Unbiased DirectX Rendering on GPU, CPU and in the cloud
How to create a renderer that would even work on your grandmother’s computer? Initially, we faced a slightly different task - to create an unbiased render for all GPU models: NVidia, ATI, Intel.
Although the idea of such a render for all video cards has been in the air for a long time, it hasn’t reached a high-quality implementation, especially on Direct3D. In our work, we have come to a very wild bunch and will continue to tell you what brought us to it and how it works.

That is unbiased rendering, or rendering without assumptions, very well outlined Marchevsky in a series of articles
"Tracing the path to the GPU" Part 1 , Part 2 and " Unbiased rendering (rendering without assumptions) ".
In short: this is a rendering that does not introduce systematic errors in the calculation and reproduces physically accurate effects.
')

Due to the physical accuracy and quality of the image, this approach is obviously very resource-intensive. You can solve the problem by transferring calculations to the GPU, since this approach gives an increase in the calculation speed to 50 and once per GPU device.

1200x600 (clickable), AMD Radeon HD 6870, render time: 9 min
There are many GPGPU platforms (OpenCL, CUDA, FireStream, DirectCompute, C ++ AMP, Shaders, etc.), but the debate about the optimal choice is still going on, and there is no definitive answer to what is best to use. Consider the main arguments in favor of Direct3D, which have led us to choose the name of this API:
From OpenCL and Direct3D, we chose the evil that, at least, has stable drivers, honed by decades of the gaming industry, and has better performance in a number of benchmarks. Also, based on the task, CUDA was rejected, despite all the tools, an abundant number of examples and a strong developer community. C ++ AMP was not yet announced at the time, but since its implementation is built on top of DirectX, transferring the render to it will not make any special problems.
The OpenGL / GLSL bundle was also considered, but was quickly discarded due to limitations that are solved in DirectX using DirectCompute (problems of bidirectional path tracing, etc.).
Also, we note the situation with GPGPU consumer hardware drivers, which come out late and are brought to stability for a long time. So, with the release of the NVIDIA Kepler 600 line, gamers immediately got quality Direct3D drivers and more efficient gaming machines, but most of the GPGPU applications lost their compatibility or became less productive. For example, Octane Render and Arion Render, built on CUDA, began to support the Kepler line just a few days ago. In addition, professional GPGPU hardware is not always much better in a number of tasks, as described in the article “ NVidia for professional 3D applications ”. This gives reason to assemble a workstation on the consumer gaming hardware.
In all announcements of DirectX 10‒11 they write that new shader models are ideal for ray tracing and many other GPGPU tasks. But in fact, no one really used this opportunity. Why?
Let's go back a year ago. The last update of the DX SDK was in July 2010. There is no integration with VisualStudio, there are practically no GPGPU developer communities and qualitative examples of normal computing tasks. But what really is there, there is no syntax highlighting for shaders! Sane debugging tools either. PIX is not able to withstand multiple nested loops or a shader of 400+ lines of code. D3DCompiler could crash through time and compile complex shaders for tens of minutes. Hell.
On the other hand, weak implementation of the technology. Most of the scientific articles and publications were written using CUDA, and sharpened by NVIDIA hardware. The NVIDIA OptiX team is also not particularly interested in research for other vendors. The German company mentalimages, which for decades has accumulated experience and patents in this area, is now also owned by NVIDIA. All this creates an unhealthy imbalance in the direction of one vendor, but the market is the market. For us, this all meant that all new GPGPU tracing and rendering techniques must be investigated anew, but only on DirectX and on ATI and Intel hardware, which often led to completely different results, for example, on the VLIW5 architecture.
Eliminate problems
Before describing the implementation, here are some useful tips that helped us in the development:
Rasterization vs tracing
Despite the fact that DirectX is used, there is no talk about rasterization. Standard Pipeline Vertex, Hull, Domain, Geometric and Pixel Shaders are not used. We are talking about tracing the paths of light by means of pixel and Compute shaders. The idea of combining rasterization + tracing, of course, arose, but turned out to be very difficult to implement. The first intersection of the rays can be replaced by rasterization, but after that it is very difficult to generate secondary rays. Often it turned out that the rays were under the surface, and the result was wrong. The guys from Sony Pictures Imageworks, who are developing Arnold Renderer, came to the same conclusion.
Rendering
There are two basic rendering organization approaches:
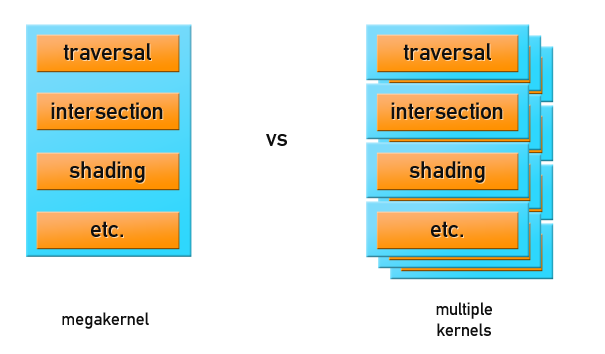
We stopped at the first option using shaders for GPGPU, but before that or rendering, you need to prepare the geometry and data about the scene, correctly placing them in the memory of the GPU.
Scene data includes:
No vertex and index buffers are used when rendering. In Direct3D11, the data is unified, everything is stored in the same format, but you can tell the device how to look at it: like Buffer, Texture1D / 2D / 3D / Array / CUBE, RenderTarget, etc. Data that is more less linear access is best stored in the form of buffers. Data with random access, for example, accelerating the structure of the scene, it is better to store in the texture, because with frequent calls, part of the data is cached.
Quickly changing small data chunks are reasonably stored in constant buffers, these are camera parameters, light sources and materials, if there are not many of them and they fit into a buffer of 4096 x float4. In interactive rendering, changing the camera position, setting up materials and light is the most common operation. The change in geometry occurs somewhat less frequently, but the constant memory is still not enough to accommodate it.
Because GPU memory is relatively small, you need to use smart approaches to its organization and try to pack everything that you can pack and use data compression. The textures of the materials we place in a multi-layered texture atlas, because The number of GPU texture slots is limited. Also, the GPU has built-in texture compression formats - DXT, which are used for texture atlases and can reduce the size of textures by up to 8 and times.
Texture packing in satin:

As a result, the location of the data in memory looks like this:

It is assumed that the data of light and materials can fit in the constant registers. But if the scene is quite complicated, the materials and the light will be placed in the global memory, where there should be enough space for them.

Moving to rendering: in the vertex shader, draw a quad, screen size, and use the mapping technique of pixels to pixels so that each pixel of the pixel shader rasterizes the correct texture coordinates and, consequently, the correct x and y values on the screen.
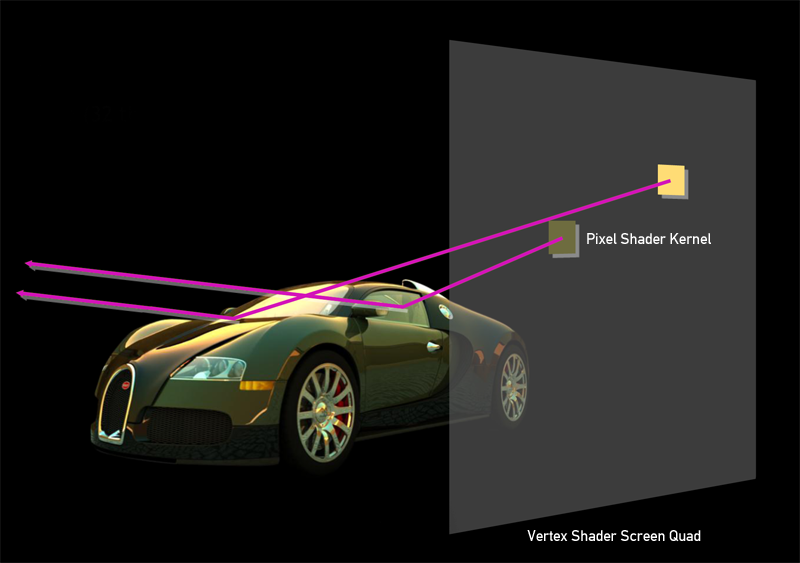
Further, for each pixel in the shader, a ray path tracing algorithm is calculated. This method performs GPGPU computations on pixel shaders. Such an approach may not seem to be the most optimal, and it would be more reasonable to use DirectCompute, for which no vertex shaders and screenshots should be created. But numerous tests have shown that DirectCompute is 10-15% slower. In the task of tracing the path, all the benefits of using SharedMemory or using packets of rays quickly disappear due to the random nature of the algorithm.
Two techniques are used for rendering: interactive viewing works on modified unidirectional path tracing (Path Tracing), and Bidirectional Path Tracing can be used for final rendering. her frame rate is not very interactive on complex scenes. Sampling by the Metropolis Light Transport method is not yet used, since its effectiveness has not yet been justified, as evidenced by one of the V-Ray developers on the ChaosGroup closed forum:
vlado posted:
Note that the unbiased ‒ rendering is very good - it is based on the Monte Carlo method, which means that in the general case each rendering iteration does not depend on the previous one. That is what makes this algorithm attractive for computing on GPU, multi-core systems and clusters.
To support DX10 and DX11 class hardware and not to rewrite everything anew for each version, you should use DirectX11, which runs on DX10 Hardware with minor limitations. Having support for a wide class of hardware and the algorithm's predisposition to distribution, we made Multi Multi Device rendering, the principle of which is very simple: you need to put the same data, shaders into each GPU and simply collect the result from each GPU as it is ready, restarting the rendering with changes in scene. The algorithm allows you to distribute the rendering on a very large number of devices. This concept is great for cloud computing. However, there are not so many cloud-based GPU providers , and the computer time is also not very cheap.
With the advent of DirectX11 came to the aid of a remarkable technology - WARP (Windows Advanced Rasterization Platform). WARP Device translates your GPU code into SSE ‒ optimized multi-thread code, allowing you to perform GPU computations on all CPU cores. And absolutely any CPU: x86, x64 and even ARM! From a programming point of view, such a device is no different from a device's GPU. It is on the basis of WARP in C ++ AMP that heterogeneous calculations are implemented. WARP Device is also your bro, use WARP Device.
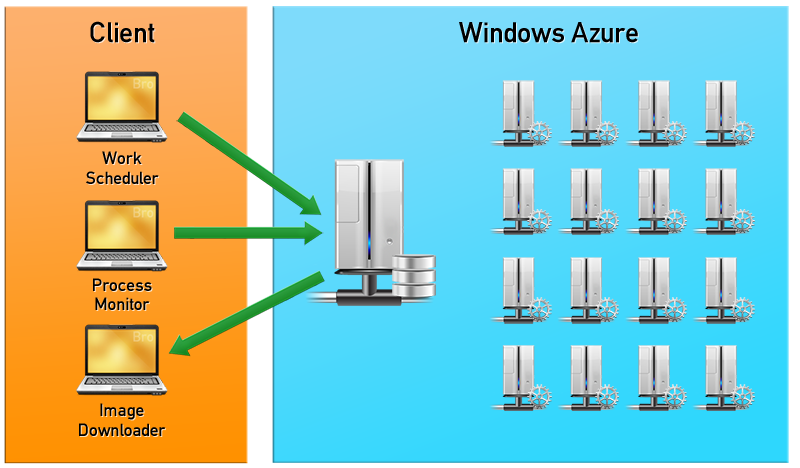
Thanks to this technology, we were able to run GPU rendering in the CPU cloud. We got a bit of free access to Windows Azure through the BizSpark program. Azure Storage was used for data storage, data with scene geometry and textures were stored in Blobs, data on rendering tasks, uploading and downloading scenes are in queues (Queues). To ensure stable operation, three processes were used: the task scheduler (Work Scheduler), the process monitor (Process Monitor), and the process that downloads rendered images (Image Downloader). Work Scheduler is responsible for loading data into blobs and setting tasks. Process Monitor is responsible for maintaining all workers (Worker - Azure Compute node) in working condition. If one of the workers stops responding, then a new instance is initialized, thus ensuring maximum system performance. Image Downloader collects the rendered pieces of images from all workers and transfers the finished or intermediate image to the client. As soon as the rendering task is completed, Process Monitor eliminates the images of the workers so that there are no idle resources for which you would have to pay.
This scheme works well, and for this, it seems to us, the future of rendering - Pixar is already rendering in the cloud . Typically, cloud billing is only for downloaded traffic, which consists of rendered images no larger than a few megabytes. The only bottleneck of this approach is the user's channel. If you need to re-create an animation with the size of asets of several tens or hundreds of GB, then you have problems.
The result of all this work was the RenderBro plug-in for Autodesk 3DS Max, which, as it was intended, should render even on a grandmother’s computer and can use any computing resources.

He is now at the stage of closed alpha testing. If you are a GPU ‒ enthusiast, 3D ‒ artist, you have decided to build an ATI / NVIDIA cluster, you have a lot of different GPUs and CPUs, or any other interesting configuration, let me know if it will be interesting to work together. I'd love to check the render on something like this:

Also, ahead of C ++ AMP version of the render, more serious cloud tests and plugin development for other editors. Join now!
Although the idea of such a render for all video cards has been in the air for a long time, it hasn’t reached a high-quality implementation, especially on Direct3D. In our work, we have come to a very wild bunch and will continue to tell you what brought us to it and how it works.
That is unbiased rendering, or rendering without assumptions, very well outlined Marchevsky in a series of articles
"Tracing the path to the GPU" Part 1 , Part 2 and " Unbiased rendering (rendering without assumptions) ".
In short: this is a rendering that does not introduce systematic errors in the calculation and reproduces physically accurate effects.
')
- global lighting
- soft shadows, realistic reflections
- depth of field and motion blur
- subsurface scattering and more
Due to the physical accuracy and quality of the image, this approach is obviously very resource-intensive. You can solve the problem by transferring calculations to the GPU, since this approach gives an increase in the calculation speed to 50 and once per GPU device.
1200x600 (clickable), AMD Radeon HD 6870, render time: 9 min
Why Direct3D
There are many GPGPU platforms (OpenCL, CUDA, FireStream, DirectCompute, C ++ AMP, Shaders, etc.), but the debate about the optimal choice is still going on, and there is no definitive answer to what is best to use. Consider the main arguments in favor of Direct3D, which have led us to choose the name of this API:
- It works on the entire spectrum of video cards, is emulated on all processor models: the same shader works everywhere
- It is Direct3D specifications that set the direction for consumer iron development.
- Always the first to get the most recent and stable drivers.
- The remaining cross ‒ vendor technologies are unstable or poorly supported.
From OpenCL and Direct3D, we chose the evil that, at least, has stable drivers, honed by decades of the gaming industry, and has better performance in a number of benchmarks. Also, based on the task, CUDA was rejected, despite all the tools, an abundant number of examples and a strong developer community. C ++ AMP was not yet announced at the time, but since its implementation is built on top of DirectX, transferring the render to it will not make any special problems.
The OpenGL / GLSL bundle was also considered, but was quickly discarded due to limitations that are solved in DirectX using DirectCompute (problems of bidirectional path tracing, etc.).
Also, we note the situation with GPGPU consumer hardware drivers, which come out late and are brought to stability for a long time. So, with the release of the NVIDIA Kepler 600 line, gamers immediately got quality Direct3D drivers and more efficient gaming machines, but most of the GPGPU applications lost their compatibility or became less productive. For example, Octane Render and Arion Render, built on CUDA, began to support the Kepler line just a few days ago. In addition, professional GPGPU hardware is not always much better in a number of tasks, as described in the article “ NVidia for professional 3D applications ”. This gives reason to assemble a workstation on the consumer gaming hardware.
Why not Direct3D
In all announcements of DirectX 10‒11 they write that new shader models are ideal for ray tracing and many other GPGPU tasks. But in fact, no one really used this opportunity. Why?
- There were no tools and support
- Research shifted towards NVIDIA CUDA due to strong marketing
- Snapping to one platform
Let's go back a year ago. The last update of the DX SDK was in July 2010. There is no integration with VisualStudio, there are practically no GPGPU developer communities and qualitative examples of normal computing tasks. But what really is there, there is no syntax highlighting for shaders! Sane debugging tools either. PIX is not able to withstand multiple nested loops or a shader of 400+ lines of code. D3DCompiler could crash through time and compile complex shaders for tens of minutes. Hell.
On the other hand, weak implementation of the technology. Most of the scientific articles and publications were written using CUDA, and sharpened by NVIDIA hardware. The NVIDIA OptiX team is also not particularly interested in research for other vendors. The German company mentalimages, which for decades has accumulated experience and patents in this area, is now also owned by NVIDIA. All this creates an unhealthy imbalance in the direction of one vendor, but the market is the market. For us, this all meant that all new GPGPU tracing and rendering techniques must be investigated anew, but only on DirectX and on ATI and Intel hardware, which often led to completely different results, for example, on the VLIW5 architecture.
Implementation
Eliminate problems
Before describing the implementation, here are some useful tips that helped us in the development:
- If possible, go to VisualStudio2012. The long-awaited integration with DirectX, built-in debug shaders, and, oh, a miracle, HLSL syntax highlighting will save you a lot of time.
- If VS2012 is not a variant, you can use tools like NVidia Parallel Nsight, but again there is a binding to one type of GPU.
- Use the Windows 8.0 SDK, this is your bro. Even if you are developing on Windows Vista / 7 and older versions of VisualStudio, you will have the latest D3D libraries at your disposal, including the fresh D3DCompiler, which shortens the compiler time for shaders by 2-4 times and works stably. There is a detailed manual for configuring DirectX from Windows 8.0 SDK.
- If you are still using D3DX, consider dropping it, this is not a bro. The Windows 8.0 SDK stopped supporting it for very obvious reasons.
Rasterization vs tracing
Despite the fact that DirectX is used, there is no talk about rasterization. Standard Pipeline Vertex, Hull, Domain, Geometric and Pixel Shaders are not used. We are talking about tracing the paths of light by means of pixel and Compute shaders. The idea of combining rasterization + tracing, of course, arose, but turned out to be very difficult to implement. The first intersection of the rays can be replaced by rasterization, but after that it is very difficult to generate secondary rays. Often it turned out that the rays were under the surface, and the result was wrong. The guys from Sony Pictures Imageworks, who are developing Arnold Renderer, came to the same conclusion.
Rendering
There are two basic rendering organization approaches:
- All calculations take place in the mega-core of the GPU program, which is responsible for both tracing and shading. This is the fastest rendering method. But if the scene does not fit in the memory of the GPU, then either the scene will be swapped, or the application will break.
- Out Of Core Rendering: Only the geometry of the scene or part of it is transmitted to the GPU, along with the ray buffer for tracing, and a multi-pass ray tracing is performed. Shading is done either on the CPU, or another pass on the GPU. Such approaches are not famous for amazing performance, but they allow rendering scenes of production size.
We stopped at the first option using shaders for GPGPU, but before that or rendering, you need to prepare the geometry and data about the scene, correctly placing them in the memory of the GPU.
Scene data includes:
- geometry (vertices, triangles, normals, texture coordinates)
- accelerating structure (nodes Kd ‒ tree or BVH)
- surface materials (type, colors, texture pointers, reflective exponents, and more)
- texture materials, normal maps, etc.
- light sources (singular and extended)
- camera position and parameters, such as DOF, FOV, etc.
No vertex and index buffers are used when rendering. In Direct3D11, the data is unified, everything is stored in the same format, but you can tell the device how to look at it: like Buffer, Texture1D / 2D / 3D / Array / CUBE, RenderTarget, etc. Data that is more less linear access is best stored in the form of buffers. Data with random access, for example, accelerating the structure of the scene, it is better to store in the texture, because with frequent calls, part of the data is cached.
Quickly changing small data chunks are reasonably stored in constant buffers, these are camera parameters, light sources and materials, if there are not many of them and they fit into a buffer of 4096 x float4. In interactive rendering, changing the camera position, setting up materials and light is the most common operation. The change in geometry occurs somewhat less frequently, but the constant memory is still not enough to accommodate it.
Because GPU memory is relatively small, you need to use smart approaches to its organization and try to pack everything that you can pack and use data compression. The textures of the materials we place in a multi-layered texture atlas, because The number of GPU texture slots is limited. Also, the GPU has built-in texture compression formats - DXT, which are used for texture atlases and can reduce the size of textures by up to 8 and times.
Texture packing in satin:
As a result, the location of the data in memory looks like this:
It is assumed that the data of light and materials can fit in the constant registers. But if the scene is quite complicated, the materials and the light will be placed in the global memory, where there should be enough space for them.
Moving to rendering: in the vertex shader, draw a quad, screen size, and use the mapping technique of pixels to pixels so that each pixel of the pixel shader rasterizes the correct texture coordinates and, consequently, the correct x and y values on the screen.
Further, for each pixel in the shader, a ray path tracing algorithm is calculated. This method performs GPGPU computations on pixel shaders. Such an approach may not seem to be the most optimal, and it would be more reasonable to use DirectCompute, for which no vertex shaders and screenshots should be created. But numerous tests have shown that DirectCompute is 10-15% slower. In the task of tracing the path, all the benefits of using SharedMemory or using packets of rays quickly disappear due to the random nature of the algorithm.
Two techniques are used for rendering: interactive viewing works on modified unidirectional path tracing (Path Tracing), and Bidirectional Path Tracing can be used for final rendering. her frame rate is not very interactive on complex scenes. Sampling by the Metropolis Light Transport method is not yet used, since its effectiveness has not yet been justified, as evidenced by one of the V-Ray developers on the ChaosGroup closed forum:
vlado posted:
“... I came to the conclusion that MLT is way overrated. It can be much more than a well-implemented path tracer. This is because MLT can’t take a sample of ordering (for example, quasi-Monte Carlo sampling, or we can use it, or N-rooks sampling, etc.). The MLT renderer must be able to reduce the number of scenes (like an open skylight scene). ”
Multi ‒ Core. Multi ‒ Device. Cloud
Note that the unbiased ‒ rendering is very good - it is based on the Monte Carlo method, which means that in the general case each rendering iteration does not depend on the previous one. That is what makes this algorithm attractive for computing on GPU, multi-core systems and clusters.
To support DX10 and DX11 class hardware and not to rewrite everything anew for each version, you should use DirectX11, which runs on DX10 Hardware with minor limitations. Having support for a wide class of hardware and the algorithm's predisposition to distribution, we made Multi Multi Device rendering, the principle of which is very simple: you need to put the same data, shaders into each GPU and simply collect the result from each GPU as it is ready, restarting the rendering with changes in scene. The algorithm allows you to distribute the rendering on a very large number of devices. This concept is great for cloud computing. However, there are not so many cloud-based GPU providers , and the computer time is also not very cheap.
With the advent of DirectX11 came to the aid of a remarkable technology - WARP (Windows Advanced Rasterization Platform). WARP Device translates your GPU code into SSE ‒ optimized multi-thread code, allowing you to perform GPU computations on all CPU cores. And absolutely any CPU: x86, x64 and even ARM! From a programming point of view, such a device is no different from a device's GPU. It is on the basis of WARP in C ++ AMP that heterogeneous calculations are implemented. WARP Device is also your bro, use WARP Device.
Thanks to this technology, we were able to run GPU rendering in the CPU cloud. We got a bit of free access to Windows Azure through the BizSpark program. Azure Storage was used for data storage, data with scene geometry and textures were stored in Blobs, data on rendering tasks, uploading and downloading scenes are in queues (Queues). To ensure stable operation, three processes were used: the task scheduler (Work Scheduler), the process monitor (Process Monitor), and the process that downloads rendered images (Image Downloader). Work Scheduler is responsible for loading data into blobs and setting tasks. Process Monitor is responsible for maintaining all workers (Worker - Azure Compute node) in working condition. If one of the workers stops responding, then a new instance is initialized, thus ensuring maximum system performance. Image Downloader collects the rendered pieces of images from all workers and transfers the finished or intermediate image to the client. As soon as the rendering task is completed, Process Monitor eliminates the images of the workers so that there are no idle resources for which you would have to pay.
This scheme works well, and for this, it seems to us, the future of rendering - Pixar is already rendering in the cloud . Typically, cloud billing is only for downloaded traffic, which consists of rendered images no larger than a few megabytes. The only bottleneck of this approach is the user's channel. If you need to re-create an animation with the size of asets of several tens or hundreds of GB, then you have problems.
Result
The result of all this work was the RenderBro plug-in for Autodesk 3DS Max, which, as it was intended, should render even on a grandmother’s computer and can use any computing resources.
He is now at the stage of closed alpha testing. If you are a GPU ‒ enthusiast, 3D ‒ artist, you have decided to build an ATI / NVIDIA cluster, you have a lot of different GPUs and CPUs, or any other interesting configuration, let me know if it will be interesting to work together. I'd love to check the render on something like this:
Also, ahead of C ++ AMP version of the render, more serious cloud tests and plugin development for other editors. Join now!
Source: https://habr.com/ru/post/152033/
All Articles