NoSQL database: we understand the essence
Recently, the term “NoSQL” has become very fashionable and popular, all sorts of software solutions under this sign are being actively developed and promoted. Huge amounts of data, linear scalability, clusters, fault tolerance, and non-relationality have become synonymous with NoSQL. However, few people have a clear understanding of what NoSQL storage is, how this term appeared and what general characteristics they possess. Let's try to eliminate this gap.

The most interesting thing about the term is that despite the fact that it was first used in the late 90s, it acquired real meaning as it is used now only in mid-2009. Initially, this was the open source database created by Carlo Strozzi, which kept All data is as ASCII files and used shell scripts instead of SQL to access data. With “NoSQL” in its current form, it had nothing in common.
In June 2009, a meeting was organized by Johan Oscarsson in San Francisco, at which it was planned to discuss new developments in the IT data storage and processing market. The main impetus for the meeting were new open-source products like BigTable and Dynamo. For a bright signboard for a meeting it was required to find a succinct and concise term that would fit perfectly into the Twitter hashtag. One of these terms was suggested by Eric Evans from RackSpace - “NoSQL”. The term was planned only for one meeting and did not have a deep semantic load, but it so happened that it spread throughout the global network like viral advertising and became the de facto name of a whole trend in the IT industry. By the way, Voldemort (clone of Amazon Dynamo), Cassandra, Hbase (analogs of Google BigTable), Hypertable, CouchDB, MongoDB spoke at the conference.
')
It is worth emphasizing once again that the term “NoSQL” has an absolutely natural origin and does not have a generally accepted definition or scientific institution behind it. This name rather characterizes the vector of IT development away from relational databases. It stands for Not Only SQL, although there are proponents for the direct definition of No SQL. To group and systematize knowledge about the NoSQL world, Pramod Sadaladzh and Martin Fowler tried to do in their recent book “NoSQL Distilled” .
There are few common characteristics for all NoSQL, as there are now a lot of heterogeneous systems under the NoSQL label (the most complete, perhaps, list can be found at http://nosql-database.org/ ). Many characteristics are peculiar only to certain NoSQL databases, I will definitely mention this when listing.
1. Not using SQL
This refers to ANSI SQL DML, since many databases try to use query languages similar to the well-known favorite syntax, but no one has been able to fully implement it and is unlikely to succeed. Although there are rumors there are startups that are trying to implement SQL, for example, in Hadup ( http://www.drawntoscalehq.com/ and http://www.hadapt.com/ )
2. Unstructured (schemaless)
The meaning is that in NoSQL databases, unlike the relational data structure, it is not regulated (or weakly typed, if analogous to the programming languages are used) - an arbitrary field can be added to a single line or document without preliminary declarative changes in the structure of the entire table. Thus, if there is a need to change the data model, then the only sufficient action is to reflect the change in the application code.
For example, when renaming a field in MongoDB:
If we change the application logic, then we expect a new field also when reading. But due to the lack of a data scheme, the totalSum field is absent from other already existing Order objects. In this situation, there are two options for further action. The first is to bypass all documents and update this field in all existing documents. Due to the volume of data, this process occurs without any locks (comparable to the alter table rename column), so during the update, existing data can be read by other processes. Therefore, the second option - checking in the application code - is inevitable:
And when re-recording, we will write this field to the database in a new format.
A pleasant consequence of the lack of a scheme is the efficiency of working with sparse data. If there is a date_published field in one document, and no field in the second, then no empty date_published field will be created for the second. This is, in principle, a logical, but less obvious example - column-family NoSQL databases that use familiar table / column concepts. However, due to the absence of a schema, columns are not declared declaratively and may change / be added during the user session of working with the database. This allows in particular the use of dynamic columns for the implementation of lists.
An unstructured scheme has its drawbacks - besides the above-mentioned overhead in the application code when changing the data model - the absence of all possible restrictions from the base (not null, unique, check constraint, etc.), plus additional difficulties in understanding and controlling the structure data when working in parallel with a database of different projects (there are no dictionaries on the side of the database). However, in a rapidly changing modern world, such flexibility is still an advantage. As an example, Twitter, which five years ago, along with Twitter, kept only a few additional information (time, Twitter handle and a few bytes of meta-information), but now in addition to the message itself, the database still stores a few kilobytes of metadata.
(Hereinafter, it’s mainly about key-value, document and column-family databases, the database graph may not have these properties).
3. Presentation of data in the form of aggregates (aggregates).
Unlike the relational model, which stores the logical business entity of the application in different physical tables for normalization purposes, NoSQL repository operates with these entities as whole objects:
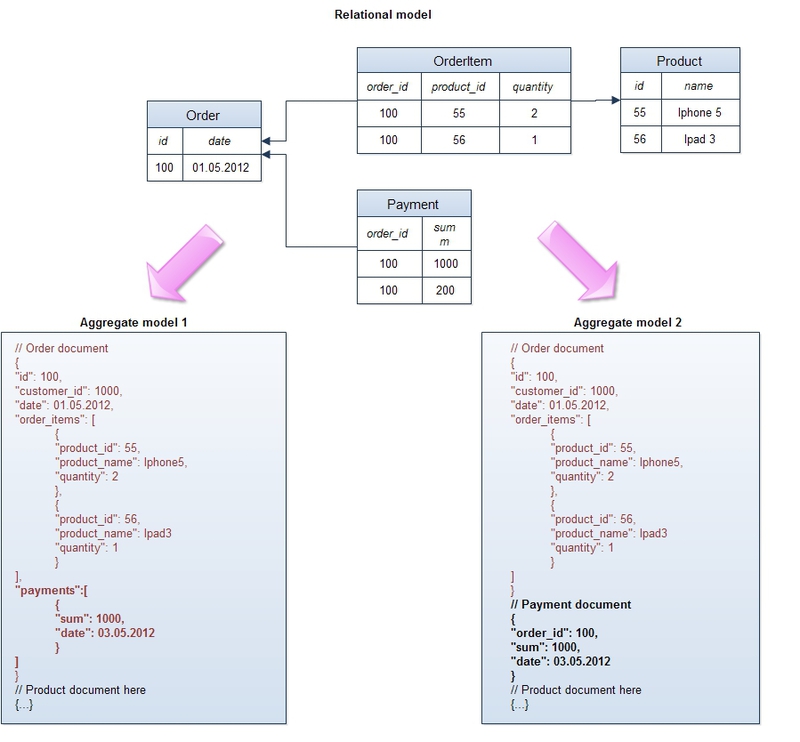
This example shows the aggregates for the standard conceptual relational model of e-commerce “order - order items - payments - product”. In both cases, an order is combined with positions into one logical object, with each position keeping a link to the product and some of its attributes, for example, a name (such denormalization is necessary not to request the product object when retrieving an order - the main rule of distributed systems is minimum “Joins” between objects). In one unit, payments are combined with the order and are an integral part of the object, in the other - they are moved to a separate object. This demonstrates the main rule for designing a data structure in NoSQL databases - it must comply with the requirements of the application and be as optimized as possible for the most frequent queries. If payments are regularly extracted along with the order, it makes sense to include them in a common object, if many requests work only with payments, then it is better to take them into a separate entity.
Many will argue, noting that working with large, often denormalized, objects is fraught with numerous problems when trying to randomly query data, when queries do not fit into the structure of aggregates. What if we use orders along with positions and payments on an order (this is how the application works), but the business asks us to calculate how many units of a certain product were sold last month? In this case, instead of scanning the OrderItem table (in the case of the relational model), we will have to retrieve orders entirely in the NoSQL repository, although we will not need most of this information. Unfortunately, this is a compromise that has to be made in a distributed system: we cannot perform data normalization as in a conventional single-server system, since this will create the need to merge data from different nodes and can lead to a significant slowdown in the operation of the database.
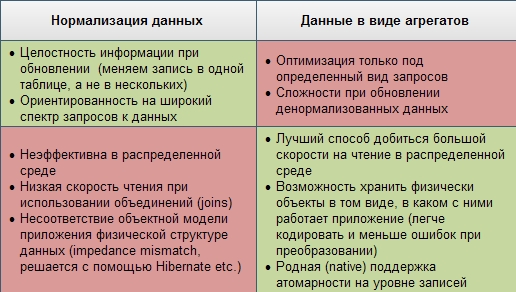
I tried to group the pros and cons of both approaches in the table:
4. Weak ACID properties.
For a long time, the consistency (consistency) of the data was a “sacred cow” for architects and developers. All relational databases provided one or another level of isolation, either by locking with a change and blocking read, or by undo-logs. With the arrival of huge amounts of information and distributed systems, it became clear that to ensure for them the transactionality of a set of operations on the one hand and to get high availability and fast response time on the other is impossible. Moreover, even updating one record does not guarantee that any other user will instantly see changes in the system, because the change may occur, for example, in the master node, and the replica will be asynchronously copied to the slave node, from which another user works. In this case, he will see the result after a certain period of time. This is called eventual consistency, and this is what all the major Internet companies in the world are now doing, including Facebook and Amazon. The latter proudly declare that the maximum interval during which the user can see inconsistent data is no more than a second. An example of such a situation is shown in the figure:

The logical question that arises in such a situation is what should be done to systems that classically place high demands on the atomicity-consistency of operations and at the same time need fast distributed clusters — financial, online shopping, etc.? Practice shows that these requirements have long been irrelevant: one developer of the financial banking system said: “If we really waited for the completion of each transaction in the global ATM network (ATMs), the transactions would take so long that customers would run away in a rage. What happens if you and your partner withdraw money at the same time and exceed the limit? “You both get the money, and we will fix it later.” Another example is the hotel booking shown in the picture. Online stores, whose data management policy implies eventual consistency, are required to take measures in case of such situations (automatic conflict resolution, rollback of an operation, updating with other data). In practice, hotels always try to keep a “pool” of available rooms for an emergency and this can be a solution to a dispute.
In fact, weak ACID properties do not mean that they do not exist at all. In most cases, an application working with a relational database uses a transaction to change logically related objects (order — order items), which is necessary, as these are different tables. With proper design of the data model in the NoSQL database (the aggregate is an order along with a list of items of the order), you can achieve the same isolation level when changing one record as in the relational database.
5. Distributed systems, without shared resources (share nothing).
Again, this does not apply to database graphs whose structure, by definition, does not spread well across remote nodes.
This is probably the main leitmotif of the development of NoSQL databases. With the avalanche-like growth of information in the world and the need to process it in a reasonable time, the problem of vertical scalability arose - the growth of processor speed stopped at 3.5 GHz, the speed of reading from the disk also grows at a slow pace, plus the price of a powerful server is always greater than the total price of several simple servers. In this situation, ordinary relational databases, even clustered on a disk array, cannot solve the problem of speed, scalability, and bandwidth. The only way out is horizontal scaling, when several independent servers are connected by a fast network and each owns / processes only part of the data and / or only part of read-update requests. In such an architecture, in order to increase the storage capacity (capacity, response time, bandwidth) it is only necessary to add a new server to the cluster - that's all. Sharding, replication, fault tolerance procedures (the result will be obtained even if one or several servers stopped responding), data redistribution in the case of adding a node is handled by the NoSQL database itself. Briefly present the main properties of distributed NoSQL databases:
Replication - copying data to other nodes when updating. Allows both to achieve greater scalability, and to increase the availability and security of data. It is accepted to divide into two types:
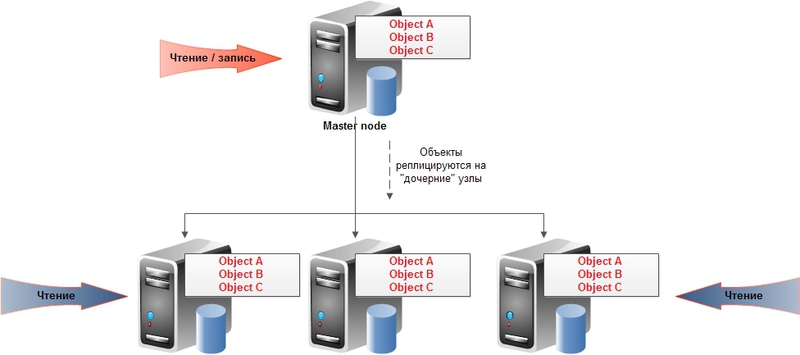
master-slave :
and peer-to-peer :

The first type assumes a good read scalability (can occur from any node), but an unscaled record (only to the master node). There are also subtleties with the provision of constant availability (in case of a master crash, either one of the remaining nodes is assigned either manually or automatically to its place). For the second type of replication, it is assumed that all nodes are equal and can serve both read and write requests.
Sharding - separation of data by node:
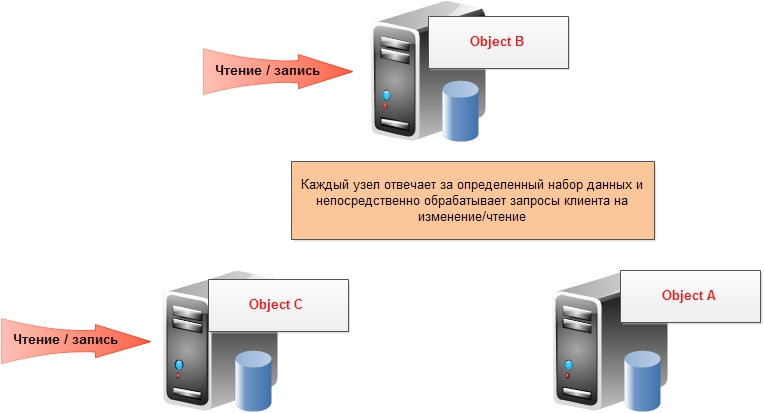
Sharding was often used as a “crutch” to relational databases in order to increase speed and throughput: a user application partitioned data from several independent databases and, when requesting relevant data, the user accessed a specific database. In NoSQL databases, sharding, like replication, is performed automatically by the base itself and the user application apart from these complex mechanisms.
6. NoSQL bases are mainly open source and created in the 21st century.
It is on the second sign that Sadaladzh and Fowler did not classify object databases as NoSQL (although http://nosql-database.org/ includes them in the general list), since they were created in the 90s and did not get much popularity .
Additionally, I wanted to dwell on the classification of NoSQL databases, but perhaps I’ll do this in the next article if it is interesting for habouriors.
NoSQL movement is gaining popularity at a tremendous pace. However, this does not mean that relational databases become a rudiment or something archaic. Most likely, they will be used and used as before, but more and more NoSQL bases will appear in symbiosis with them. We are entering the era of polyglot persistence — an era when different data warehouses are used for different needs. Now there is no monopoly of relational databases as an alternative source of data. Increasingly, architects choose storage based on the nature of the data itself and how we want to manipulate them, how much information is expected. And so it only becomes more interesting.
Story.
The most interesting thing about the term is that despite the fact that it was first used in the late 90s, it acquired real meaning as it is used now only in mid-2009. Initially, this was the open source database created by Carlo Strozzi, which kept All data is as ASCII files and used shell scripts instead of SQL to access data. With “NoSQL” in its current form, it had nothing in common.
In June 2009, a meeting was organized by Johan Oscarsson in San Francisco, at which it was planned to discuss new developments in the IT data storage and processing market. The main impetus for the meeting were new open-source products like BigTable and Dynamo. For a bright signboard for a meeting it was required to find a succinct and concise term that would fit perfectly into the Twitter hashtag. One of these terms was suggested by Eric Evans from RackSpace - “NoSQL”. The term was planned only for one meeting and did not have a deep semantic load, but it so happened that it spread throughout the global network like viral advertising and became the de facto name of a whole trend in the IT industry. By the way, Voldemort (clone of Amazon Dynamo), Cassandra, Hbase (analogs of Google BigTable), Hypertable, CouchDB, MongoDB spoke at the conference.
')
It is worth emphasizing once again that the term “NoSQL” has an absolutely natural origin and does not have a generally accepted definition or scientific institution behind it. This name rather characterizes the vector of IT development away from relational databases. It stands for Not Only SQL, although there are proponents for the direct definition of No SQL. To group and systematize knowledge about the NoSQL world, Pramod Sadaladzh and Martin Fowler tried to do in their recent book “NoSQL Distilled” .
NoSQL database features
There are few common characteristics for all NoSQL, as there are now a lot of heterogeneous systems under the NoSQL label (the most complete, perhaps, list can be found at http://nosql-database.org/ ). Many characteristics are peculiar only to certain NoSQL databases, I will definitely mention this when listing.
1. Not using SQL
This refers to ANSI SQL DML, since many databases try to use query languages similar to the well-known favorite syntax, but no one has been able to fully implement it and is unlikely to succeed. Although there are rumors there are startups that are trying to implement SQL, for example, in Hadup ( http://www.drawntoscalehq.com/ and http://www.hadapt.com/ )
2. Unstructured (schemaless)
The meaning is that in NoSQL databases, unlike the relational data structure, it is not regulated (or weakly typed, if analogous to the programming languages are used) - an arbitrary field can be added to a single line or document without preliminary declarative changes in the structure of the entire table. Thus, if there is a need to change the data model, then the only sufficient action is to reflect the change in the application code.
For example, when renaming a field in MongoDB:
BasicDBObject order = new BasicDBObject(); order.put(“date”, orderDate); // order.put(“totalSum”, total); // “sum” If we change the application logic, then we expect a new field also when reading. But due to the lack of a data scheme, the totalSum field is absent from other already existing Order objects. In this situation, there are two options for further action. The first is to bypass all documents and update this field in all existing documents. Due to the volume of data, this process occurs without any locks (comparable to the alter table rename column), so during the update, existing data can be read by other processes. Therefore, the second option - checking in the application code - is inevitable:
BasicDBObject order = new BasicDBObject(); Double totalSum = order.getDouble(“sum”); // if (totalSum == null) totalSum = order.getDouble(“totalSum”); // And when re-recording, we will write this field to the database in a new format.
A pleasant consequence of the lack of a scheme is the efficiency of working with sparse data. If there is a date_published field in one document, and no field in the second, then no empty date_published field will be created for the second. This is, in principle, a logical, but less obvious example - column-family NoSQL databases that use familiar table / column concepts. However, due to the absence of a schema, columns are not declared declaratively and may change / be added during the user session of working with the database. This allows in particular the use of dynamic columns for the implementation of lists.
An unstructured scheme has its drawbacks - besides the above-mentioned overhead in the application code when changing the data model - the absence of all possible restrictions from the base (not null, unique, check constraint, etc.), plus additional difficulties in understanding and controlling the structure data when working in parallel with a database of different projects (there are no dictionaries on the side of the database). However, in a rapidly changing modern world, such flexibility is still an advantage. As an example, Twitter, which five years ago, along with Twitter, kept only a few additional information (time, Twitter handle and a few bytes of meta-information), but now in addition to the message itself, the database still stores a few kilobytes of metadata.
(Hereinafter, it’s mainly about key-value, document and column-family databases, the database graph may not have these properties).
3. Presentation of data in the form of aggregates (aggregates).
Unlike the relational model, which stores the logical business entity of the application in different physical tables for normalization purposes, NoSQL repository operates with these entities as whole objects:
This example shows the aggregates for the standard conceptual relational model of e-commerce “order - order items - payments - product”. In both cases, an order is combined with positions into one logical object, with each position keeping a link to the product and some of its attributes, for example, a name (such denormalization is necessary not to request the product object when retrieving an order - the main rule of distributed systems is minimum “Joins” between objects). In one unit, payments are combined with the order and are an integral part of the object, in the other - they are moved to a separate object. This demonstrates the main rule for designing a data structure in NoSQL databases - it must comply with the requirements of the application and be as optimized as possible for the most frequent queries. If payments are regularly extracted along with the order, it makes sense to include them in a common object, if many requests work only with payments, then it is better to take them into a separate entity.
Many will argue, noting that working with large, often denormalized, objects is fraught with numerous problems when trying to randomly query data, when queries do not fit into the structure of aggregates. What if we use orders along with positions and payments on an order (this is how the application works), but the business asks us to calculate how many units of a certain product were sold last month? In this case, instead of scanning the OrderItem table (in the case of the relational model), we will have to retrieve orders entirely in the NoSQL repository, although we will not need most of this information. Unfortunately, this is a compromise that has to be made in a distributed system: we cannot perform data normalization as in a conventional single-server system, since this will create the need to merge data from different nodes and can lead to a significant slowdown in the operation of the database.
I tried to group the pros and cons of both approaches in the table:
4. Weak ACID properties.
For a long time, the consistency (consistency) of the data was a “sacred cow” for architects and developers. All relational databases provided one or another level of isolation, either by locking with a change and blocking read, or by undo-logs. With the arrival of huge amounts of information and distributed systems, it became clear that to ensure for them the transactionality of a set of operations on the one hand and to get high availability and fast response time on the other is impossible. Moreover, even updating one record does not guarantee that any other user will instantly see changes in the system, because the change may occur, for example, in the master node, and the replica will be asynchronously copied to the slave node, from which another user works. In this case, he will see the result after a certain period of time. This is called eventual consistency, and this is what all the major Internet companies in the world are now doing, including Facebook and Amazon. The latter proudly declare that the maximum interval during which the user can see inconsistent data is no more than a second. An example of such a situation is shown in the figure:
The logical question that arises in such a situation is what should be done to systems that classically place high demands on the atomicity-consistency of operations and at the same time need fast distributed clusters — financial, online shopping, etc.? Practice shows that these requirements have long been irrelevant: one developer of the financial banking system said: “If we really waited for the completion of each transaction in the global ATM network (ATMs), the transactions would take so long that customers would run away in a rage. What happens if you and your partner withdraw money at the same time and exceed the limit? “You both get the money, and we will fix it later.” Another example is the hotel booking shown in the picture. Online stores, whose data management policy implies eventual consistency, are required to take measures in case of such situations (automatic conflict resolution, rollback of an operation, updating with other data). In practice, hotels always try to keep a “pool” of available rooms for an emergency and this can be a solution to a dispute.
In fact, weak ACID properties do not mean that they do not exist at all. In most cases, an application working with a relational database uses a transaction to change logically related objects (order — order items), which is necessary, as these are different tables. With proper design of the data model in the NoSQL database (the aggregate is an order along with a list of items of the order), you can achieve the same isolation level when changing one record as in the relational database.
5. Distributed systems, without shared resources (share nothing).
Again, this does not apply to database graphs whose structure, by definition, does not spread well across remote nodes.
This is probably the main leitmotif of the development of NoSQL databases. With the avalanche-like growth of information in the world and the need to process it in a reasonable time, the problem of vertical scalability arose - the growth of processor speed stopped at 3.5 GHz, the speed of reading from the disk also grows at a slow pace, plus the price of a powerful server is always greater than the total price of several simple servers. In this situation, ordinary relational databases, even clustered on a disk array, cannot solve the problem of speed, scalability, and bandwidth. The only way out is horizontal scaling, when several independent servers are connected by a fast network and each owns / processes only part of the data and / or only part of read-update requests. In such an architecture, in order to increase the storage capacity (capacity, response time, bandwidth) it is only necessary to add a new server to the cluster - that's all. Sharding, replication, fault tolerance procedures (the result will be obtained even if one or several servers stopped responding), data redistribution in the case of adding a node is handled by the NoSQL database itself. Briefly present the main properties of distributed NoSQL databases:
Replication - copying data to other nodes when updating. Allows both to achieve greater scalability, and to increase the availability and security of data. It is accepted to divide into two types:
master-slave :
and peer-to-peer :
The first type assumes a good read scalability (can occur from any node), but an unscaled record (only to the master node). There are also subtleties with the provision of constant availability (in case of a master crash, either one of the remaining nodes is assigned either manually or automatically to its place). For the second type of replication, it is assumed that all nodes are equal and can serve both read and write requests.
Sharding - separation of data by node:
Sharding was often used as a “crutch” to relational databases in order to increase speed and throughput: a user application partitioned data from several independent databases and, when requesting relevant data, the user accessed a specific database. In NoSQL databases, sharding, like replication, is performed automatically by the base itself and the user application apart from these complex mechanisms.
6. NoSQL bases are mainly open source and created in the 21st century.
It is on the second sign that Sadaladzh and Fowler did not classify object databases as NoSQL (although http://nosql-database.org/ includes them in the general list), since they were created in the 90s and did not get much popularity .
Additionally, I wanted to dwell on the classification of NoSQL databases, but perhaps I’ll do this in the next article if it is interesting for habouriors.
Summary.
NoSQL movement is gaining popularity at a tremendous pace. However, this does not mean that relational databases become a rudiment or something archaic. Most likely, they will be used and used as before, but more and more NoSQL bases will appear in symbiosis with them. We are entering the era of polyglot persistence — an era when different data warehouses are used for different needs. Now there is no monopoly of relational databases as an alternative source of data. Increasingly, architects choose storage based on the nature of the data itself and how we want to manipulate them, how much information is expected. And so it only becomes more interesting.
Source: https://habr.com/ru/post/152477/
All Articles