We provide Russian texts on Mac OS X in one encoding with a Python script.
It happened to me to have a laptop on OS X, a computer on Linux and one of my friends with Windows. And here through the dropbox they exchange all these three computers with different documents. Including text, which stores various notes, tasks, etc. And here's the ill luck: the texts written on MacOSx are hard to read in the notebook of Windows, and the windows in textedit on MacOSx.
And the whole reason is that on Windows, Notepad uses Windows 1251 encoding, and on OS X, MACCYRILLIC is used by default. Moreover, both programs work without problems with UTF-8 encoding.
That's just how inconvenient it is to convert from one encoding to another, spending extra time on opening a terminal and dialing cherished iconv commands ...
Having thought it over, I wrote a small script, which itself determines the encoding used and converts all txt-files into UTF-8.
')
What I use for everything:
Python 2.7
Mac OS X 10.7.5
PyCharm IDE
Initially made the definition of encoding independently, without additional modules. But on the advice of ad3w decided to rewrite using a ready-made module chardet to determine the encoding.
Who cares, the previous
Download the module chardet 1.1 ,
Unpack and install:
Create your own script for transcoding files:
Next you need to make it convenient to run this script directly from the folder in OS X.
Open Automator and create a Service.
At the top, select the items to get "The service receives files and folders in Finder.app."
Next, set the action “get selected Finder objects”.
Next, "Run the Shell script" in the settings of its "Pass Input: As Arguments" and its content:
Added 2> / dev / null so that the automaton does not stop the execution when the error of the chardet module is displayed.
And the last item is “Show Growl Notification” (you can write in it that the conversion is done).
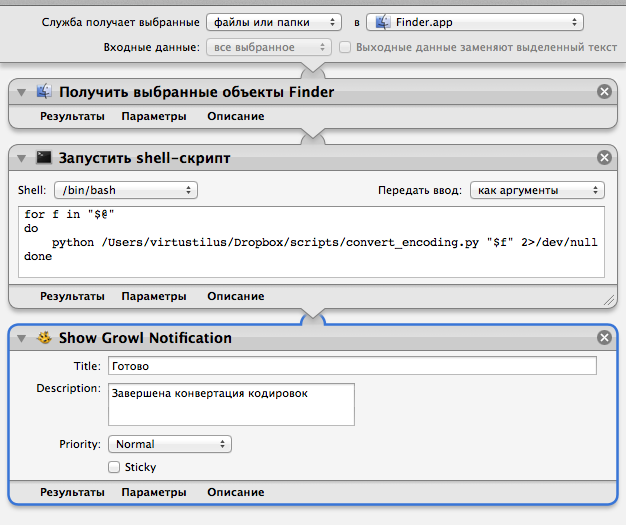
We save it with the name in Latin letters (for some reason, the menu item did not appear in the menu until I renamed it) and check.
A new menu item will appear in Finder in the menu of files and folders in the Services submenu.
PS This is the 5th edition of the script after the comments and experience of its use.
PS Found a problem: if Python sees the encoding of the file to which it writes, then it will work in it. We do not need this, so we delete the file before saving.
And the whole reason is that on Windows, Notepad uses Windows 1251 encoding, and on OS X, MACCYRILLIC is used by default. Moreover, both programs work without problems with UTF-8 encoding.
That's just how inconvenient it is to convert from one encoding to another, spending extra time on opening a terminal and dialing cherished iconv commands ...
Having thought it over, I wrote a small script, which itself determines the encoding used and converts all txt-files into UTF-8.
')
What I use for everything:
Python 2.7
Mac OS X 10.7.5
PyCharm IDE
Initially made the definition of encoding independently, without additional modules. But on the advice of ad3w decided to rewrite using a ready-made module chardet to determine the encoding.
Who cares, the previous
horrible code
The determination takes place by a simple enumeration of encodings and the choice of one in which there will be no unnecessary characters. And you define a character set. Of course, this method is not suitable for files with DOS-graphics, but for normal purposes of using txt it will be enough.
#!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys # automatic=False # appdata={'enc':'','curfile':''} # toconvert=[] # r=[] if len(sys.argv)>1: r=sys.argv[1:] automatic=True else: i=raw_input(u'INPUT PATH:') r+=[i] def print1(s): """ , """ if not automatic: print s # utfrustring=u'' utfrustring+=u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' utfrustring+=u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n « » \u0009 \u2013 \u201c \u201d' def checkline(s,encoding=''): """ """ hist='' b=True for i in range(0,len(s)): c=s[i] try: if not c in utfrustring: #: UTF-8 , if encoding==u'UTF-8': hist+= c + u' ' + str(hex(ord(c))) + u' at ' + str(i) + u' in: ' + s + '\n' b=False break except: if encoding==u'UTF-8': hist+=u'error encoding \n' b=False break return (b,hist) def check_all_lines(lines, encoding=''): """ """ foundenc=appdata['enc'] if foundenc: return foundenc if encoding=='': foundenc=u'UNICODE' else: foundenc=encoding x=lines[:] for j in x: if encoding!='': try: j=unicode(j,encoding) except: foundenc='' break cl=checkline(j,encoding) if not cl[0]: if cl[1]!='': print1(u'Error in:'+appdata['curfile']) print1(cl[1]) foundenc='' break appdata['enc']=foundenc # , , if len(r)==1 and os.path.isdir(r[0]): a=r[0] r[:]=[] for i in os.walk(a): p=i[2] for j in p: if j.endswith('.txt'): r+=[i[0]+'/'+j] if len(r)>0: for i in r: i=unicode(i,u'UTF-8') # , UNICODE txt UNICODE: u'.txt' if i.endswith(u'.txt'): f=file(i,'r') lines=f.readlines() f.close() appdata['curfile']=i # check_all_lines(lines,'') check_all_lines(lines,u'MACCYRILLIC') check_all_lines(lines,u'CP866') check_all_lines(lines,u'CP1251') check_all_lines(lines,u'KOI8R') check_all_lines(lines,u'CP10007') check_all_lines(lines,u'UTF-8-MAC') check_all_lines(lines,u'UTF-8') check_all_lines(lines,u'UTF-8-MAC') check_all_lines(lines,u'UTF-16') check_all_lines(lines,u'UTF-16BE') check_all_lines(lines,u'UTF-7') check_all_lines(lines,u'CP1252') check_all_lines(lines,u'KOI8-U') check_all_lines(lines,u'KOI8-RU') check_all_lines(lines,u'ISO-8859-5') if not appdata['enc']: toconvert.append((i,u'NOT FOUND ENCODING')) if appdata['enc'] and appdata['enc']!=u'UTF-8': toconvert.append((i,appdata['enc'])) else: print1(u'\nFile '+i+u' is not text file. \n\n') if toconvert: c=0 for i in toconvert: if i[1]!=u'NOT FOUND ENCODING': c+=1 if c>0: print1(u'\n\n FOUND FILES TO CONVERT: ') for i in toconvert: print1(i[0] + u' in encoding ' + i[1]) bt=True if not automatic: w=raw_input(u'Convert '+str(c)+u' files? (N)') bt= (w=='Y' or w=='y' or w=='' or w=='' or w=='' or w=='') if bt: for i in toconvert: if i[1]!=u'NOT FOUND ENCODING': f=file(i[0],'r') x=f.readlines() f.close() x=[ unicode(k,i[1]) for k in x ] x=[ k.encode(u'UTF-8') for k in x] f=file(i[0],'w') f.writelines(x) f.close() print1(u'FILE '+i[0]+u' CONVERTED SUCCESSFULLY :) ') else: print1(u'Bye!') else: print1(u'NO FILES TO CONVERT') for i in toconvert: print1(i[0] + u' in encoding ' + i[1]) else: print1(u' ALL ENCODING IS OK (UTF-8)!!! :)') else: print1(u'NO ONE TXT FILE') Download the module chardet 1.1 ,
Unpack and install:
python setup.py install Create your own script for transcoding files:
Previous edition
#!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys import chardet files=sys.argv[1:] # , if len(files)==0: files=[raw_input(u'INPUT PATH:')] # files_to_convert=[] for i in files: if os.path.exists(i): if os.path.isdir(i): for w in os.walk(i): for wfile in w[2]: if wfile.lower().endswith('.txt'): files_to_convert+=[w[0]+'/'+wfile] elif os.path.isfile(i): # , files_to_convert+=[i] if len(files_to_convert)>0: for i in files_to_convert: f=file(i,'r') text=''.join(f.readlines()) f.close() enc=chardet.detect(text).get('encoding') # (dropbox), if enc!='UTF-8': # try: text=text.decode(enc).encode('UTF-8') f=file(i,'w') f.write(text) f.close() except: pass #!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys import chardet def may_be_1251(text_not_changed, encoding): """ Win1251, chardet , MacCyrillic chardet , MacCyrillic: 1. ” Advanced- 2. ”€, ( .. ) 3. — mfc100u.dll € """ simbols = u'' simbols += u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' simbols += u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n' if encoding.lower() == 'maccyrillic': err_mac = err_win = 0 try: t_win = text_not_changed.decode('cp1251') except: err_win += 1000000 try: t_mac = text_not_changed.decode('MacCyrillic') except: err_mac += 1000000 for i in t_win: if i not in simbols and i != u'\n': err_win += 1 for i in t_mac: if i not in simbols: err_mac += 1 if err_mac > err_win: encoding = 'cp1251' return encoding paths = sys.argv[1:] # , if len(paths) == 0: paths = [raw_input(u'INPUT PATH:')] # ( , .. " ") dirs = [i for i in paths if os.path.exists(i) and os.path.isdir(i)] files = [i for i in paths if os.path.exists(i) and os.path.isfile(i)] # for i_dir in dirs: for wpath, wdirs, wfiles in os.walk(i_dir): files += [wpath + '/' + i for i in wfiles if i.lower().endswith('.txt')] for i in files: with open(i, 'r') as f: text = ''.join(f.readlines()) enc = may_be_1251(text, chardet.detect(text).get('encoding')) # (dropbox), if enc and enc.lower() != 'utf-8': # try: text = text.decode(enc) # OS X 10.8 \r text = text.replace(u'\r', '').encode('utf-8') # : , . , os.unlink(i) with open(i, 'w') as f: f.write(text) except: pass Next you need to make it convenient to run this script directly from the folder in OS X.
Open Automator and create a Service.
At the top, select the items to get "The service receives files and folders in Finder.app."
Next, set the action “get selected Finder objects”.
Next, "Run the Shell script" in the settings of its "Pass Input: As Arguments" and its content:
for f in "$@" do python /___/convert_encoding.py "$f" 2>/dev/null done Added 2> / dev / null so that the automaton does not stop the execution when the error of the chardet module is displayed.
And the last item is “Show Growl Notification” (you can write in it that the conversion is done).
We save it with the name in Latin letters (for some reason, the menu item did not appear in the menu until I renamed it) and check.
A new menu item will appear in Finder in the menu of files and folders in the Services submenu.
PS This is the 5th edition of the script after the comments and experience of its use.
PS Found a problem: if Python sees the encoding of the file to which it writes, then it will work in it. We do not need this, so we delete the file before saving.
Source: https://habr.com/ru/post/152737/
All Articles