Creating handwriting recognition technology (updated)
 In connection with the practical criticism of the Habrahabrovets, I radically redid the post. I hope this option will be appreciated more positively.
In connection with the practical criticism of the Habrahabrovets, I radically redid the post. I hope this option will be appreciated more positively.For almost two years I have been working in a company that has been engaged in digitizing archive and library funds. Scanning of information has been put on stream and we receive tens of thousands of graphic images per day, which must be recognized and unloaded by the customer. My task is to create a conveyor technology for recognizing information from graphic images.
In this post I want to share my experience and talk about handwriting recognition technology.
')
Auto Recognition Testing
Printed text
ABBYY FineReader is the undisputed leader in this segment. Recognition programs are developed with a bias on the standard documentation of companies that are the main consumers of software. They are not designed for non-standard formats, so programs cannot give a confidence level above 80%.
When processing library cards of ten to twenty years old, ABBYY FineReader cannot give a result above 60% confidence. See the screenshot below.
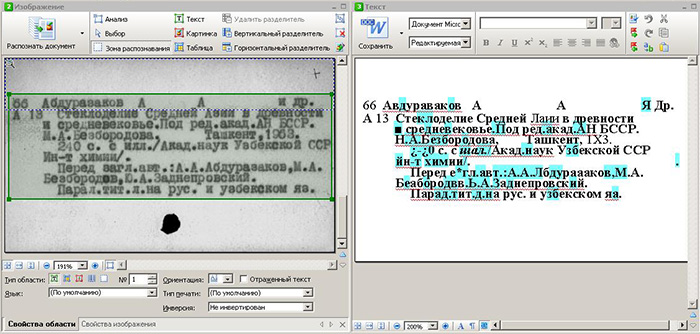
Handwriting
ABBYY FineReader has versions of the program where, after training, it must recognize the text. The essence is simple - the product is an empty neural network. The user needs to fill it manually. If a user tries to recognize multiple handwriting, the program will not be able to produce a result. Having spent a week of time learning such a software solution, in the end, we did not get a positive result.
The use of automated programs for handwriting recognition today is almost impossible. Entering information from a graphic image by an operator is the only way to obtain digitized information. See the screenshot below.
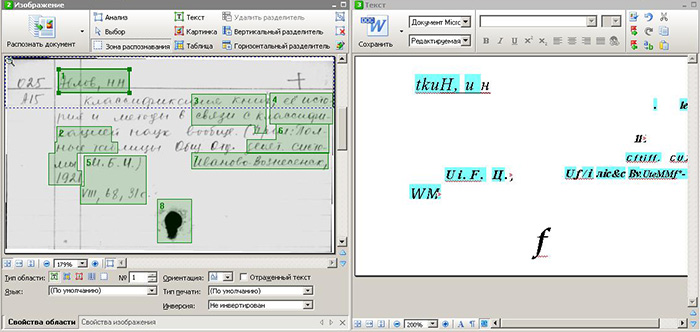
Creation of technology of manual recognition
Then we will talk about the technology that had to be created. There was an algorithm that took six months to implement. Below is the procedure for obtaining the recognized text:
- Scan - stream scanner performs itself.
- The division of the array of graphic images on the basis of the subcategories - this and all further steps are performed by a person. This step allows you to increase the efficiency of input.
- Checking the work done in the previous step.
- Data input. All information is logically divided into fields and filled in parts. Each data array has its own specifics and its own input rules:
- if the information is confidential - the image is automatically cut into pieces, and each operator receives only part of the information for input;
- with a large number of fields - the fields of one card are divided between several operators.
- Validation of input data. The presence of errors affects the pay of people who enter data.
- A number of general automated checks on the database.
- Shipment of finished parts of the array to the customer.
The project was called the "Center for Remote Employment" and began to gain momentum. The first month had to constantly correct the mistakes that came out during the run-in. Then the process was adjusted, and the software began to work stably and unload ready-made data arrays.
As the load grows - new problems on the optimality of algorithms and the speed of their processing began to arise on the server. While they are being solved locally, but it is quite possible that soon the whole system will have to be optimized.
The whole project was implemented with the support of the Ministry of Culture and Tourism of Ukraine, you can read more on the link .
Briefly about the system
Programming language: PHP.
Database: MySQL.
CMS, Framework: none, development started from scratch.
At last
For those who are interested to see the various versions of the results of the work of ABBYY FineReader, I posted additional screenshots by reference .
If this post is accepted positively, I will publish a sequel and talk about how library automation technology has been built in the CIS countries. I will pay special attention to the module with interesting features, which is responsible for displaying information on the Internet.
Source: https://habr.com/ru/post/151856/
All Articles