How I Invented the Bike, Learning Technology
 Repeatedly heard the statement that the programming language is best studied in the process of creating something. Could not disagree with this, and decided that this applies not only to the language, but also to all sorts of technologies coexisting with this language.
Repeatedly heard the statement that the programming language is best studied in the process of creating something. Could not disagree with this, and decided that this applies not only to the language, but also to all sorts of technologies coexisting with this language.To tread the uncharted path is not easy, it is much easier to study how someone treads this path in front of you. I don’t have a soul to study documentation, I use it as a reference book, and it takes too much time and effort to learn something from scratch, because the authors usually assume that the reader has more knowledge, almost everything he needs is already known. Bicycle themes also highlight the process of learning, walking on a rake and everything else. Unfortunately, I didn’t find enough detailed articles on topics I was interested in, studied in fragments, and decided to write an article myself, hoping to make life easier for those who can follow.
Most of all I wanted to master the process, or the approach, well, or ideology, if you will, which is called TDD, aka Test-Driven Development. Also, as an assistive technology, in terms of tests, the test framework Moq was used. Looking ahead, I’ll say that it wasn’t possible to develop fully correctly, because the skills of the “architect” also need experience. I had to redo some blocks, and the test cases themselves, which I wrote, not yet fully aware of what and how the class should do. However, things got off the ground, the experience was gained, and the next time it should be easier. The second technology, which has long been itching to master, is dependency injection and IoC containers. In development, I used Autofac, which is the most impressive to me.
Theme for cycling
It did not take long to choose, the decision came literally on its own - to write your own logger with filtering and a configurable output format. I wanted to write my first article about ASP.Net, and the MVC3 framework. Although now it makes sense to move towards MVC4. Among the technologies, by the way, was supposed to use the Entity Framework. On Habré there is already an article on this topic, but the author has disappeared, without finishing the promise.
So why am I interrupted by a logger? In the process of creating that application, of course, there was a need for logging. I was advised to take the NLog available in NuGet, but after studying it, I came to the conclusion that writing my logger is not only interesting, but also justified. I did not check it myself, but judging by the reviews on the Internet, log4net is slower than it, therefore I did not consider it.
I myself work in telecom, and I already had to work with the logger when there was a need for functionality that was not available in standard syslogs. This is filtering by id. When the site processes 30 thousand calls per hour, then even if the bug is 100% reproducible on it, finding it in megabytes and even gigabytes of logs is not so easy. Yes, and not all systems allow you to store gigabytes of logs, some where there are systems that only have a few minutes of traffic during peak hours and the call itself may be longer in length, that is, the beginning or end of the call may not be included in the log. Therefore, “from above” an idea came to select the right one, marking the call so that only he got into the logs. Well, or a few calls, but only to the number where this bug periodically happens. The syslog was successfully replaced by a macro that compares the identifier in the session with the list of identifiers given by the operator. The identifier was tied to both the unique address of the terminal and the dialed number. In my ASP.Net application it was supposed to filter by userid. Of course, here it may not be very justified, but since I decided that the logger needs this feature, then so be it.
I found the second reason about studying the source code for NLog. In it, almost all actions are performed in the context of the calling thread, asynchronously only the direct write to the target is performed. That, as I later saw, causes considerable damage to performance.
Moving operations to a separate thread
I immediately encapsulated this operation into a separate class. The class will start a stream in which all messages will be processed, and allow these messages to be sent to this thread. The message will contain the text of the log, level, and other information. It is necessary to solve the task - to minimize the number of actions in the context of the stream that sends logs.
As a basis, I took the example of ThreadSync from Language Samples, which are included in Visual Studio. First class interface:
public delegate void ReceiveHandler<T>(T item); public interface IQueued<T> { event ReceiveHandler<T> OnReceive; event Action OnTimeout; bool Active { get; } void setTimeout(int timeout); void Send(T msg); void Terminate(); } The flag is set at the beginning of the internal method ThreadRun, and cleared at the end. The OnReceive event occurs when a stream has received a new message. The event delegate type is created to avoid casting the argument type. The timeout is created in order to allow not to write directly to the disk, but first to the buffer, for example, in StringBuilder. After the specified time after receiving the last message, the OnTimeout event will be triggered once so that the last log received is guaranteed to hit the disk.
Option in class two, you can choose depending on any reasons. One option starts its thread, but needs to call Terminate.
thread = new Thread(ThreadRun); thread.Start(); The second class implementing the same interface adds its method to the standard ThreadPool. It has its drawbacks, in particular, if the main application already uses not many threads from the pool, then this thread can be very late with the start. One joy - it does not need to be terminated with a call to Terminate (), it will close itself by closing the application.
ThreadPool.QueueUserWorkItem(ThreadRun); The designer accepts a ManualResetEvent as input, which can be fed to several classes that operate with streams, and then use it as a centralized application termination event. In the logger, I did not use it, but just in case I added this feature. In addition to the completion event, an event is also used for work, which means that a new message has entered the queue. It looks like this
EventWaitHandle[] events = new EventWaitHandle[2]; ... events[0] = new AutoResetEvent(false); events[1] = terminateEvent ?? new ManualResetEvent(false); It is quite obvious that the task of the Terminate method is to set events [1] to one.
To store the transmitted messages, I used the queue queue; The Send () method is simply copied from an example:
lock (queSync) { queue.Enqueue(msg); } events[0].Set(); To receive messages on the other side, I decided to resort to a little trick to minimize the blocking time of the queue with a “gathering” stream. That is why lock is not made on the queue itself, but on a separately created object. The receiving thread spins inside an infinite loop, the output of which will be produced if the index is equal to one, which means that events [1] triggered, either from the Terminate method or from the outside, as I said earlier.
while ((index = WaitHandle.WaitAny(events, currentTimeout)) != 1) The WaitAny method blocks the flow until one of the events triggers, or a timeout, by default equal to Infinite. That is, the logger thread will sleep and does not affect the performance of the application until it starts sending logs. When triggered, we first check to see if there was a timeout, and activate the corresponding event.
if (index == WaitHandle.WaitTimeout) { OnTimeout(); currentTimeout= Timeout.Infinite; } The second line appeared here thanks to unit tests, when I encoded it, I missed it. Further, otherwise, the messages from the queue must be retrieved, and with each of them, trigger the OnReceive event. The “trick” I mentioned earlier is visible in the code.
Queue<T> replacement = new Queue<T>(); Queue<T> items; lock (queSync) { items = queue; queue = replacement; } foreach (T t in items) { OnReceive(t); } currentTimeout = timeout; For all the critical moments of this class, or of a module, I’ve walked, its code, like all the other classes, can be found in the repository, I’ll hang a link at the end of the article and then I’d not repeat this disclaimer,
Already at the time of writing, a crazy idea occurred to me to do the same using ConcurrentQueue, naturally without the above tricks, but completely without blocking. And at the same time it is necessary to leave the possibility of creating both types of threads. Therefore, it was decided to encapsulate the creation of a stream behind its interface, which I will call IStarter, each class will consist of a single method. By the way, here it would be quite possible to use the lambda expression, but the esthete in me resisted this. As a result, what should turn out to be similar to the well-known pattern bridge, where "on this side of the bridge" there are two classes, one with locks, the other with an interlock, and "on the other side of the bridge" two options for starting the flow for them, and they are used between be able to in any combination. The whole charm of the ideology "to interact with the interface, and not with the implementation" (c) GoF here is expressed not only in the fact that the other classes interacting with the data will not have to be touched, but also in the fact that unit tests also do not need to be changed . Quite quite. It is only necessary to change the polymorphic method of creating specific objects, which feeds all the options to these tests.
')
TDD rudiments
Little poteoretiruyu on. At first, using the example of the class that was first, and the second was the same, the development behavior failed to fail TDD, where the tests first, then the code itself. The path of my development went through the following stages - writing working code, then writing test cases, then correcting both the first and second, bringing it to standard. After that, the tests are “recognized as true,” and the refactoring, which follows later, may well rely on them. Why do I think that this approach has the right to life, at least for a beginner: If we consider the simplest function A = B + C, then testing this function suggests the formula C1 = A - B, and then the conclusion of the success of the test based on comparison C == C1. Errors here can be contained both in the tested function and in the testing one. Moreover, since it has more actions, an error is more likely. At this point, one may wonder why, then, testing is needed at all, but the answer is naturally already there, everything is formulated before us. In order for the test to show “passed”, it is necessary that one of the conditions be fulfilled. The absence of errors in both functions, or the simultaneous presence of an error there and there. The probability that both errors will occur is less than the probability of each error separately, especially the presence itself is not enough, it is also necessary that the errors be synergistic, that is, compensate for each other's influence, the probability of which is even lower. That is, all efforts to write tests are directly aimed at reducing the likelihood of errors. However, when writing both tests and code by the same person, the probability that he will make the same error is somewhat higher. Well, okay, as it seems to me, for a bicycle and what is is already good.
Let's go over to writing the first tests. To do this, first create a test pattern by clicking on the interface name IQueued with the right button and selecting the appropriate menu item. So, what you need to test this class. It is supposed to be tested in isolation, then it is necessary to make mocks (imitators) of classes that interact with the sabzhevy class. Another point is that since the target of the test is the interface, and there were two specific classes to test, and later 4 combinations 2 to 2 became later, it makes sense to immediately reward the abstract modifier and add a generic parameter to it.
[TestClass()] public abstract class IQueuedTest<T> Since the class is abstract, tests will not be performed directly on it, of course, they will not, instead all test classes inherited from it will be executed.
First of all, we need a service class consumer simulator.
class Tester<T1> This class will subscribe to the events of the class being tested, count the events triggering, and remember what came about in this event.
public Tester(IQueued<T1> tested) { tested.OnReceive += Received; tested.OnTimeout += TimeOut; } void TimeOut() { timedCount++; } void Received(T1 item) { Thread.Sleep(delay); receivedCount++; lastItem = item; } In addition to this inner class, you will need methods to create specific objects that we oblige all heirs to override.
protected abstract IQueued<T> createSubject(); protected abstract T CreateItem(); So, actually to writing tests. By the way, when reading such articles, I noticed that the authors omit the rake, and bring a ready-made solution. I will try to stop on some rake a little more. The first problem I encountered is the very delayed start in the thread pool. When you start the application, the pool keeps only a few threads, and the new starts only with a delay, which is measured in tenths of a second. A test framework seems to execute tests in parallel. Because of this, tests with a “manual” flow were successful, and some passed with a flow from the pool, some fell. Therefore, there are two options, select all the tests in the same "long" method, which will be executed faster, but will give only one general verdict, or come up with workarounds. I came up with the following:
void ActivationTestHelper(Tester<T> tester, IQueued<T> subject) { int retry = 30; while (!subject.Active && retry > 0) { retry--; Thread.Sleep(SleepDelay); } Assert.AreEqual(true, subject.Active); } 30 attempts to "wait" until the stream is activated, after which only proceed to the test. The helper will be called immediately after creation.
And, once again - so, to writing tests. The first test to send-receive messages. Since we know that the task of the class is to transmit to another thread, we need to make sure that the tester class does not receive the message in the context of the transmitting stream, then make sure that it successfully receives after. For this (for the first), by the way, in the code of the Received method, the tester has a delay of 50ms. If this delay occurs in the calling thread, then the first Assert will fail the test.
[TestMethod()] public void SendTest() { var subject = createSubject(); var tester = new Tester<T>(subject); ActivationTestHelper(tester, subject); T item = CreateItem(); tester.delay = SleepDelay; subject.Send(item); Assert.AreEqual(0, tester.receivedCount); Next, to make sure that the message is transmitted, we will wait 100ms and check the received. In principle, these values can be reduced, as long as the second delay is greater than the first, but here, I think it is not fundamental. Do not forget to complete the stream, to "give way" to the following tests.
Thread.Sleep(SleepDelay2); Assert.AreEqual(1, tester.receivedCount); Assert.IsTrue(tester.lastItem.Equals(item)); subject.Terminate(); } Next, a timeout test. Also create objects, execute activation helper. Let's set a timeout and check that it was not called in the context of the calling thread, but was called after. And only once.
[TestMethod()] public void TimeoutTest() { var subject = createSubject(); var tester = new Tester<T>(subject); subject.setTimeout(SleepDelay); ActivationTestHelper(tester, subject); T item = CreateItem(); subject.Send(item); Assert.AreEqual(0, tester.timedCount); Thread.Sleep(SleepDelay3); Assert.AreEqual(1, tester.timedCount); } For this test, a delay of 200ms is specified, four times the timeout value, and it was this test that caught my first mistake, an underprint, which I mentioned earlier. This turned out to be pleasant and unit tests, that the absolute majority of errors does not reach not only “production”, but even alpha trial. These errors, of course, would have been detected there, but the work spent on writing tests would still have to be done for debugging. It turned out a sort of time-management technique that moves a certain amount of work from the period when the emergency roll to the period of "lazy" development. And this is all without even mentioning the invaluable help in refactoring, which I invented myself along the way.
The remaining test is the completion of the stream. We must make sure that the stream is stopped and nothing is transmitted. Lowering the steps common to all tests, we get the following:
public void TerminateTest() { ... subject.Terminate(); subject.Send(item); Thread.Sleep(SleepDelay3); Assert.AreEqual(0, tester.receivedCount); Assert.AreEqual(0, tester.timedCount); } There are only three tests in the interface, but there are two specific classes, two more options for starting the stream and beyond that, I decided to check separately how it works with classes and structures as a message to be passed. For this purpose, 8 specific test classes are created, one of which I will give, and the number of specific test cases turns out to be 24. Test structure:
public struct TestMessageStruct { public string message; //object reference field public int id; //value field } And actually a specific test class that tests the variant: blocking queue, normal flow, structure.
[TestClass()] public class IQueuedLockRegTest : IQueuedTest<TestMessageStruct> { protected override IQueued<TestMessageStruct> createSubject() { return new LockQueued<TestMessageStruct>(new RegularThreadStarter()); } protected override TestMessageStruct CreateItem() { var item = new TestMessageStruct(); var rnd = new Random(); item.id = rnd.Next(); item.message = string.Format("message {0}", item.id); return item; } } It was specific test classes that created specific experimental objects and had to be redone in this connection, if you can call it that, refactoring. And they had to double their number, but, as you can see, it takes significantly less time and effort than when writing and thinking about the tests themselves.
Logger interface and first filter layer
I decided to make the interface outward like in NLog, without further ado. I just called the static class LogAccess, for some reason it seemed to me more logical in meaning. He himself does nothing, only proxies calls. For this reason, he does not participate in tests, therefore I will not dwell on it, I will only list the main methods visible "outside", the first method allows you to get the actual logger to spam messages, the next two control the filtering by level, the last by id. The name, or category, of the logger, which is present in the first filtering layer, means that the execution of this filtering before passing through the class described in the previous section, that is, the level can be set separately for each category of logs. The absence of a category on the second filtering layer, respectively, means that this filtering is already done behind, in the stream of the logger.
Logger GetLogger(string category) void SetLevel(string category, int level) void SetLevelForAll(int level) void FilterAddID(int id) void FilterRemoveID(int id) The second class, which is visible from the outside, is LogLevel. The levels in the sense I took from the telecom. Here I decided to simplify relative to NLog, and use the usual int as a level, so as not to subtilize with the comparison of levels, etc.
He added only the All level to make two levels of debug, reduced and detailed, which sometimes was not enough in practice.
public const int Invalid = 0; public const int Always = 1; public const int Fatal = 2; public const int Error = 3; public const int Warning = 4; public const int Info = 5; public const int Event = 6; public const int Debug = 7; public const int All = 8; public const int Total = 9; Also included in the class property Default, to set the level of LogAccess.
Well, the most important thing that can be seen from the outside is the Logger interface. I deliberately did not add the prefix I.
public interface Logger { /// <summary> /// Method for unrecoverable errors. /// </summary> /// <param name="message"></param> /// <param name="ex"></param> void Fatal(string message, Exception ex = null); /// <summary> /// Method for external errors, such as user input or file access. /// </summary> /// <param name="message"></param> /// <param name="id"></param> /// <param name="ex"></param> void Warning(string message, int id = 0, Exception ex = null); /// <summary> /// Method for regular debug logging. /// </summary> /// <param name="message"></param> /// <param name="id"></param> void Debug(string message, int id = null); } Methods for errors are not tied to identifiers, only the levels of Warning and above.
Next, consider the class of a specific logger to show. in what way the minimization of the performance taken by the logger from the calling thread is achieved. By the way, the logger interface has an extended version, not visible from the outside, which adds the SetLevel method.
class CheckingLogger : InternalLogger { bool[] levels = new bool[LogLevel.Total]; Sender send; string category; public CheckingLogger(string category, Sender sender, int level) { this.send = sender; this.category = category; SetLevel(level); } public void SetLevel(int level) { for (int n = LogLevel.Fatal; n < LogLevel.Total; n++) { levels[n] = (n <= level); } } public void Error(string message, Exception ex = null) { if (levels[LogLevel.Error]) { send(new LogItem(category, LogLevel.Error, message, ex: ex)); } } One spamming method is enough for consideration, it is clear that it checks the Boolean value from the array, and sends it via the Sender delegate. The second variant of the logger, instead of the boolean array, uses the Sender array, the delegate to the empty method is inserted into the disabled level, and there is no check in the sending method, sending immediately. According to the results of testing, the difference in performance is insignificant, perhaps testing on different platforms would give an answer. Logger tests are fairly simple, it checks if the message is in Sender, when it should, and when it should not. Here I also stumbled upon typos and copy-paste errors, since many almost identical methods, the difference is not a cursory glance.
I did not think of which section to enter the class, or rather the LogItem structure used for the actual transfer of the logs, I will give here, omitting the constructor, only the content. From it, by the way, it is clear that the id for one message can be set to more than one, it is necessary either for Broadcast, or, in the case of a call, to indicate two identifiers: the caller and the answering call. Methods in previous classes are duplicated for this purpose, only deprived of attention.
struct LogItem { public readonly String category; public readonly String message; public readonly int[] ids; public readonly int level; public readonly Exception ex; public readonly DateTime time; } Dependency injection
In this section, I will give an example of using an IoC container. The next class in question is the container of loggers. The name with the IoC container is not related, just the same. It provides the GetLogger method, where the method of the LogAccess class is proxied. NLog, judging by the comments in the code, does not guarantee that the twice called GetLogger method with the same category will produce the same logger instance. I thought and decided that this method would not be a bottleneck, and put a general synchronization on it, in this case the instance should be guaranteed the same. The log container stores all previously created loggers and distributes SetLevel to them, also proxied from LogAccess.
So, we create the IoC container, the further configuration is placed between the following two lines:
var builder = new ContainerBuilder(); IContainer container = builder.Build(); From the above it is clear that the class should be singleton. This is achieved quite simply:
builder .RegisterType<LoggerContainer>() .SingleInstance(); And by the following method we can get a link to our singleton.
Container .Resolve<LoggerContainer>(); So that the container of logs itself could use the services of the IoC container from which it was created, I added the IComponentContext parameter to it in the constructor. This allows you to take out the creation of a class to the outside, and change specific classes, for example, to classes with enhanced functionality, without changing the code that uses it, but only by changing the configuration, which including it is possible and not to set in the code in general, but to load from xml. Actually, this replacement of the inner creation by the outer creation is called dependency injection. Actually, the method that a particular logger receives from the context:
private InternalLogger CreateLogger(string category) { return context .Resolve<InternalLogger>(new NamedParameter[]{ new NamedParameter("category", category), new NamedParameter("level",LogLevel.Default) }); } In addition, this example shows how to set specific class parameters for the constructor from the place of the call, and not in the container configuration, which in this case remains as simple as in the previous case. The only difference is that we do not have a singleton and the access point is the interface here, and not the class itself.
builder .RegisterType<CheckingLogger>() .As<InternalLogger>(); Here you can see some negative, with which I don’t know how to continue, except to write in the comments to the interface which input parameters, by name and type, should be present in the constructor of a particular class. Difficult to diagnose errors, which in the ordinary case would be eliminated by the compiler, are just waiting to happen here. Changing the configuration of the container, you may not know about it, because for this you will need to search for references on the interface. Probably in this case it is better to use a “classic” factory.
Further, what gives the use of IoC: container during unit testing. For the test, you can and should create your own container:
[TestClass()] public class LoggerContainerTest { IContainer testContainer; public LoggerContainerTest() { var builder = new ContainerBuilder(); builder .Register<LoggerContainer>((c, p) => new LoggerContainer(c.Resolve<IComponentContext>())); builder .RegisterType<LoggerMock>() .As<InternalLogger>(); testContainer = builder.Build(); } Here is illustrated another feature that is in Autofac, it allows you to configure the good old new, which actually will be called when Resolve, which works, of course, much faster than reflection.
It remains to bring a fragment of one of the test methods.
LoggerContainer lc= testContainer .Resolve<LoggerContainer>(); var logger1 = lc.GetLogger(cat1); var logger2 = lc.GetLogger(cat2); var logger3 = lc.GetLogger(cat1); Assert.AreEqual(logger1, logger3); Assert.AreNotEqual(logger1, logger2); Moq Test Framework
Another useful technology that allows you to simplify the writing of tests. I will show its application on the example of the next class, which I called the log collector or LogCollector. It uses the same IQueued for decoupling with the sending streams, filters by the identifier, and the second dependency has a class that writes to the file and performs the rotation.
I will not describe in detail how it works, everything is quite simple and obvious, I’ll dwell in general on one more class, which, before writing to the file, constructs a line from LogItem. I decided to make it configurable, it has long been interesting to solve such a problem.
Configuration example NLog: layout = "$ {longdate} $ {uppercase: $ {level}} $ {message}".
And an example of my logger configuration is LogMessageFormat = \ d \ l \ m \ r \ n.
It is displayed in exactly the same form, date, level, the message itself and the line break. Specifically customized output format, so you can directly compare performance. Also it was in this line that I made it possible to add an identifier, an exception with its setraise, and, well, literal lines between all these identifiers. The construction proceeds along a chain, each following constructor throws its own part of the message into the StringBuilder from the transmitted LogItem. The chain is built up once, when the master line is parsed.
The main task of the class is quite simple, so I will not give the code that implements it, I’ll dwell on filtering a bit. Since there is also a synchronization task, that is, a method call that adds or deletes an identifier comes from another thread. One way is to block the list, or HashSet, will have an impact on performance. I went a little different way, I also saw such an opportunity provided by the language a long time ago and wanted to find a use for it. The essence of the solution is to transfer an anonymous Action method via a non-blocking queue. filterQue = new ConcurrentQueue <Action <HashSet >> ();
The filtering method checks whether the queue is empty at every filtering attempt, which should work faster than capturing the monitor, and if it is not empty, it executes the received method in the context of the logger stream.
Action<HashSet<int>> refresh; while (!filterQue.IsEmpty) { if (filterQue.TryDequeue(out refresh) && refresh != null) { refresh(filter); } } The caller method, instead of referring directly to the network, puts the desired delegate in the queue.
filterQue.Enqueue((x)=> { x.Add(id); }); Returning to Moq - in the above classes, I created mocks myself, which requires a lot of additional code, and it can be inconvenient and ugly, especially when you need to test a single class method. Moq allows you to automatically create a class that either implements the specified interface, or inherits the specified class with overriding all virtual methods. Here you can immediately see the restriction - you can’t make a mock on a class with non-virtual methods. But, as we were bequeathed to GoF, we need to program “to the interface”, that is, preferably all classes should be equipped with this, which, in general, allows us to apply all the above-described techniques and technologies, apart from what facilitates and formalizes chtoli, development at all.
Another nuance of working with Moq is when creating tests, in some cases the studio itself adds an attribute to the assembly that allows access to the internal classes from the test project assembly, sometimes you have to add it yourself, and for Moq to also have access to the classes and interfaces, which need to be simulated, it is necessary to add access for it. To do this, you need to find the AssemblyInfo.cs file in the project and add or modify the line so that it looks like this:
[assembly: System.Runtime.CompilerServices.InternalsVisibleTo("LoggerTest"), System.Runtime.CompilerServices.InternalsVisibleTo("DynamicProxyGenAssembly2")] The first thing to test is for the collector to transfer the received message to the class that creates the flow isolation.
Mock decided not to do the message itself, since it is only transmitted to and fro by this class, and does not contact it, does not call its methods, does not read its fields.
LogItem message = new LogItem(category, level, msg, ids, GetException()); var qThread = new Mock<IQueued<LogItem>>(MockBehavior.Strict); var writer = new Mock<ILogWriter>(MockBehavior.Strict); qThread .Setup(s => s.Send(It.IsAny<LogItem>())); writer .Setup(s => s.GetTimeout()) .Returns(timeout); qThread .Setup(s => s.SetTimeout(It.IsAny<int>())); LogCollector target = new LogCollector(qThread.Object, writer.Object); qThread .Verify(s => s.SetTimeout(It.Is<int>(a => a == timeout))); target.Send(message); qThread .Verify(s => s.Send(It.Is<LogItem>(i => i.Equals(message))), Times.Once()); } In case explanations are needed: the first two lines create dependency tutors. The Strict parameter means that the mock will throw an exception if classes have methods called that are not configured before use, thereby zacheliv test.
The next call marks the Send method of IQueued mock, indicating that it will be called during the test. Here you can also specify preconditions, if there are several methods, then after the test all preconditions can be checked by calling VerifyAll (). I stopped at a detailed, redundant description of the test. The next line means that the GetTimeout method should be called, and also indicates the mock that it should return. The next line also marks the SetTimeout method.
Next, we create a collector object, and feed its dependencies to it, after which we make sure that the collector called GetTimeout on one dependency and passed the value to another dependency. It was better to create a separate test method for testing the constructor, but I left it as it is, for no reason, spontaneously. Next, we send a message, and make sure that it was forwarded to the junction.
Here you can already see that the test code is complete, and does not force you to watch additional files with manually declared mocks during a review or redesign, but it reduces potential time costs, which in itself is a good enough reason to use Moq.
Stress Testing
I expected to see the superiority of my approach over NLog, I was ready to work on micro-optimizations, save a penny in order to meet expectations even a little better. But the results of the first tests struck me, having beaten off such a desire.
For the load test, I created a console application in which I took a logger and sent messages to it in a cycle.
var log = SharpLogger.LogAccess.GetLogger("flooder " + tid); foreach (var x in Enumerable.Range(0, messageCount)) { log.Info("Message", x); if (x % 1000 == 0) Thread.Sleep(0); } And the exact same method for nlog.
var log = NLog.LogManager.GetLogger("flooder " + tid); foreach (var x in Enumerable.Range(0, messageCount)) { log.Info("Message"); if (x % 1000 == 0) Thread.Sleep(0); } The method shows a tid, which means that execution occurs in several threads.
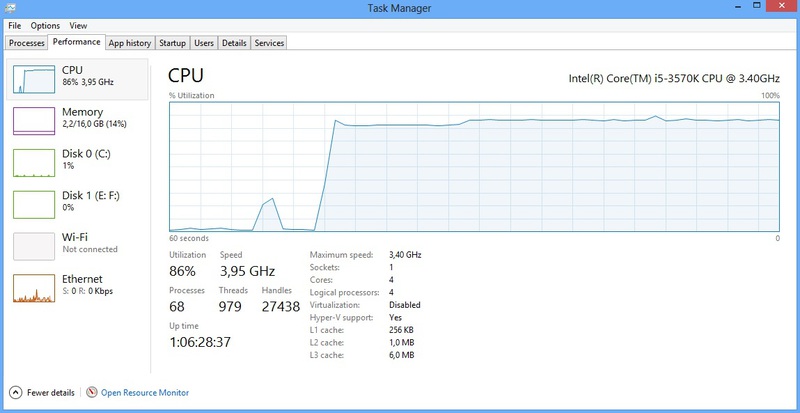
Of course, I did a lot of tests, but I think it’s quite enough to give one test. Three streams send 200 thousand messages each. In the screenshot of Task Manager CPU load. The first small burst is my logger, then, after 5 seconds of delay, the operation of NLog. The resulting log files are identical, except for mismatched time.
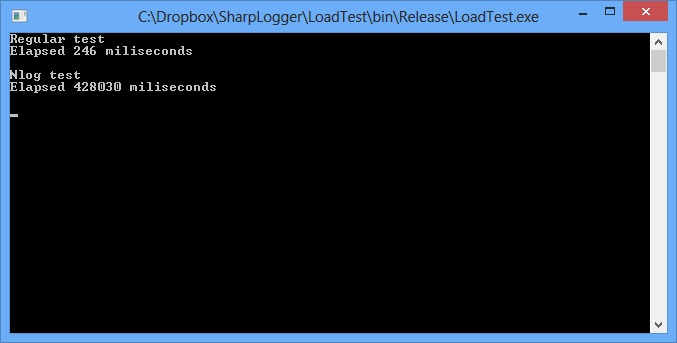
I will also give the result of measurement by the test program itself, which speaks for itself.
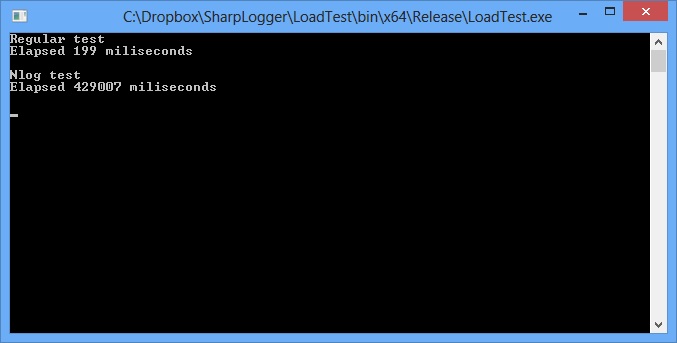
When recompiling under x64, the result almost does not change.
Of course, I need to mention one nuance - because I use an additional stream that does not use Nlog, and I measure only the processor time that the sending operation took away from the calling threads, and I bypass the processor load that this thread creates. I also decided to look at this by running a test already from 40 threads that send half a million messages.

The result that the program produced is 7.15 seconds., But the graph shows that the logger stream worked for about 25 seconds to write to the file. This is undoubtedly a drawback, since the program can be completed before the logger, before full recording, which is excluded in the case of NLog and, in addition, the thread will have one processor completely even when the load in the main program is already over. The comforting point here is that NLog with such a number of logs will kill the processor for six hours according to approximate estimates, which gives grounds to reconcile with the indicated disadvantage.
And one more thing that needs to be mentioned is the effect of a non-blocking queue on performance relative to a regular blocking queue.
I did two tests, in the first 3 threads sent 15 million messages, the non-blocking queue reduced the measured time from 22.2 seconds to 17.8. With an increase in the number of threads to 30, and while maintaining the total number of messages, that is, 1.5 million per flow, the blocking queue slowed down the test to 23.7 seconds, while the non-blocking, on the contrary, slightly accelerated to 17.4, increasing the gap.
As you can see from the screenshots, the testing was done on 4x 4GHz nuclear, on windows 8.
The project can be downloaded from the github via the link https://github.com/repinvv/SharpLogger
Errors, typos and other comments - Wellcome.
Source: https://habr.com/ru/post/151641/
All Articles