Electronic cards for learning English words
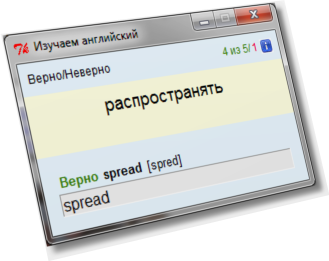 I want to share with a respected habrasoobschestvom another bike, to replenish the English vocabulary. He is a classic card for self-study of words: you are offered a word in Russian or English, you enter a translation. I will not describe the advantages of the methodology, just to remind you that the formation of vocabulary is one of the first stages of learning a language — laying the foundation for further, fuller learning.
I want to share with a respected habrasoobschestvom another bike, to replenish the English vocabulary. He is a classic card for self-study of words: you are offered a word in Russian or English, you enter a translation. I will not describe the advantages of the methodology, just to remind you that the formation of vocabulary is one of the first stages of learning a language — laying the foundation for further, fuller learning.The program is very simple, but it has a number of features that distinguish it from those that I tried before taking on my own implementation. If you are too lazy to read the detailed description, you can immediately go to github , where the script is laid out and get acquainted with it, there is also a readme with a description of the possibilities, in a more concise form.
And now I will try to tell you why it took me and what actually did not suit the existing programs and services.
Special features
The first and most important is time.
All language learning services that I have tried, the same widely known lingualeo, require that they be allocated at least 30 minutes each, and at the same time. The services themselves are arranged in such a way that it makes no sense to go there 10 times a day for a couple of minutes, then you just can't do anything. Offline programs behave from the point of view of time as well - a lesson includes a set of exercises for translating words from Russian into English, reverse translation, choice of translation from the proposed options, etc. and the lesson needs to be completed, otherwise it simply does not count. The consequences are sad, at least for me. At work - conscience does not allow to allocate 30 minutes, and at home - there is always no time. Sometimes, of course, after reading the next motivating article, enthusiasm flares up, but after a month it subsides, and you begin to postpone the lesson for later, for tomorrow, you promise yourself to start practicing Monday every day ... and gradually you come to the resource less and less often, and then you throw it away.')
Therefore, it was decided that we need a program that will take a minimum amount of time and remind of itself. It looks very simple - a window pops up, you are consistently offered to translate a few words, after 5 correct answers - the program ends. After 30 minutes, it starts up again. Enter 5 correct answers, especially with the skills of blind typing - takes a minute to do, which allows you to study at home and at work (conscience allows you to spend a couple of minutes per hour). If at the moment you are doing some important work - the window is minimized and the program calms down without distracting from the task, you can take a lesson later during the inevitable breaks. Anyway, sooner or later everyone will be distracted from work for tea, lunch or something.
Thus we get: private repetitions of lessons with minimal time costs for each individual lesson, plus reminders that it would be nice to repeat the words.
Next - a set of words to learn.
For some reason, all applications consider that after I have completed the necessary minimum of the number of correct answers for a word, then it should be noted learned and no longer think about it. Yes, I forget it so sooner or later! I have never understood the division of words in thematic dictionaries. In the same client wordsteps for phones - you have a set of dictionaries, each with about 50 words, for a lesson you choose a dictionary, you are banished to this dictionary part and depending on how well you think the program has learned or another word, it is marked to repeat every other day, two, a week, etc. As a result, I accumulate about five different dictionaries and each contains only 2-3 words marked for repetition today, and I have to look through all the dictionaries to find those that have the number of words they need for the lesson. Opportunities to somehow merge dictionaries, at least in the telephone client, do not.As a solution, the format was chosen as one large dictionary. As soon as words run out in it, we simply add new ones to the end. And for the lesson, the words are selected as follows: we form a set of 50 pieces, which we began to study and add all the studied ones. Each of the words is given a rating, depending on how long the word was repeated, what percentage of the correct answers on it, whether you translated it correctly last time, etc., as a result, the worse you know the word, the higher the rating is. Then, the word that will be proposed for translation is randomly selected from the list, and the higher the rating is, the greater the likelihood that it will be offered to you. The studied words, of course, receive a rating that is much lower than those that are being studied, but nevertheless, sooner or later, you will repeat them, and if you repeat many mistakes during repetition, they will again become unexplored. Statistics for calculating the rating is conducted separately for each of the translation directions: Ru-> En and En-> Ru. Moreover, when you need to choose a new word for study, for example, from Russian to English, first of all take words that have been studied or are being studied in a different direction of translation, so that it would not happen that you learned to translate Russian into English from the first half of the dictionary, and from english to russian second.
As a result, we have - one large dictionary, each word of which is systematically and consistently studied, and then periodically repeated.
The following is a dictionary.
If I decide to create my own dictionary for study, most programs will provide me with a “convenient” GUI interface, where I will slowly but surely enter words one at a time. Which is very, in my opinion, inconvenient, especially if I want to add immediately a set of 100 pieces that I found somewhere on the Internet on topics of interest to me. And I don’t even want to talk about the possibility of “customizing” the translation, it’s good if they allow you to enter several possible translations separated by commas, and the register will be ignored when responding. And all - no more opportunities.For these reasons, the GUI interface to replenish the dictionary was rejected, and the dictionary itself was placed in a simple text file in json format, where there is nothing superfluous, only the comma, word, transcription and translation are indicated. Now, as soon as we find the next page on the Internet with a thousand of the most frequently used words of the English language, we simply copy it, paste it into any editor, preferably with block editing support, for example, in sublime text and bring it to the required format in 5-10 minutes. Editing words later is also a pleasure. Also, the dictionary added the ability to customize the correctness of the translation:
- This is a widespread possibility to specify several variants of word translation, separated by a comma, when any of them is considered correct.
- Some different English words are translated into Russian the same way: “team” and “command” are translated as “team”, so asking to translate the word “team” into English without clarifying the context is somehow silly. In this case, in the dictionary, you can use the clarification in parentheses like this: [“team”, “ti: m”, “team (group)”] , [“command”, “kə'mɑ: nd”, “team ( order) "] . Now, in the exercise, the program will explicitly ask you to translate the phrase “team (group)” or “team (order)”, while translating the words “team” or “command” in the opposite direction, you do not need to clarify, you only need to answer “team”
- When translating into Russian, often, the end of a word (or another part) is not important. For example - “angry” can be translated as “angry”, “angry”, “angry”, etc. To avoid confusion, in translation you can mark the optional part of the word with square brackets like this: ["angry", "'"gri", "angry [nd]"] . Now everywhere in the interface, the translation will be displayed as “angry”, but as a response to the word “angry”, it is allowed to enter any word that starts with “angry”, i.e. mentioned above: "angry", "angry", "angry", etc. The bracket can be any number and in any part of the word.
An example of a dictionary can be found here .
Of course, in order to compile such a dictionary, you will have to sweat a lot, but the ease of editing and the result make this work justified.
Well, another important plus:
All this is in open-source and written in python, which, due to the simplicity and readability of the language, makes it possible for a very wide circle of people to correct the source code for themselves. What I urge to do actively, with laying out interesting results of refinement - back to the repository. Also, python “automatically” provides a high degree of cross-platform (the script was tested in Windows7 and Ubuntu, I hope with other versions and Mac OS X there will be no problems, unfortunately, there is no opportunity to test everywhere).Synchronization
I use the program on several computers at once, so it took some sort of synchronization of statistics and vocabulary. Writing a special meaning is not, unless to gain experience. Therefore, it was decided to use one of the many file synchronization services where you can put either a folder with the program as a whole, or just files with statistics and a dictionary, adjusting the path to them in the settings. The program was slightly refined, so that before each lesson it reads the current version of the dictionary and the statistics from the file, and upon completion of the lesson, the statistics were re-read again, information on the last lesson was added to it, and everything was saved back to the file. This ensures that we always work with the latest version of the dictionary and, while saving statistics on a lesson, do not overwrite the results from another computer, it’s enough just before completing the lesson to make sure that the dropbox (or its equivalent) synchronization is completed.
Statistics
Well, what a program to replenish vocabulary without visualizing progress. In the upper right corner of the main program window there is a button with the letter “i” by clicking on which you can see a list of all words from the dictionary with information on each of them.
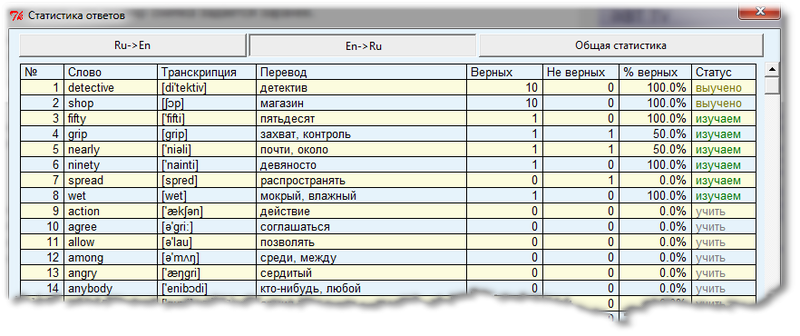
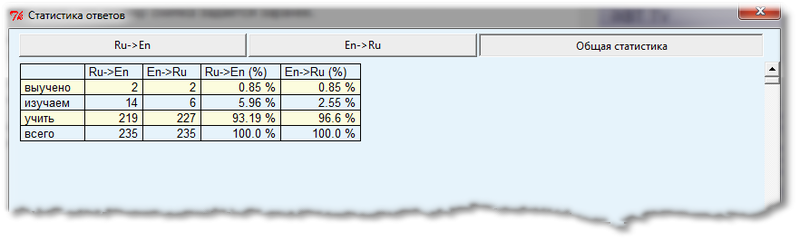
as well as on the last tab you can see summary statistics for all words at once:
Settings
The parameters of the exercises, the time between them, as well as the path to the dictionary and the file with statistics, are placed in a separate file with comments, so that you do not have to climb the code to isolate them.
Installation
Some special installation for the script is not required to simply write to the autoload a line like "% path_to_Python26% \\ pythonw.exe% path_to_main.py% \\ main.py". And of course have python 2.6 installed (although it is likely that everything will work well on other 2.X versions). I didn’t use any special libraries, only standard default delivery capabilities, for the GUI I took tkinter, which in most cases comes with python. In Linux, python is likely to be installed already, but you may need to install the tkinter package.
Conclusion
Actually, the purpose of writing an article and laying out a program in general is to get feedback from the maximum number of people. I would be very grateful for new ideas for improvement and for criticism of the existing implementation. It will be generally great if ideas and criticism are expressed as commits to the repository .
PS: I do not pretend that the program and principles laid down in it is a universal and the most correct way to learn English words. This is just a technique that helps me at this stage. If the program makes life easier for someone else, then this is great and wonderful, because the availability of alternatives is always good. "
Source: https://habr.com/ru/post/152831/
All Articles