RabbitMQ message processing optimization
As part of working tasks, I recently conducted a small study on the feasibility of using the prefetchCount option when working with the RabbitMQ message broker.
I want to share this material in the form of slides and comments to them.
Tests were conducted on a specific project , but in general they are valid for most cases where the processing of messages (execution of tasks) takes at least some substantial time (when processing less than 1000 messages per second).
* on the slides, instead of the word “subscriber”, “consumer” is used, in the comments for uniformity too
* a single queue with five buckets is considered (C1..C5)
')
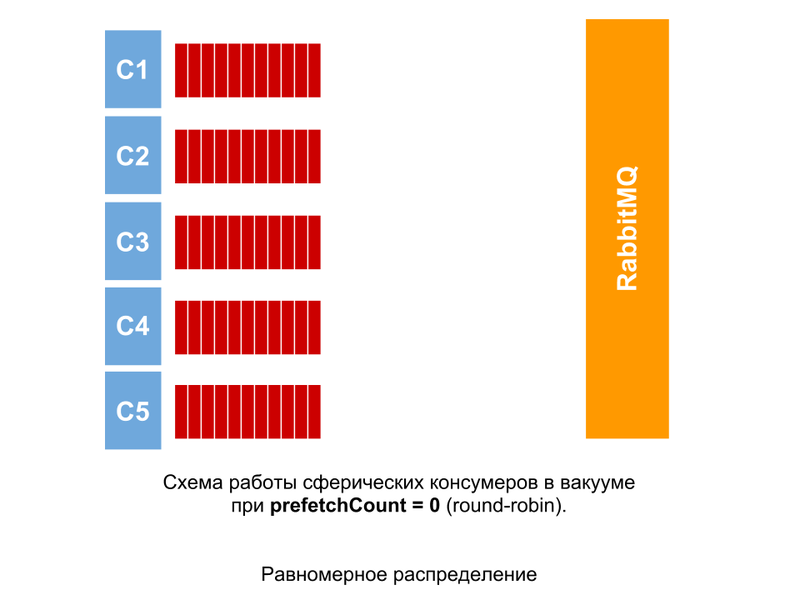
Such a picture could be observed if the processing of all messages took an absolutely equal amount of time. With prefetchCount = 0, messages are distributed to consumers in turn, regardless of how many messages are not acknowledged.
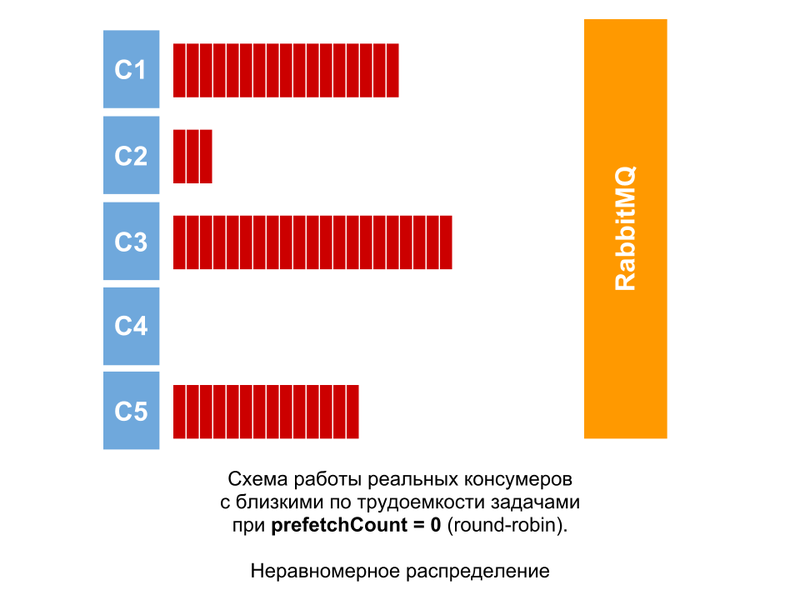
In fact, tasks will always differ in labor intensity, even if only slightly. Therefore, even if they are equal (very close), the picture will be approximately the same. The difference in the number of unconfirmed messages among consumers will grow, if not all of them manage to process their messages.

If tasks can differ significantly in terms of complexity [for example, our project has a variation in a couple of orders] , then upon receipt of a message, the processing of which will take a long time, the number of unacknowledged messages will accumulate. Visually (monitoring the queue) it seems that the messages hang, because free consumer processors process new messages instantly, and busy messages accumulate. These messages will not be given to other consumers for processing, unless the connection with the processing [in the diagram - C4] falls off. Also in this case, there are significant downtime for free consumers.

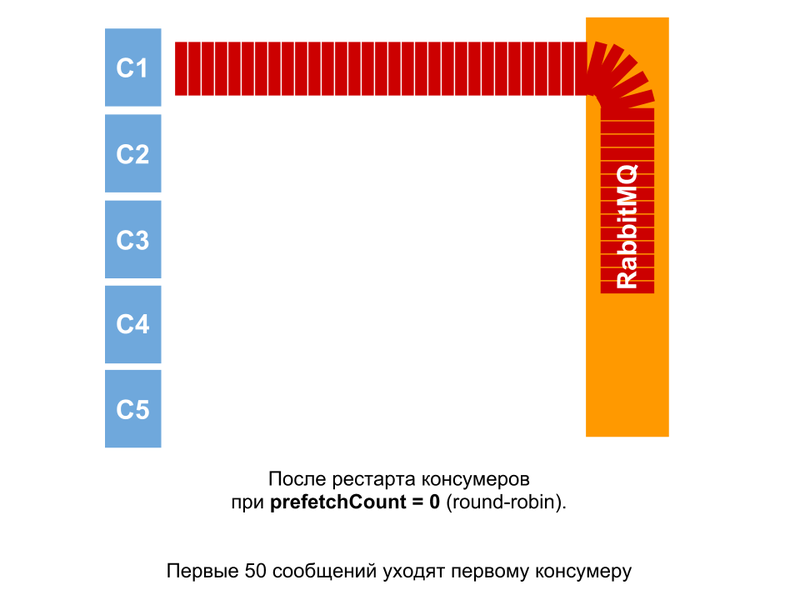
But where things are more interesting, when there are messages in the queue, and the consumers are restarted (or just the first launch). Konsumery start together, but all the same with a minimum time interval. And therefore, as soon as the first one is launched, it immediately receives a packet of messages (since at this moment there are no other consumers). By a large number of experiments, the number 50 was revealed. Further, messages are distributed evenly.
In a situation when there is a message in the queue, when the consumer starts, one of them receives it. When after this comes another message, it is sent to the same consumer. The reason for this may be a reset of the pointer, since the number of consumers has changed since the transfer to processing the first message.
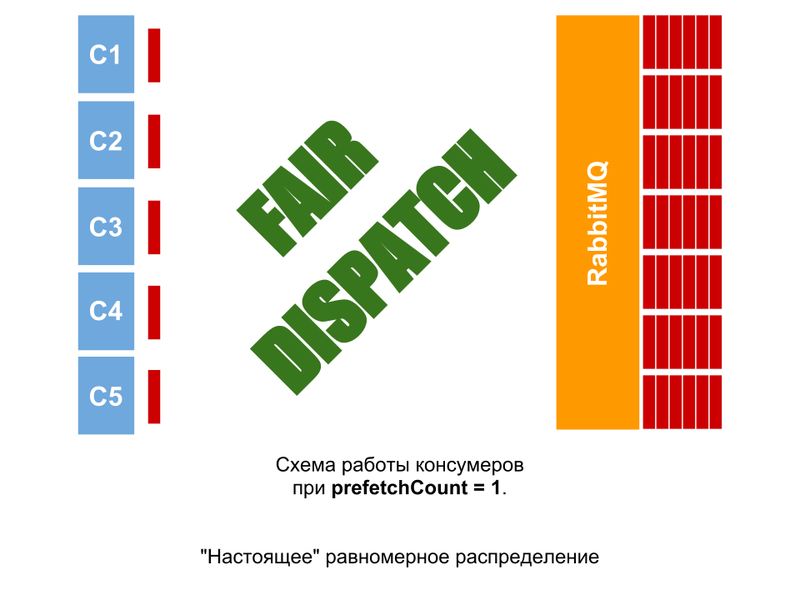
When using the prefetchCount = n option [in the example n = 1, but maybe 2, 5, 10 ...], the consumer does not receive the next n messages until he confirms the previous ones. Thus you can get a uniform workload, regardless of the uniformity of the complexity of the tasks. There will not be a situation when there are messages in the queue, and some consumer measures are idle (if there is no i in the queue, there will be no more than n messages to the consumer).

But not everything is so simple. The smaller the prefetchCount value, the lower the performance of the RabbitMQ (the value 0 corresponds to infinity and the graph is close to the value 10,000). This schedule is taken from the official site .
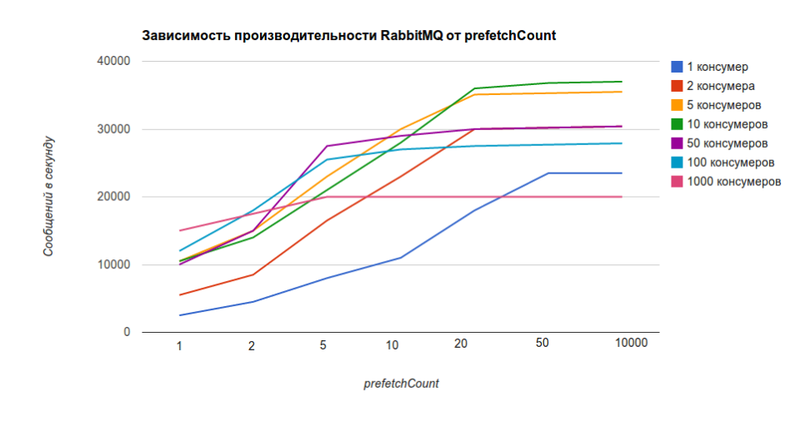
The same graph, only dependence on the value of prefetchCount, and not on the number of consumers.
It shows that with 5 consumers for prefetchCount = 1, RabbitMQ can send 10k messages per second, and for prefetchCount = 0 , 36k messages per second, which is 3.6 times more.
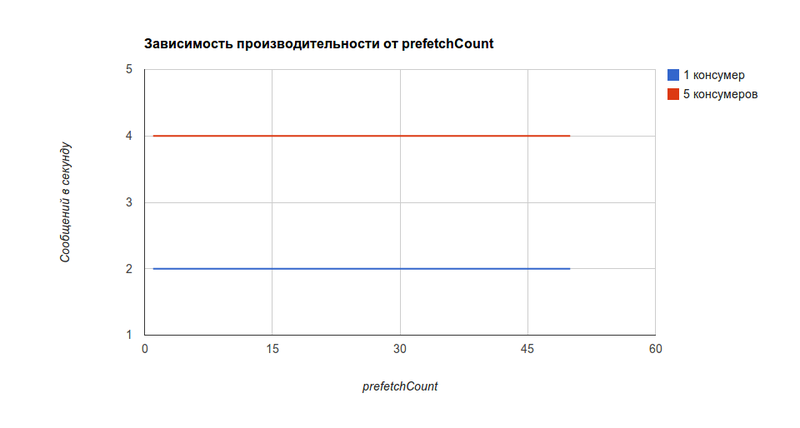
But in most cases the bottleneck will not be the performance of RabbitMQ, but the performance of consumers (lower by several orders of magnitude). On the project under test, there was such a dependence (or rather, its absence) on the value of the prefetchCount [it will be valid, as I have already mentioned, for consumers who process less than 1000 messages per second] .

At the same time, the dependence of performance on the number of consumers [on our project] turned out to be similar, but it really depends on the resource intensity of the consumers themselves, the server's performance, whether the consumers are separated across different servers, etc.

The maximum loss due to the use of prefetchCount = 1 (compared to the ideal conditions from the first slide) is 0.03%. At the same time, the expected time gain due to uniform distribution and less downtime will be about 50..100% (1.5..2 times), because in a real queue with prefetchCount = 0 , the message processing time is often reduced to the operating time of one of the co-consumers because of the rest of the idle (as in the third slide). Also the queue moves more predictably, and there are no “freeze” effects.
[by itself, for other projects, the numbers will be different]
The results of your tests and observations related to prefetchCount, I propose to share in the comments.
I want to share this material in the form of slides and comments to them.
Tests were conducted on a specific project , but in general they are valid for most cases where the processing of messages (execution of tasks) takes at least some substantial time (when processing less than 1000 messages per second).
* on the slides, instead of the word “subscriber”, “consumer” is used, in the comments for uniformity too
* a single queue with five buckets is considered (C1..C5)
')
Ideal conditions
Such a picture could be observed if the processing of all messages took an absolutely equal amount of time. With prefetchCount = 0, messages are distributed to consumers in turn, regardless of how many messages are not acknowledged.
Equal Tasks
In fact, tasks will always differ in labor intensity, even if only slightly. Therefore, even if they are equal (very close), the picture will be approximately the same. The difference in the number of unconfirmed messages among consumers will grow, if not all of them manage to process their messages.
Unequal tasks
If tasks can differ significantly in terms of complexity [for example, our project has a variation in a couple of orders] , then upon receipt of a message, the processing of which will take a long time, the number of unacknowledged messages will accumulate. Visually (monitoring the queue) it seems that the messages hang, because free consumer processors process new messages instantly, and busy messages accumulate. These messages will not be given to other consumers for processing, unless the connection with the processing [in the diagram - C4] falls off. Also in this case, there are significant downtime for free consumers.
Epic fail
Restart
But where things are more interesting, when there are messages in the queue, and the consumers are restarted (or just the first launch). Konsumery start together, but all the same with a minimum time interval. And therefore, as soon as the first one is launched, it immediately receives a packet of messages (since at this moment there are no other consumers). By a large number of experiments, the number 50 was revealed. Further, messages are distributed evenly.
In a situation when there is a message in the queue, when the consumer starts, one of them receives it. When after this comes another message, it is sent to the same consumer. The reason for this may be a reset of the pointer, since the number of consumers has changed since the transfer to processing the first message.
Fair dispatch
When using the prefetchCount = n option [in the example n = 1, but maybe 2, 5, 10 ...], the consumer does not receive the next n messages until he confirms the previous ones. Thus you can get a uniform workload, regardless of the uniformity of the complexity of the tasks. There will not be a situation when there are messages in the queue, and some consumer measures are idle (if there is no i in the queue, there will be no more than n messages to the consumer).
Performance RabbitMQ
But not everything is so simple. The smaller the prefetchCount value, the lower the performance of the RabbitMQ (the value 0 corresponds to infinity and the graph is close to the value 10,000). This schedule is taken from the official site .
The same graph, only dependence on the value of prefetchCount, and not on the number of consumers.
It shows that with 5 consumers for prefetchCount = 1, RabbitMQ can send 10k messages per second, and for prefetchCount = 0 , 36k messages per second, which is 3.6 times more.
Consumer performance
But in most cases the bottleneck will not be the performance of RabbitMQ, but the performance of consumers (lower by several orders of magnitude). On the project under test, there was such a dependence (or rather, its absence) on the value of the prefetchCount [it will be valid, as I have already mentioned, for consumers who process less than 1000 messages per second] .
At the same time, the dependence of performance on the number of consumers [on our project] turned out to be similar, but it really depends on the resource intensity of the consumers themselves, the server's performance, whether the consumers are separated across different servers, etc.
findings
The maximum loss due to the use of prefetchCount = 1 (compared to the ideal conditions from the first slide) is 0.03%. At the same time, the expected time gain due to uniform distribution and less downtime will be about 50..100% (1.5..2 times), because in a real queue with prefetchCount = 0 , the message processing time is often reduced to the operating time of one of the co-consumers because of the rest of the idle (as in the third slide). Also the queue moves more predictably, and there are no “freeze” effects.
[by itself, for other projects, the numbers will be different]
The results of your tests and observations related to prefetchCount, I propose to share in the comments.
Source: https://habr.com/ru/post/153431/
All Articles