed to digitize printed documents; some use OCR for automation purposes (for example, to recognize captcha or to protect against spam bots).
OCR in Linux
I repeat once again: there will be considered programs that recognize the Russian language. Under Linux, there are several OCRs designed for working with the Latin alphabet, there are specialized complexes that work only with Hebrew, for example, all this does not apply to our topic.
In fact, only three products will be discussed: Cuneiform , Tesseract and Finereader Engine . All of them by themselves provide only a console interface, although for the first two GUI is sufficiently developed.
I use Debian Squeeze, but I will often provide links to source codes and explain package builds (you can use the repositories on notesalexp.org or repositories of your distribution kit - I just give an example of the build).
The topic will be revealed in the following order:
')
1. Installing OCR for Linux (3 engines), installing them.
2. OCR CLI comparison with examples.
3. GUI for OCR, their comparison.
4. A small test online-OCR.
5. Conclusions and some predictions and suggestions.
Install OCR for Linux
Cuneiform
A page about a project on wikipedia .
Declared features: support for multiple languages, preserve the formatting of the original document, output to txt, hocr, html, recognize faxes and texts printed on a matrix printer.
We will look at two real ways to use Cuneiform under Linux: native and with the help of Wine (there is a need for this, below you can see for yourself).
1. Native Cuneiform
Launchpad section
Sources
Let's start the installation.
Download the sources and unpack them.
Then everything is standard (see the readme.txt bundled with the source). Go to the source directory and execute sequentially:
mkdir builddir cd builddir cmake -DCMAKE_BUILD_TYPE=debug .. make sudo checkinstall sudo ldconfig Is done.
2. Installation under Wine.
The advantage of this method is that we immediately get the original functional GUI. The Wine version is not important (Cuneiform worked under Wine 1.0). The only feature: it is necessary to specify a new substitution for the msvcrt library in the Wine settings.
Distribution is available at this link .
Tesseract.
A page about a project on wikipedia .
Page on Google Code .
Declared features: support of multiple languages, output in txt and hocr, training the program with my own examples (I will not consider this, work as is), use of the configuration file for a specific sample.
I briefly and loosely describe this Readme .
Allow dependencies before installation:
sudo apt-get install autoconf automake libtool libpng12-dev libjpeg62-dev libtiff4-dev zlib1g-dev Tesseract also depends on libleptonica-dev version not lower than 1.67. In Squeeze, this package is outdated, so I had to collect it.
We get the source code , unpack and build:
./autobuild ./configure make sudo checkinstall sudo ldconfig Now we get the Tesseract source , unpack it and go to the directory with them.
Next, perform:
./autogen.sh ./configure make sudo checkinstall sudo ldconfig Tesseract is installed. We will receive packages for language recognition: Russian and English - and unpack them into the tessdata directory ( / usr / local / share / tessdata by default).
You can work.
FineReader Engine
An announcement can be viewed here .
How to get? We go here , carefully read and ask for a trial (limit of 100 recognitions). You can ask in Russian .
Installation is simple: download , run under the root abbyyocr.run and follow the text instructions.
Declared features: support for multiple languages, various encodings, work with passwords, page numbering, recognition of tables, bar codes, texts printed on a matrix printer, typewriter, gothic fonts, etc., output in txt, rtf, html, xml, xls.
Rubyquet +
Since I started talking about CLI OCR, I’ll mention CLI Rubyquet + for Tesseract and Cuneiform.
I did not test it (you can do this) - the same CLI for the above-mentioned OCR is available by itself.
OCR CLI comparison
* CLI - command line interface - command line interface (“console”).
I warn you immediately: this section is quite voluminous. If you want to do without unnecessary details and a lot of letters - I recommend not to disclose spoilers.
Remember: I do not claim absolute objectivity of comparison. You may have other results and other conclusions.
I will designate the test criteria.
Of course, the perfect result should be one hundred percent recognition of all characters, formatting and pictures. However, in practice, text recognition is the most popular. The necessary formatting and addition of text with images is able to be made by the user during post-processing.
To assess the quality of recognition, I will introduce the following criteria (although I will depart from them):
The criterion “ Wrong words ” - incorrectly recognized words (from one wrong character in a word up to the complete absence of a word) for simplicity of calculation is the most important criterion.
The criterion of “ Incorrect characters ” - incorrectly recognized characters when it is impossible to use the first criterion (extra characters, punctuation, etc.).
The criterion “ Formatting errors ” is used to determine the quality of work with tables, figures, definition of writing with bold and italic.
For each sample and program, the percentage of correctly recognized words will be calculated, which will be a fundamental factor. The number of words in the sample I will take on the result of recognition in Finereader.
Now about the samples.
What do we most often recognize? Either the documentation passed through the scanner, or a photograph of the document. Naturally, with different quality and resolution (for OCR, scanning is recommended as at least 300 dpi, therefore we compare scanned samples to 200dpi, 300 dpi and 600dpi; for photos, we use photography with 2MP and 5MP quality). In addition, some samples will be tables and pictures.
I will give recognizable images in the form of links to them (their direct presence in the article will only interfere). The recognition result for the first link will be available on Google Docs, the second link with the mark “Original” - in its original form on Dropbox
In order not to clutter up the review, instead of the paths of the original image and the resulting text, I will write INPUT and OUTPUT, respectively.
Sample number 1 (numbered list).
Test sample number 1
It so happened that this list of questions, scanned at 200 dpi (dots per inch), was the first to come to hand and was constantly used in the course of the study.
0001.png
Features of the sample: it is actually divided into 2 columns (numbering and the text itself), the Russian language with several Latin characters.
1. Cuneiform .
Syntax:
Result:
0001.png.cun.rtf
( Original )
Wrong words: 14 (728 words in the text)
Invalid characters: 7
Formatting errors: in some places did not put paragraphs, wrongly entered italics.
Conclusion: the correctness of word recognition is about 98%. The main mistake is confusion with “i” and “n”. In one place he managed to recognize the insert in Latin.
Overall good.
2. Tesseract .
Syntax:
Result (cannot save in RTF):
0001.png.tes.txt
( Original )
Wrong words: 6 (728 words in the text)
Invalid characters: 5
Formatting errors: when outputting to a text file, it is impossible to preserve the formatting of the original, it works better with paragraphs than cuneiform, it cannot technically recognize inserts in the Latin alphabet.
Conclusion: the correctness of word recognition is about 99%. The text looks nicer than with cuneiform.
3. Finereader .
Immediately I will note a big minus: as far as I understood, Finereader works only with superuser rights.
Syntax:
0001.png.fin.rtf
( Original )
Wrong words: 2 (728 words in the text)
Invalid characters: 0
Formatting errors: almost perfect. 2 errors in words - could not recognize the Latin alphabet.
Conclusion: in fact one hundred percent accuracy.
Conclusion on the model number 1 : Finereader takes the first place, Tesseract takes the second place, Cuneiform takes the third place with the minimum margin.
0001.png
Features of the sample: it is actually divided into 2 columns (numbering and the text itself), the Russian language with several Latin characters.
1. Cuneiform .
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Syntax:
-l ruseng - recognize Russian and English in the text (separately, it would be, respectively, rus or eng );-f rtf - RTF output format (trying to save formatting);--singlecolumn - perceive the text as a single column;-o 'OUTPUT' - path to the file with the text;'INPUT' - the path to the image.Result:
0001.png.cun.rtf
( Original )
{kind=link}
Wrong words: 14 (728 words in the text)
Invalid characters: 7
Formatting errors: in some places did not put paragraphs, wrongly entered italics.
Conclusion: the correctness of word recognition is about 98%. The main mistake is confusion with “i” and “n”. In one place he managed to recognize the insert in Latin.
Overall good.
2. Tesseract .
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6Syntax:
-l rus - 2 languages tesseract does not support immediately;-psm 6 - “Assume a single uniform block of text”, i.e. format the received text as a single block (otherwise the numbering will be neatly placed before the whole text - a block after all).Result (cannot save in RTF):
0001.png.tes.txt
( Original )
{kind=link}
Wrong words: 6 (728 words in the text)
Invalid characters: 5
Formatting errors: when outputting to a text file, it is impossible to preserve the formatting of the original, it works better with paragraphs than cuneiform, it cannot technically recognize inserts in the Latin alphabet.
Conclusion: the correctness of word recognition is about 99%. The text looks nicer than with cuneiform.
3. Finereader .
Immediately I will note a big minus: as far as I understood, Finereader works only with superuser rights.
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT'Syntax:
-rl Russian English - Russian and English text.-f RTF - output to RTF.0001.png.fin.rtf
( Original )
{kind=link}
Wrong words: 2 (728 words in the text)
Invalid characters: 0
Formatting errors: almost perfect. 2 errors in words - could not recognize the Latin alphabet.
Conclusion: in fact one hundred percent accuracy.
Conclusion on the model number 1 : Finereader takes the first place, Tesseract takes the second place, Cuneiform takes the third place with the minimum margin.
Sample number 2 (scan English textbook).
Test sample number 2
0002.png
1. Cuneiform .
Result:
0002.png.cun.rtf
( Original )
Wrong words: 2 (534 words in text)
Wrong characters: 6
Formatting errors: recognized footnotes as single quotes, did not cope with square brackets, hyphens and dashes; could not recognize the transcription of the word.
Conclusion: 99% of words. Good.
Version recognized with CuneiformV12 :
0002.cun.win.rtf
( Original )
The result is close to the result of the native version.
2. Tesseract .
Result:
0002.png.tes.txt
( Original )
Wrong words: 1 (534 words in text)
Invalid characters: 4
Formatting errors: found a couple of extra characters, did not cope with footnotes.
Conclusion: 99% of words. Better than cuneiform.
3. Finereader .
Result:
0002.png.fin.rtf
( Original )
Wrong words: 0 (534 words in text)
Invalid characters: 2
Formatting errors: did not recognize one footnote and page number.
Conclusion: 100% of words, recognized italics. Best result.
0003.png
1. Cuneiform .
0003.png.cun.rtf
( Original )
Recognition quality at the same level.
2. Tesseract .
0003.png.tes.txt
( Original )
Suddenly, the quality of recognition has deteriorated. Tesseract managed to recognize horizontal lines as a collection of points and symbols. In addition, extra characters (tildes, single quotes) appeared in the text itself.
3. Finereader .
0003.png.fin.rtf
( Original )
Recognition quality at the same level.
0004.png
1. Cuneiform .
0004.png.cun.rtf
( Original )
Quality has deteriorated. Extra characters appear, hyphens and dashes still do not recognize, have lost the letter “U” in the word “Unit”.
2. Tesseract .
0004.png.tes.txt
( Original )
There is no “Unit 6”, there is no page number, a few extra quotes appeared.
3. Finereader .
0004.png.fin.rtf
( Original )
The page number has appeared, and along with it the horizontal line, which has turned into a set of points. The quality has not improved.
Conclusion based on sample 2 : for all three systems, the image was optimal at 200 dpi quality. With an increase in the density of dots per inch, either there was a deterioration in recognition, or there was simply no progress for the better.
I put Finereader on the first place in quality of work, Tesseract on the second (remember that it does not support RTF), on the third (with a minimal lag) - Cuneiform.
200dpi.
0002.png
1. Cuneiform .
cuneiform -l eng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Result:
0002.png.cun.rtf
( Original )
{kind=link}
Wrong words: 2 (534 words in text)
Wrong characters: 6
Formatting errors: recognized footnotes as single quotes, did not cope with square brackets, hyphens and dashes; could not recognize the transcription of the word.
Conclusion: 99% of words. Good.
Version recognized with CuneiformV12 :
0002.cun.win.rtf
( Original )
The result is close to the result of the native version.
2. Tesseract .
tesseract 'INPUT' 'OUTPUT' -l eng -psm 6Result:
0002.png.tes.txt
( Original )
{kind=link}
Wrong words: 1 (534 words in text)
Invalid characters: 4
Formatting errors: found a couple of extra characters, did not cope with footnotes.
Conclusion: 99% of words. Better than cuneiform.
3. Finereader .
sudo abbyyocr9 -rl English -if 'INPUT' -f RTF -of 'OUTPUT'Result:
0002.png.fin.rtf
( Original )
{kind=link}
Wrong words: 0 (534 words in text)
Invalid characters: 2
Formatting errors: did not recognize one footnote and page number.
Conclusion: 100% of words, recognized italics. Best result.
The same tutorial, 300 dpi.
0003.png
1. Cuneiform .
0003.png.cun.rtf
( Original )
{kind=link}
Recognition quality at the same level.
2. Tesseract .
0003.png.tes.txt
( Original )
{kind=link}
Suddenly, the quality of recognition has deteriorated. Tesseract managed to recognize horizontal lines as a collection of points and symbols. In addition, extra characters (tildes, single quotes) appeared in the text itself.
3. Finereader .
0003.png.fin.rtf
( Original )
{kind=link}
Recognition quality at the same level.
The same tutorial, 600 dpi.
0004.png
1. Cuneiform .
0004.png.cun.rtf
( Original )
{kind=link}
Quality has deteriorated. Extra characters appear, hyphens and dashes still do not recognize, have lost the letter “U” in the word “Unit”.
2. Tesseract .
0004.png.tes.txt
( Original )
{kind=link}
There is no “Unit 6”, there is no page number, a few extra quotes appeared.
3. Finereader .
0004.png.fin.rtf
( Original )
{kind=link}
The page number has appeared, and along with it the horizontal line, which has turned into a set of points. The quality has not improved.
Conclusion based on sample 2 : for all three systems, the image was optimal at 200 dpi quality. With an increase in the density of dots per inch, either there was a deterioration in recognition, or there was simply no progress for the better.
I put Finereader on the first place in quality of work, Tesseract on the second (remember that it does not support RTF), on the third (with a minimal lag) - Cuneiform.
Sample number 3 (photographed English textbook).
Test sample number 3
The main features of this image are the uneven distribution of brightness and possible blurring (“shake” when shooting at long exposures without using a flash)
We will immediately agree that we will not carry out any manual image corrections (except for one example): they both removed it and removed it.
0005.JPG
1. Cuneiform .
0005.JPG.cun.rtf
( Original )
Recognized about 40% of the text, the rest turned into a mess of various characters.
CuneiformV12 under Wine in this image recognized just a couple of words. I do not give an example.
2. Tesseract .
0005.JPG.tes.txt
( Original )
The result is much better than Cuneiform. True recognized about 80% of the text.
3. Finereader .
0005.jpg.fin.rtf
( Original )
Wrong words: 3 (534 words in text)
Invalid characters: 0
Formatting errors: did not recognize one footnote and page number.
Conclusion: 99% accuracy. Fine.
0006.JPG
1. Cuneiform .
0006.JPG.cun.rtf
( Original )
Recognized about 20% of the text, the result is completely useless.
2. Tesseract .
0006.JPG.tes.txt
( Original )
Recognized about 30% of the text.
3. Finereader .
0006.JPG.fin.rtf
( Original )
Recognized about 95% of the text.
0007.JPG
1. Cuneiform .
0007.JPG.cun.rtf
( Original )
Recognized a few words.
2. Tesseract .
0007.JPG.tes.txt
( Original )
Recognized a couple dozen words.
3. Finereader .
0007.JPG.fin.rtf
( Original )
Still, Finereader shows the highest class: about 85% of the text is recognized.
0008.JPG
1. Cuneiform .
0008.JPG.cun.rtf
( Original )
Recognized a couple dozen words.
2. Tesseract .
0008.JPG.tes.txt
( Original )
Recognized about 60% of the text.
3. Finereader .
0008.JPG.fin.rtf
( Original )
Recognized about 95% of the text.
The conclusion is based on sample number 3 : here it becomes clear why the Finereader Engine has a size of about 400 MB: it has image processing algorithms bundled with OCR, due to which it gives a consistently good result when recognizing photos. By means of Cuneiform and Tesseract, it is better not to recognize photos without good preprocessing.
We will immediately agree that we will not carry out any manual image corrections (except for one example): they both removed it and removed it.
5MP with flash.
0005.JPG
1. Cuneiform .
0005.JPG.cun.rtf
( Original )
{kind=link}
Recognized about 40% of the text, the rest turned into a mess of various characters.
CuneiformV12 under Wine in this image recognized just a couple of words. I do not give an example.
2. Tesseract .
0005.JPG.tes.txt
( Original )
{kind=link}
The result is much better than Cuneiform. True recognized about 80% of the text.
3. Finereader .
0005.jpg.fin.rtf
( Original )
{kind=link}
Wrong words: 3 (534 words in text)
Invalid characters: 0
Formatting errors: did not recognize one footnote and page number.
Conclusion: 99% accuracy. Fine.
5MP without flash.
0006.JPG
1. Cuneiform .
0006.JPG.cun.rtf
( Original )
{kind=link}
Recognized about 20% of the text, the result is completely useless.
2. Tesseract .
0006.JPG.tes.txt
( Original )
{kind=link}
Recognized about 30% of the text.
3. Finereader .
0006.JPG.fin.rtf
( Original )
{kind=link}
Recognized about 95% of the text.
About image preprocessing
Let me give you a simple example of the fact that pre-processing of an image will increase the quality of recognition (use imagemagick to increase the contrast by normalizing the previous image):
Result:
0006_2.JPG
1. Cuneiform .
0006_2.JPG.cun.rtf
( Original )
2. Tesseract .
0006_2.JPG.tes.txt
( Original )
You can compare yourself: now the results are definitely better.
convert 'INPUT' -normalize 'OUTPUT'Result:
0006_2.JPG
1. Cuneiform .
0006_2.JPG.cun.rtf
( Original )
{kind=link}
2. Tesseract .
0006_2.JPG.tes.txt
( Original )
{kind=link}
You can compare yourself: now the results are definitely better.
2MP with flash.
0007.JPG
1. Cuneiform .
0007.JPG.cun.rtf
( Original )
{kind=link}
Recognized a few words.
2. Tesseract .
0007.JPG.tes.txt
( Original )
{kind=link}
Recognized a couple dozen words.
3. Finereader .
0007.JPG.fin.rtf
( Original )
{kind=link}
Still, Finereader shows the highest class: about 85% of the text is recognized.
2MP without flash.
0008.JPG
1. Cuneiform .
0008.JPG.cun.rtf
( Original )
{kind=link}
Recognized a couple dozen words.
2. Tesseract .
0008.JPG.tes.txt
( Original )
{kind=link}
Recognized about 60% of the text.
3. Finereader .
0008.JPG.fin.rtf
( Original )
{kind=link}
Recognized about 95% of the text.
The conclusion is based on sample number 3 : here it becomes clear why the Finereader Engine has a size of about 400 MB: it has image processing algorithms bundled with OCR, due to which it gives a consistently good result when recognizing photos. By means of Cuneiform and Tesseract, it is better not to recognize photos without good preprocessing.
Sample No. 4 (recognition of tables and pictures of the scanned image).
Test sample number 4
Picture:
0009.png
1. Cuneiform .
0009.png.cun.rtf
( Original )
Conclusion: failed.
At the same time, CuneiformV12 for Wine gives a good result (lost half of the image, but coped with the table).
0009.cun.wine.rtf
( Original )
2. Tesseract
Unfortunately, it cannot give formatted text.
3. Finereader .
0009.png.fin.rtf
( Original )
When I opened this document in Writer, I was very surprised: there was no table (strange: a difference in the implementation of such an old and simple format as RTF? ..). However, Word and Google Docs opened this RTF correctly.
Finereader did an excellent job with both the picture and the table.
The conclusion is based on sample number 4 : Finereader is in the first place, CuneiformV12 is in the first place (native Cuneiform did not cope with the task).
0009.png
1. Cuneiform .
cuneiform -l ruseng -f rtf -o 'OUTPUT' 'INPUT'0009.png.cun.rtf
( Original )
{kind=link}
Conclusion: failed.
At the same time, CuneiformV12 for Wine gives a good result (lost half of the image, but coped with the table).
0009.cun.wine.rtf
( Original )
2. Tesseract
Unfortunately, it cannot give formatted text.
3. Finereader .
0009.png.fin.rtf
( Original )
{kind=link}
When I opened this document in Writer, I was very surprised: there was no table (strange: a difference in the implementation of such an old and simple format as RTF? ..). However, Word and Google Docs opened this RTF correctly.
Finereader did an excellent job with both the picture and the table.
The conclusion is based on sample number 4 : Finereader is in the first place, CuneiformV12 is in the first place (native Cuneiform did not cope with the task).
Sample No. 5 (scanned textbook “Metal constructions”).
Test sample number 5
0010.png
1. Cuneiform .
Result:
0010.png.cun.rtf
( Original )
Wrong words: 17 (310 words in the text)
Invalid characters: 12
Formatting errors: did not recognize dashes, paragraph signs and percents. Problems with the recognition of "Y". Mistakenly recognized italics.
Conclusion: 95% of words. It does not look very much.
Version recognized with CuneiformV12 :
0010.cun.win.rtf
( Original )
The quality is clearly higher than that of the native version.
2. Tesseract .
Result:
0010.png.tes.txt
( Original )
Incorrect words: 8 (310 words in the text)
Invalid characters: 15
Formatting errors: problems with “J” recognition.
Conclusion: 97% of words. Better than cuneiform.
3. Finereader .
Result:
0010.png.fin.rtf
( Original )
Incorrect words: 0 (310 words in the text)
Invalid characters: 5
Formatting errors: problems with capitalization of characters.
Conclusion: 100% of words. Best result.
0012.png
1. Cuneiform .
0012.png.cun.rtf
( Original )
Unlike the previous result, more “Y” and Roman numerals appeared. For some of the words, recognition has improved, but at the same time new errors and unnecessary characters have appeared.
Conclusion: there are no fewer errors.
2. Tesseract .
0012.png.tes.txt
( Original )
Conclusion: the situation as in the case of Cuneiform: no less errors.
3. Finereader .
0012.png.fin.rtf
( Original )
Conclusion: nothing has changed.
0011.png
Both Cuneiform and Tesseract showed a decrease in the quality of recognition, as is the case with the English-speaking sample. I do not give examples (you can check it yourself).
Conclusion based on sample 5 : it was confirmed that the use of an image with a quality of more than 200 dpi does not lead to an improvement in the result.
The first place is occupied by Finereader, the second - by Tesseract, the third - by Cuneiform (and it works better under Wine).
200dpi.
0010.png
1. Cuneiform .
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Result:
0010.png.cun.rtf
( Original )
{kind=link}
Wrong words: 17 (310 words in the text)
Invalid characters: 12
Formatting errors: did not recognize dashes, paragraph signs and percents. Problems with the recognition of "Y". Mistakenly recognized italics.
Conclusion: 95% of words. It does not look very much.
Version recognized with CuneiformV12 :
0010.cun.win.rtf
( Original )
The quality is clearly higher than that of the native version.
2. Tesseract .
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6Result:
0010.png.tes.txt
( Original )
{kind=link}
Incorrect words: 8 (310 words in the text)
Invalid characters: 15
Formatting errors: problems with “J” recognition.
Conclusion: 97% of words. Better than cuneiform.
3. Finereader .
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT'Result:
0010.png.fin.rtf
( Original )
{kind=link}
Incorrect words: 0 (310 words in the text)
Invalid characters: 5
Formatting errors: problems with capitalization of characters.
Conclusion: 100% of words. Best result.
300dpi.
0012.png
1. Cuneiform .
0012.png.cun.rtf
( Original )
{kind=link}
Unlike the previous result, more “Y” and Roman numerals appeared. For some of the words, recognition has improved, but at the same time new errors and unnecessary characters have appeared.
Conclusion: there are no fewer errors.
2. Tesseract .
0012.png.tes.txt
( Original )
{kind=link}
Conclusion: the situation as in the case of Cuneiform: no less errors.
3. Finereader .
0012.png.fin.rtf
( Original )
{kind=link}
Conclusion: nothing has changed.
600dpi.
0011.png
Both Cuneiform and Tesseract showed a decrease in the quality of recognition, as is the case with the English-speaking sample. I do not give examples (you can check it yourself).
Conclusion based on sample 5 : it was confirmed that the use of an image with a quality of more than 200 dpi does not lead to an improvement in the result.
The first place is occupied by Finereader, the second - by Tesseract, the third - by Cuneiform (and it works better under Wine).
Sample # 6 (scanned O'Henry story page).
Test sample number 6
0013.png
1. Cuneiform .
0013.png.cun.rtf
( Original )
Wrong words: 28 (316 words in text)
Invalid characters: set.
Formatting errors: wrong italics.
Conclusion: 91% of words, a lot of mistakes, which is unacceptable for such a sample.
And the version recognized by CuneiformV12 :
0013.cun.win.rtf
( Original )
Incorrect words: 15 (316 words in the text)
Invalid characters: several.
Formatting errors: no.
Conclusion: 95% of words, the result is better than the native version.
2. Tesseract .
0013.png.tes.txt
( Original )
Incorrect words: 30 (316 words in the text)
Invalid characters: set.
Formatting errors: extra characters.
Conclusion: 90% of words are bad.
3. Finereader .
0013.png.fin.rtf
( Original )
Incorrect words: 3 (316 words in text)
Invalid characters: no.
Formatting errors: no.
Conclusion: 99% of words.
The conclusion is based on sample number 6 : Cuneiform and Tesseract have the same type of recognition errors of the letters “i”, “n” and “n” from the sample font.
First place - Finereader, second - Cuneiform under Wine (native Cuneiform worked worse), third - Tesseract.
200dpi.
0013.png
1. Cuneiform .
0013.png.cun.rtf
( Original )
{kind=link}
Wrong words: 28 (316 words in text)
Invalid characters: set.
Formatting errors: wrong italics.
Conclusion: 91% of words, a lot of mistakes, which is unacceptable for such a sample.
And the version recognized by CuneiformV12 :
0013.cun.win.rtf
( Original )
Incorrect words: 15 (316 words in the text)
Invalid characters: several.
Formatting errors: no.
Conclusion: 95% of words, the result is better than the native version.
2. Tesseract .
0013.png.tes.txt
( Original )
{kind=link}
Incorrect words: 30 (316 words in the text)
Invalid characters: set.
Formatting errors: extra characters.
Conclusion: 90% of words are bad.
3. Finereader .
0013.png.fin.rtf
( Original )
{kind=link}
Incorrect words: 3 (316 words in text)
Invalid characters: no.
Formatting errors: no.
Conclusion: 99% of words.
The conclusion is based on sample number 6 : Cuneiform and Tesseract have the same type of recognition errors of the letters “i”, “n” and “n” from the sample font.
First place - Finereader, second - Cuneiform under Wine (native Cuneiform worked worse), third - Tesseract.
Sample №7 (scanned page of the book "The Moment of Truth").
Test sample number 7
0014.png
1. Cuneiform .
0014.png.cun.rtf
( Original )
Wrong words: 11 (323 words in the text)
Invalid characters: persistently does not recognize hyphens and dashes.
Formatting errors: wrong italics.
Conclusion: 91% of words, bad.
And the version recognized by CuneiformV12:
0014.cun.win.rtf
( Original )
Wrong words: 1 (323 words in the text)
Invalid characters: 1.
Formatting errors: no.
Conclusion: 99% of words, great.
2. Tesseract .
0014.png.tes.txt
( Original )
Wrong words: 30 percent.
Invalid characters: set.
Formatting errors: extra characters.
Conclusion: disgusting.
3. Finereader .
0014.png.fin.rtf
( Original )
Incorrect words: 0 (323 words in the text)
Invalid characters: no.
Formatting errors: no.
Conclusion: 100% of words. Perfect.
Conclusion on the model number 7 : First place - Finereader, second - Cuneiform under Wine (native Cuneiform worked much worse), third - Tesseract (the result is useless even to correct).
200dpi.
0014.png
1. Cuneiform .
0014.png.cun.rtf
( Original )
{kind=link}
Wrong words: 11 (323 words in the text)
Invalid characters: persistently does not recognize hyphens and dashes.
Formatting errors: wrong italics.
Conclusion: 91% of words, bad.
And the version recognized by CuneiformV12:
0014.cun.win.rtf
( Original )
Wrong words: 1 (323 words in the text)
Invalid characters: 1.
Formatting errors: no.
Conclusion: 99% of words, great.
2. Tesseract .
0014.png.tes.txt
( Original )
{kind=link}
Wrong words: 30 percent.
Invalid characters: set.
Formatting errors: extra characters.
Conclusion: disgusting.
3. Finereader .
0014.png.fin.rtf
( Original )
{kind=link}
Incorrect words: 0 (323 words in the text)
Invalid characters: no.
Formatting errors: no.
Conclusion: 100% of words. Perfect.
Conclusion on the model number 7 : First place - Finereader, second - Cuneiform under Wine (native Cuneiform worked much worse), third - Tesseract (the result is useless even to correct).
Sample №8 (Pangram with different fonts).
Test sample number 8
Finally, the last test, which reveals the dependence of OCR on the font (the original is printed on an inkjet printer with medium quality).
In this example, for clarity, if necessary, I will correct the paragraphs and font names.
0015.png
1. Cuneiform .
Russian text:
0015_rus.png.cun.txt
( Original )
Without errors (not counting the ill-fated hyphen), only Arial and Trebuchet MS are recognized.
English text:
0015_eng.png.cun.txt
( Original )
Errors only in Courier New and ISOCPEUR.
CuneiformV12 :
Russian text:
0015_rus.wine.cun.txt
( Original )
No errors are recognized by Sans-serif, Arial, Courier New, DejaVu Sans, DejaVu Serif, Palladio Uralic, Trebuchet MS, Verdana.
The difference compared to ported Cuneiform is obvious.
English text:
0015_eng.wine.cun.txt
( Original )
Suddenly, there are three times more mistakes than in the native version.
2. Tesseract .
Russian text:
0015_rus.png.tes.txt
( Original )
Errors (again, not counting problems with hyphens) are only in Palladio Uralic, Verdana and ISOCPEUR.
English text:
0015_eng.png.tes.txt
( Original )
No errors.
Conclusion based on sample number 8 : CuneiformV12 (under Wine) and Tesseract worked best with Russian. Tesseract coped with English without mistakes.
In this example, for clarity, if necessary, I will correct the paragraphs and font names.
200dpi.
0015.png
1. Cuneiform .
Russian text:
0015_rus.png.cun.txt
( Original )
{kind=link}
Without errors (not counting the ill-fated hyphen), only Arial and Trebuchet MS are recognized.
English text:
0015_eng.png.cun.txt
( Original )
{kind=link}
Errors only in Courier New and ISOCPEUR.
CuneiformV12 :
Russian text:
0015_rus.wine.cun.txt
( Original )
No errors are recognized by Sans-serif, Arial, Courier New, DejaVu Sans, DejaVu Serif, Palladio Uralic, Trebuchet MS, Verdana.
The difference compared to ported Cuneiform is obvious.
English text:
0015_eng.wine.cun.txt
( Original )
Suddenly, there are three times more mistakes than in the native version.
2. Tesseract .
Russian text:
0015_rus.png.tes.txt
( Original )
{kind=link}
Errors (again, not counting problems with hyphens) are only in Palladio Uralic, Verdana and ISOCPEUR.
English text:
0015_eng.png.tes.txt
( Original )
{kind=link}
No errors.
Conclusion based on sample number 8 : CuneiformV12 (under Wine) and Tesseract worked best with Russian. Tesseract coped with English without mistakes.
GUI for Linux.
* GUI - graphical user interface - a graphical interface (“windows and buttons”).
Yagf
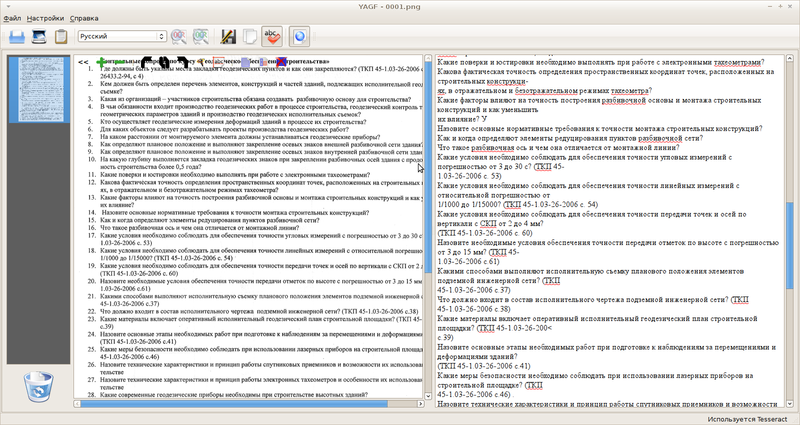
Official page.
Dependencies when building: libaspell-dev and libqt4-dev version 4.5 or later. Qt 4.5 and aspell are needed to run (see the documentation that comes with the source).
Installation (start in the source directory):
mkdir builddir cd build dir cmake ../ make sudo checkinstall Yagf is well localized, can get an image from the clipboard, from a file, from a scanner, import pdf, allows you to align the image.
In the Yagf settings, you can switch between Tesseract and Cuneiform. Yagf can produce batch recognition (all imported images) or recognition of a specific text area.
The only significant disadvantage I consider is the impossibility of setting additional parameters for scan engines, i.e. similar to the command line (OCRFeeder, discussed below, does not have this drawback).
Cuneiform-qt
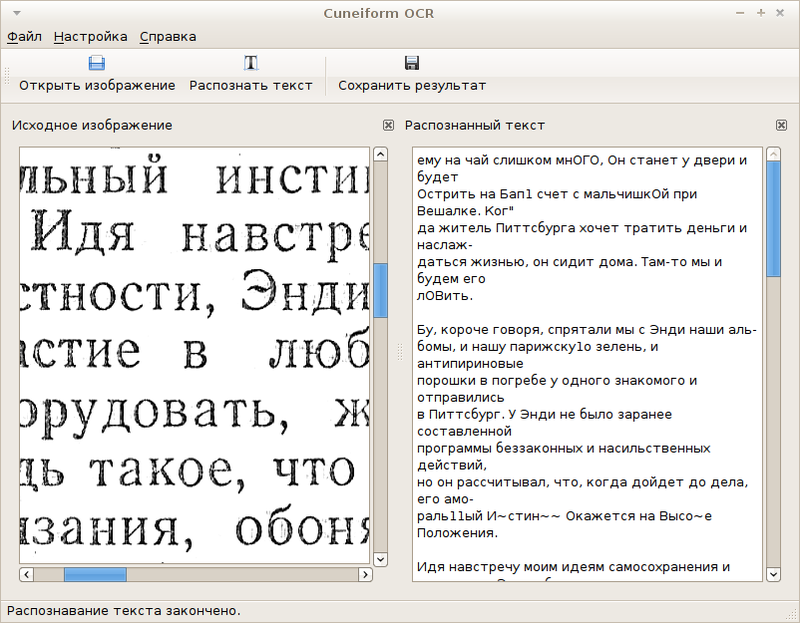
The project began and ended its active life in April 2009 as part of the Altlinux project. Cuneiform-Qt provides a simple GUI for Cuneiform.
Since I didn’t expect anything special from this GUI, I decided to limit myself to installing the ready-made package version 0.1.1-1 (the latest source version 0.1.2 - the development was not far).
The GUI, by the way, turned out to be very interesting - when it was saved in RTF, the recognized text turned into a sequence of several Latin characters repeated hundreds of times, arranged in a column one letter wide. In a plain text file, the save is normal.
We conclude: this GUI is useless.
KBookOCR
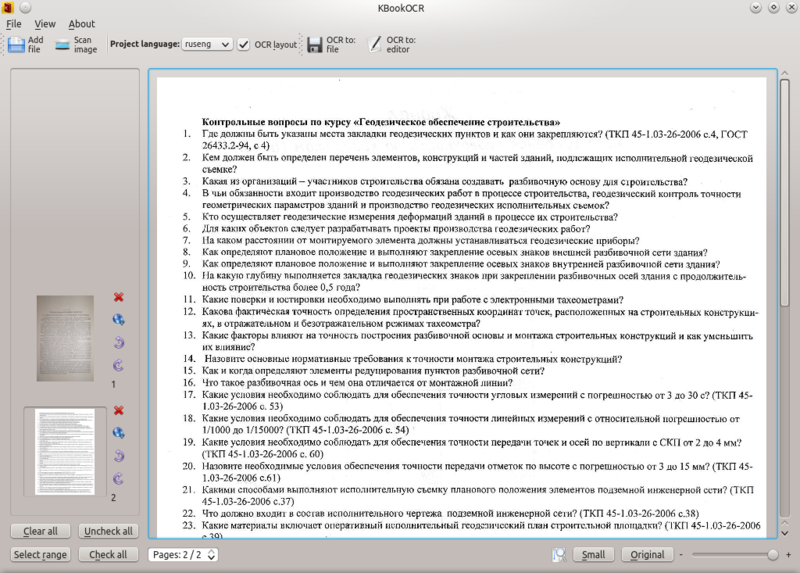
This was announced on Habré “killer Finereader'a”, which is a superstructure over Cuneiform.
Official blog of the author.
Deb package.
Unfortunately, in dependencies pulls a piece of KDE.Version 2.2, planned over a year ago, implies Tesseract support, but there seems to be no progress.
For the review, I used Kubuntu 12.04 in Virtualbox.
Version 2.1 of this software can get an image from a file or by scanning, display the result in html or open it in a text editor. To distinguish blocks for recognition, KBookOcr, unlike Yagf, does not know how.
Conclusion: KBookOcr loses Yagf in terms of functionality and is intended only for KDE.
OCRFeeder

GUI for Cuneiform, Tesseract and a pair of other OCRs that do not support Russian. In deb-packages are presented only very old versions, so we will collect from the source code .
Immediately there is an irritation: Readme is written to version 0.3, the current version is 0.7.1. The file structure has changed, there is no required setup.py. But there is ./confugure
Dependencies:
sudo apt-get install python-pygoocanvas ocrad unpaper python-gtkspell python-enchant sane python-imaging-sane Further, it turns out that:
Your intltool is too old. You need intltool 0.35.0 or later.
The old intltool-debian package is installed by default : we put the intltool version 0.41 package from the repository .
We collect:
./confugure make sudo checkinstall The set of functions is standard: open / scan, save / open in the editor. There are several bonuses: unpaper is supported, the settings of the recognition engine allow you to transfer to it in text form any supported parameters (for example, the choice of the recognition language is done this way); You can select text blocks.
Ocropus
http://code.google.com/p/ocropus/ - either GUI or Tesseract CLI.
Following the instructions, I tried to build the latest version, but python said about some source line:
SyntaxError: invalid syntaxI don’t want to go into the code, I conclude that the product is more dead than alive.
gImageReader

Tesseract GUI.
Take the deb package from here .
gImageReader is as simple as possible: it allows you to open an image, adjust brightness and contrast on the go and recognize the text area or all at once.
Tesseract-gui
Project page.
Packages lie here .
I refused to recognize anything.
Conclusion about the GUI :
The only real advantage presented by the GUI may be the recognition function of individual text blocks (some cannot and this).
Therefore, I believe that the existing Linux OCR GUIs are not functional. If we choose among them, then in fact the only acceptable will be only two: Yagf and OCRFeeder. At the same time, the Yagf community is used and mentioned much more often.
Try and leave your impressions.
Online-OCR test
A small list of online-OCR .
Online OCR is very much, and, in principle, they are all implemented on the three engines listed above: Cuneiform , Tesseract and Finereader .
Since the OCR data falls under the topic of this article, we consider a couple of them, at the same time we will draw interesting conclusions.
1. Finereader Online .
finereader.abbyyonline.com/ru
Clearly based on Finereader Engine 9 (or maybe 10?) I did not try, I am sure of high quality.
Allows you to recognize 10 pages per day for free.
2. New OCR .
www.newocr.com
Free, does not require registration and has no restrictions.
A very interesting resource that will allow you to draw conclusions about the ultimate applicability of Cuneiform and Tesseract . Load the images with which these two systems have problems, and look at the result.
Sample No. 3, 5MP without flash
Recognition with Cuneiform :
0006.cun.newocr.txt
( Original )
Recognition with Tesseract :
0006.tes.newocr.txt
( Original )
The online recognition results are obviously better.
Sample # 7
Recognition with Cuneiform :
0014.cun.newocr.txt
( Original )
There are not enough hyphens and dashes, however, there are only 2 errors in the words. Excellent result.
Recognition with Tesseract :
0014.tes.newocr.txt
( Original )
6 errors in words, a few extra characters - but Tesseract in my image could not recognize normal text. Perhaps the most interesting test result.
Here's a great example of using free OCR: the site creators explicitly applied image pre-processing and (possibly) text post-processing (adjustments using dictionaries or something like that). And in this form, free OCRs can already compete with Finereader.
Conclusion
We considered three OCR systems that can work with Russian and English.
Without a doubt, FineReader Engine v9.0 showed the best result. It perfectly recognizes both scanned and photographed images. However, its minimum cost is € 149 for a license for 12,000 recognitions per year - do you need this?
Free OCR: Cuneiform and Tesseract - by themselves can only adequately process scanned images with uniformly distributed across the field brightness and high contrast.
Both engines coped well with the English-speaking sample, while problems arose with the Russian text - in general, during the test, it turned out that the results of the work of free OCR "float" from sample to sample.
At the same time, CuneiformV12, running under Wine, coped with Russian texts better than the native version under Linux.
Interesting was the fact that, on the examined samples, the optimal image quality was 200 dpi - with a higher number of dots per inch, the quality of recognition began to deteriorate.
The Cuneiform and Tesseract GUIs are many, but they don’t bring real value.
On the example of FineReader and the online system New OCR, it is clearly seen that a normal functional OCR must necessarily exist in conjunction with an image preprocessing system and a text post-processing system based on vocabulary control of the results.
At the same time, this technology for free engines has actually been implemented (in New OCR, recognition is very high quality).
It is enough to share such technology or implement it yourself - and the free OCR will be on the same level with ABBYY products - after that you can talk about writing a good GUI.
To summarize: free OCRs do not provide a stable result even on scanned images, Finereader costs money - it is easier for a simple user to use online services.
Well, if you are going to use OCR on a different scale, there’s a different conversation: you have to pay or spend time adjusting the results manually.
PS If you have ready-made ideas or scripts for preparing an image for recognition - share in the comments. Everyone will be interesting and useful.
Source: https://habr.com/ru/post/153617/
All Articles