"He saw their family with his own eyes"
Can you choose a picture that matches the post title?

Then teach the robot! He also wants.
The project team Open Corps asks habra people to help mark up a freely accessible (CC-BY-SA) corpus of texts. Under the cut, we will talk about what a corps is, why it is needed, how things are with corps in Russia and abroad, why it is so bad and what is our plan.
')
The corpus of texts is a linguistic database that includes texts, various metadata related to these texts, as well as grammatical analyzes of the words and sentences included in them. Metadata and grammatical parsing is markup. It can be of different levels: morphological, syntactic, semantic, etc. Without labeled text shells, it is difficult (or even impossible) to develop software for text analysis. For programs that use machine learning, a training sample is taken from the marked body. In other cases, the body is needed for testing.
Marked corps exist for many languages of the world. Most often, the corpus of texts is available through specialized search engines, allowing you to choose examples of the use of various language constructs. These services are intended for linguists. Download the entire body can not be, because The texts included in them are most often protected by copyright. To develop linguistic software, you need cases that can be downloaded as a whole, along with the markup. On Habré already wrote about it here (about POS-tagging) and here (about syntax) .
Corps of texts in Russia and abroad
Here, the Russian language is not as good as, for example, English, for which there are several different texts available and manually marked up. This is not surprising, at least, because more people speak English than Russian. It is surprising that even for the Hungarian language, which is spoken 10 times less than in Russian, there is an accessible and marked corpus of more than 1 million words in size.
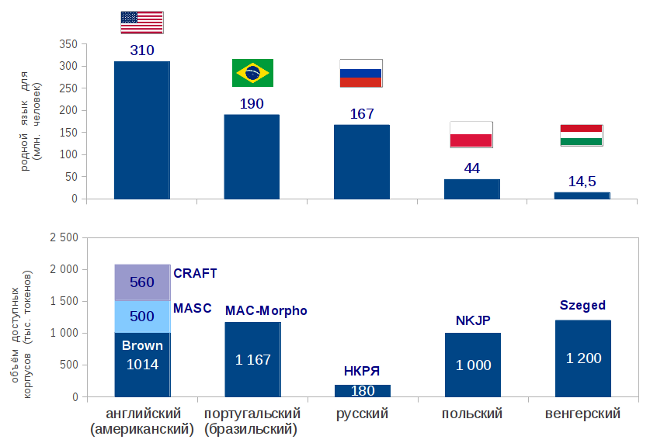
And what about us?
The National Corpus of the Russian Language (NCRF) , created by the joint efforts of many organizations (including the Russian Language Institute of the Russian Academy of Sciences), is available only in the corpus search mode. Of the 6 million words, marked by hand, you can download only a sample of 180 thousand words , in which the sentences are broken. If you want to make a morphological analyzer with the removal of ambiguity, then you have to either use these 180 thousand, which most often will not be enough for machine learning, or try some other language, for example, Polish. This state of affairs is obviously not conducive to the development of computational linguistics in our country.
In order for the Russian language not to fall into the category of “under-resourced languages”, we decided to make a new Open Russian language building, taking into account the experience of creating NCRC and other projects. Since the National Corpus provides a good search interface, and thus solves the problems associated with the search for examples of different words and constructions, we decided to focus on creating a freely accessible corpus for developers : it can be downloaded and used for machine learning or for testing. There is no search for it, but it's not scary, because He is in NKRYa. To ensure that the copyright issue does not prevent the distribution, only texts that are available under the terms of a Creative Commons license or are in the public domain are included in the corpus. The markup is created under the terms of CC-BY-SA.
At the previous stage of our work (in 2011) we collected a corpus of 700 thousand words and manually placed the boundaries of words and sentences. This data can already be downloaded . Now our main goal is to remove ambiguity in the morphological markup. This work also needs to be done manually, there is a lot of it, and we ask you to help us.
Recall the school or what is morphological markup
Morphological markup (tagging, part-of-speech tagging) is a comparison of each word in the text of its dictionary form (“big” - “BIG”, “table” - “TABLE”, “read” - “READ”) and indication of grammatical characteristics of the word: gender, number, case, time, etc. Primary morphological markup is done automatically in the dictionary. We use an AOT project vocabulary modified for our purposes. For most words, the markup is ambiguous , that is, for many words in the text there are several hypotheses in the dictionary. Most often, only one of the hypotheses is correct. There are ambiguous proposals that have several options for parsing. For example:
"These types of steel are in the shop"
STEEL (noun) or BECOMING (verb)?
"He saw their family with his own eyes"
FAMILY (noun) or SEVEN (numeral)?
Such examples are rare. Morphological analysis becomes unambiguous in the context of a sentence: after reading it entirely, we can determine the exact form in which a given word stands . For example, for the sentence “Mommy soap frame” ultimately should be built here such analysis:

After conducting a morphological analysis using the dictionary, only one of the words we can clearly understand. For the words "SOAP" and "RAMU" we get four and two hypotheses, respectively:
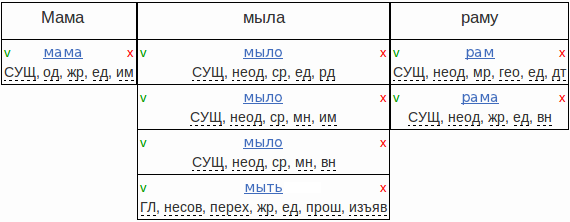
To remove the morphological ambiguity is to choose one correct hypothesis for each word. For native speakers, this most often presents no difficulty.
We have a plan!
To simplify the problem of disambiguation, we divided it into simple questions , which together represent a decision tree for each ambiguity example. In the case of the word “SOAP”, the first question will be “Noun or verb?” . For the sentence “Mommy soap frame”, the removal of ambiguity will end there, because this is a verb, and there is only one verb hypothesis. In other cases, you will need to answer one more or, in the worst case, two more questions.
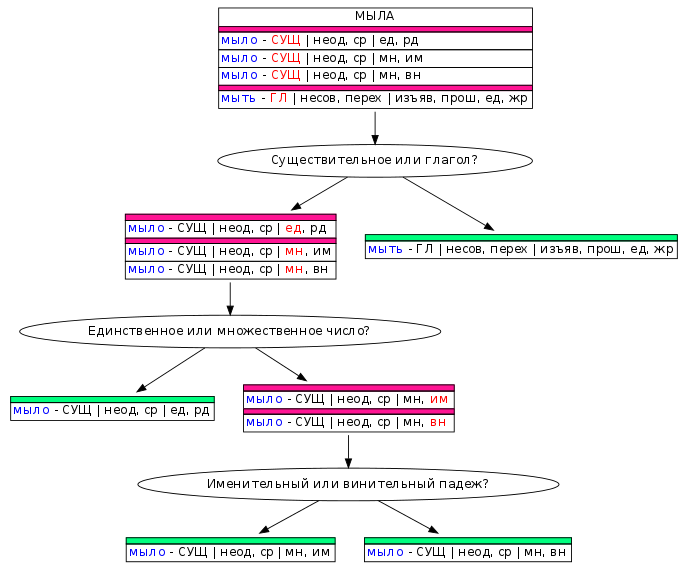
We have grouped together the same type of questions. The participant can choose the type of questions and answer only questions of this type about randomly selected words in their contexts, thus focusing on one task. So mark up faster , because it does not waste time switching between different types of questions.
For the markup to be fairly accurate, each question is asked to three different people , and only if the answers are completely the same, and no one has written comments, they are used without rechecking. If one answer is different from the other two, or if a comment is left, then this example is checked by the moderator.
How much do we have this plan?
According to rough estimates, to remove the ambiguity in the currently collected collection of texts, taking into account the fact that questions are asked three times, you need to answer
To participate in the project, you can use bouts of procrastination , time on the way to work (the markup interface works on smartphones) and other forced pauses in useful activity. In this sense, the layout of the case is similar to solitaire, only more useful . Since no special linguistic knowledge is required, everyone who has read this far can take part, and together we will create a morphological layer of the hull marking. This page contains step-by-step markup instructions.
Recently, we began to collect and publish a subset of sentences in which all ambiguity has already been removed . This subcorpus is still very small - about 9,500 words. As the markup goes on, it becomes larger, and, in the future, this data can be used to create freely available morphological analyzers that can remove ambiguity.
Open casing. Feel free to shoot ambiguity!
References to the mentioned cases
Russian
[NCRF] National Corpus of the Russian Language: ruscorpora.ru (on October 23 there will be a lecture on this project in the lecture hall of the Polytechnic Museum in Moscow)
[OpenCorpora] Open case articles and presentations: opencorpora.org/?page=publications
English
[Brown] Brown Corpus: en.wikipedia.org/wiki/Brown_Corpus
[MASC] Manually Annotated Sub-Corpus (part of the American National Corps, hand-marked): www.anc.org/MASC/Home.html
[CRAFT] The Colorado Richly Annotated Full Text Corpus (67 bio-medical articles with linguistic and ontological markup): bionlp-corpora.sourceforge.net/CRAFT/index.shtml
Portuguese, Polish, Hungarian
[MAC-Morpho] Texts from the newspaper “Folha de São Paulo” in Brazilian Portuguese: www.nilc.icmc.usp.br/lacioweb/english/plancamento.htm
[NKJP] Narodowy Korpus Języka Polskiego. NKJP sub-package available under the GNU GPL v.3 license: nkjp.pl/index.php?page=14&lang=1
[Szeged] Szeged Corpus, corpus of Hungarian texts: www.inf.u-szeged.hu/projectdirs/hlt/index_en.html
Pictures at the beginning of the post: "Family portrait" and "Totem moster" .
Source: https://habr.com/ru/post/152799/
All Articles