Code Reliability and NullReferenceException
Firstly, what is meant by reliability in relation to programs? The concept of reliability was originally purely engineering. According to the definition from the Wiki, reliability is the property of an object to maintain a healthy state for some time. By “object” is here meant a certain physical system. And, as a rule, the more complex this system is, the more elements it enters, the less reliable it is, because the probability of a system’s failure is equal to the product of the failure probabilities of its parts (rough approximation, if we do not take into account duplication and different degrees of criticality of components) . The same is quite applicable to software systems - the more complex the program, the greater the number of errors in it. However, there is one fundamental difference between physical systems and software systems.
Take some kind of aircraft assembly, for example, the mechanism that turns the ailerons. It consists of a set of mechanical and electronic components that, working in concert, produce the desired action - they turn the aileron. Theoretically, we can calculate the reliability of this mechanism, for this we only need to know the reliability of its individual elements. Suppose one of these elements is a conventional screw, which, nevertheless, is crucial for the mechanism to work - if it breaks, the aileron will stop turning. How to determine the reliability of this screw? You can take a batch of such screws and conduct a series of tests for strength, thus determining a certain statistical value and assuming that this particular screw does not get very far out of this series. The assumption is, in general, unfounded and very dangerous. You can go the other way: take this screw, scan its atom by atom and build a quantum mechanical model that will take into account all microscopic defects and irregularities. Then, having calculated this model on a huge supercomputer, see how this screw will behave under different loads and will not break. The idea is exciting, but absolutely meaningless. Because we will not be able to predict what loads will act on this screw, since they depend on many factors, such as wind gusts, actions of the pilot, mechanical reaction of other parts of the aircraft. And in order to simulate all these factors, we will have to drive the entire plane with the pilot into the matrix, as well as the entire atmosphere of the Earth, plus take into account magnetic perturbations in the sun and gravitational waves from a supernova explosion in a nearby galaxy.
It is good that we are programmers, not engineers, and we deal with much more predictable objects. Not only is the atomic scanner not yet invented, we still don't know all the laws of physics. I think the difference between software systems and physical ones is outlined. Software systems consist of elements whose behavior can be predicted theoretically. Plus, their behavior does not depend on time - programs do not wear out.
Consider this example. In the .Net Framework, the String object has a Substring method:
')
This method returns a substring in a string, starting at the startIndex position and ending at the end of the string. Suppose we needed a method that returns the last three characters of the file name, and we wrote the following code:
Is this code good? Yes, he does what is required - returns the last three characters. And it works fine, but until the file name is less than three characters long. And we will receive an exception of type ArgumentOutOfRangeException at the most inappropriate moment.
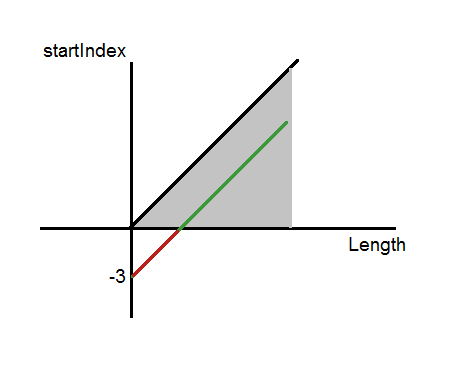
What happened? What happened is that the Substring method has a domain and was broken. The startIndex argument can take values in the range [0, Length ] where Length is the length of the string. If you take a two-dimensional coordinate system, where the X axis is the length of the string, and the Y axis is the initial index, we get a triangular area in the right upper quarter that goes to infinity. Now we draw a set of values that can be passed to the Substring method in our implementation. This set is described by the equation startIndex = Length - 3. The usual line equation. With Length = 0 startIndex = -3, with Length = 3 startIndex = 0. Now the program clearly shows the reason for the failure in the program: the range of possible input values is outside the range of the method definition.
We found a mistake. How to fix it? It depends on what we want to receive, that is, on the requirements for this Extension method. You can insert a condition before calling Substring
Or rewrite the method as follows:
The behavior of these implementations is different, but in both cases all possible values of the arguments lie within the domain of the Substring method.
I think you noticed that there is one more bug in our Extension method. As an argument, the name can be passed to null, which will cause a familiar NullReferenceException to a pain. We consider this type of bugs in the following example.
The example is taken from real practice. There is a very simple method that converts an object of type Entity into an object of type DTO and serves to isolate the level of business logic from the level of data access:
If we consider the argument e as a pointer, then it can take only two values: null and an object reference. And of these two values, only the latter is in the domain of the Translate method. And if somewhere in the program, this method will be called with the argument null, it will fall.
However, now, unlike the Substring method, its implementation is available to us. So why not expand this domain by adding the following line to the beginning of the method:
The scope of the method now includes both possible values of the argument e , and it can be guaranteed that this method will work under any circumstances.
However, an experienced programmer who stuffed cones on broken pointers might argue that such an implementation simply masks other errors, perhaps more serious ones. In fact, for what reason could the input of the Translate method be null? Maybe we should throw an exception instead of silently passing this null further along the call chain? The objection is quite reasonable, so it is worth considering this method in a more general context.
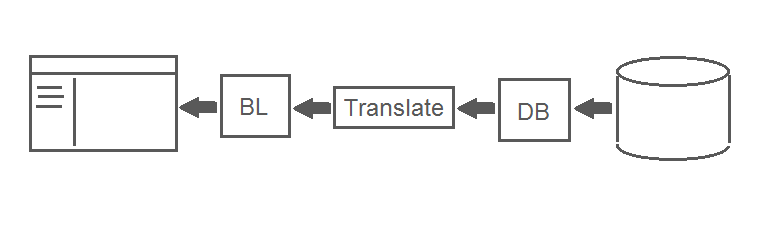
Suppose that this method is part of a program that retrieves a list of objects from the database and maps it to the UI. In this case, a list of short names is displayed on the left, in which the user can select an element, as a result of which detailed information about the object will be displayed on the right. And just when getting detailed information, the Translate method is used: the object identifier is passed to the procedure in the DB block, this procedure executes the query, packages the result into the object and transmits it to our Translate method.
Here the second question arises: what should the procedure do in the DB block if the object with the passed identifier does not exist in the database? Should it return null? No, and that's why.
Since the list of short names and detailed information are logically related and should be formed on the basis of a consistent data set, it is obvious that the absence of an object with the requested identifier indicates either data inconsistency (if short names and detailed information are stored in different tables that are poorly interconnected by foreign keys ), or an error somewhere in the code that generates a list of short names. Another reason may be the following: after the list of short names was displayed, some other user of the system deleted one of the objects from the database, after which the first user selected this object to view detailed information. Here the reason is the absence of a blocking mechanism, but in all these cases the absence of the requested object indicates the presence of a higher level error. Therefore, the most reasonable action for a procedure in a DB block is to throw an exception into which you can transfer maximum information: what request was made, which database, etc. All this information is very important for further debugging of the application and is only available at the data access level.
Ok, with the level of access to data sorted out. However, the question of what the Translate procedure should do when getting null remains open. If the data access level is implemented correctly, then there will never come null, and there is no need to check the argument and throw an exception. That is, in this context, we are confident that the argument values will lie within the scope of the method. Consequently, the method can generally be left in its original form - without in any way checking the argument and not throwing an exception. But. There is always a wider context.
First, more or less complex software systems are always developed not by separate people, but by teams whose composition may change over time — someone leaves, someone comes. Secondly, the functionality of the system itself is continuously developing. This leads to the fact that the same methods begin to be used in completely different contexts in which the semantic load of variables changes.
What does the arrival of null on the Translate input in the context described above indicate? Obviously, somewhere that something broke. That is, the null value in this context makes sense "somewhere something broke." However, another context is possible.
Suppose now we needed to make a user interface for searching an object in the database by its unique code designation. Written SQL query, which returns zero or one record. A new method is written in a DB block, which, respectively, returns either a found object or null. In this case, null is a completely logical result, since the object code entered by the user may well be incorrect, in which case the user-friendly message “Object not found” is displayed on the UI. That is, in this context, the value of null carries a completely different meaning. And what happens if we try to use in this context the ready Translate method? A rhetorical question ...
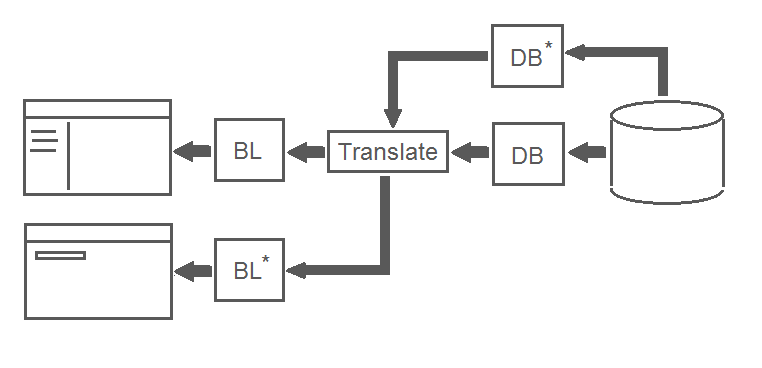
Thus, if we want the Translate method to work reliably in both contexts, we must make its definition domain as wide as possible by adding the line
at the beginning of the method. In fact, in the first context, the data access level cannot return null, and in the second, null is a completely valid value.
In the general case, when it is not known in what other contexts a method can be used, one should make the domain of its definition as wide as possible.
Theoretically, one could come up with another context in which the Translate method would have to throw an exception. For example, if the data access level is in the third-party library and is implemented crookedly, it returns null when it should throw an exception. In this case, the Translate method simply cannot be used in three contexts at once, since their requirements for this method contradict each other: the second context needs null to be passed to the output, the third one that an exception is thrown, and the first all the same. Therefore, in this situation, you will have to write two different implementations of the method (or, more beautifully, make the method virtual and overload).
To be continued.
Take some kind of aircraft assembly, for example, the mechanism that turns the ailerons. It consists of a set of mechanical and electronic components that, working in concert, produce the desired action - they turn the aileron. Theoretically, we can calculate the reliability of this mechanism, for this we only need to know the reliability of its individual elements. Suppose one of these elements is a conventional screw, which, nevertheless, is crucial for the mechanism to work - if it breaks, the aileron will stop turning. How to determine the reliability of this screw? You can take a batch of such screws and conduct a series of tests for strength, thus determining a certain statistical value and assuming that this particular screw does not get very far out of this series. The assumption is, in general, unfounded and very dangerous. You can go the other way: take this screw, scan its atom by atom and build a quantum mechanical model that will take into account all microscopic defects and irregularities. Then, having calculated this model on a huge supercomputer, see how this screw will behave under different loads and will not break. The idea is exciting, but absolutely meaningless. Because we will not be able to predict what loads will act on this screw, since they depend on many factors, such as wind gusts, actions of the pilot, mechanical reaction of other parts of the aircraft. And in order to simulate all these factors, we will have to drive the entire plane with the pilot into the matrix, as well as the entire atmosphere of the Earth, plus take into account magnetic perturbations in the sun and gravitational waves from a supernova explosion in a nearby galaxy.
It is good that we are programmers, not engineers, and we deal with much more predictable objects. Not only is the atomic scanner not yet invented, we still don't know all the laws of physics. I think the difference between software systems and physical ones is outlined. Software systems consist of elements whose behavior can be predicted theoretically. Plus, their behavior does not depend on time - programs do not wear out.
Consider this example. In the .Net Framework, the String object has a Substring method:
')
public string Substring(int startIndex) This method returns a substring in a string, starting at the startIndex position and ending at the end of the string. Suppose we needed a method that returns the last three characters of the file name, and we wrote the following code:
static string Extension(string name) { return name.Substring(name.Length-3); } Is this code good? Yes, he does what is required - returns the last three characters. And it works fine, but until the file name is less than three characters long. And we will receive an exception of type ArgumentOutOfRangeException at the most inappropriate moment.
What happened? What happened is that the Substring method has a domain and was broken. The startIndex argument can take values in the range [0, Length ] where Length is the length of the string. If you take a two-dimensional coordinate system, where the X axis is the length of the string, and the Y axis is the initial index, we get a triangular area in the right upper quarter that goes to infinity. Now we draw a set of values that can be passed to the Substring method in our implementation. This set is described by the equation startIndex = Length - 3. The usual line equation. With Length = 0 startIndex = -3, with Length = 3 startIndex = 0. Now the program clearly shows the reason for the failure in the program: the range of possible input values is outside the range of the method definition.
We found a mistake. How to fix it? It depends on what we want to receive, that is, on the requirements for this Extension method. You can insert a condition before calling Substring
If(name.Length < 3) return String.Empty; Or rewrite the method as follows:
static string Extension(string name) { int index = name.Length - 3; if (index < 0) index = 0; return name.Substring(index); } The behavior of these implementations is different, but in both cases all possible values of the arguments lie within the domain of the Substring method.
I think you noticed that there is one more bug in our Extension method. As an argument, the name can be passed to null, which will cause a familiar NullReferenceException to a pain. We consider this type of bugs in the following example.
The example is taken from real practice. There is a very simple method that converts an object of type Entity into an object of type DTO and serves to isolate the level of business logic from the level of data access:
static ProductDto Translate(ProductEntity e) { return new ProductDto() { Name = e.Name, Code = e.Code, Description = e.Description }; } If we consider the argument e as a pointer, then it can take only two values: null and an object reference. And of these two values, only the latter is in the domain of the Translate method. And if somewhere in the program, this method will be called with the argument null, it will fall.
However, now, unlike the Substring method, its implementation is available to us. So why not expand this domain by adding the following line to the beginning of the method:
if (e == null) return null; The scope of the method now includes both possible values of the argument e , and it can be guaranteed that this method will work under any circumstances.
However, an experienced programmer who stuffed cones on broken pointers might argue that such an implementation simply masks other errors, perhaps more serious ones. In fact, for what reason could the input of the Translate method be null? Maybe we should throw an exception instead of silently passing this null further along the call chain? The objection is quite reasonable, so it is worth considering this method in a more general context.
Suppose that this method is part of a program that retrieves a list of objects from the database and maps it to the UI. In this case, a list of short names is displayed on the left, in which the user can select an element, as a result of which detailed information about the object will be displayed on the right. And just when getting detailed information, the Translate method is used: the object identifier is passed to the procedure in the DB block, this procedure executes the query, packages the result into the object and transmits it to our Translate method.
Here the second question arises: what should the procedure do in the DB block if the object with the passed identifier does not exist in the database? Should it return null? No, and that's why.
Since the list of short names and detailed information are logically related and should be formed on the basis of a consistent data set, it is obvious that the absence of an object with the requested identifier indicates either data inconsistency (if short names and detailed information are stored in different tables that are poorly interconnected by foreign keys ), or an error somewhere in the code that generates a list of short names. Another reason may be the following: after the list of short names was displayed, some other user of the system deleted one of the objects from the database, after which the first user selected this object to view detailed information. Here the reason is the absence of a blocking mechanism, but in all these cases the absence of the requested object indicates the presence of a higher level error. Therefore, the most reasonable action for a procedure in a DB block is to throw an exception into which you can transfer maximum information: what request was made, which database, etc. All this information is very important for further debugging of the application and is only available at the data access level.
Ok, with the level of access to data sorted out. However, the question of what the Translate procedure should do when getting null remains open. If the data access level is implemented correctly, then there will never come null, and there is no need to check the argument and throw an exception. That is, in this context, we are confident that the argument values will lie within the scope of the method. Consequently, the method can generally be left in its original form - without in any way checking the argument and not throwing an exception. But. There is always a wider context.
First, more or less complex software systems are always developed not by separate people, but by teams whose composition may change over time — someone leaves, someone comes. Secondly, the functionality of the system itself is continuously developing. This leads to the fact that the same methods begin to be used in completely different contexts in which the semantic load of variables changes.
What does the arrival of null on the Translate input in the context described above indicate? Obviously, somewhere that something broke. That is, the null value in this context makes sense "somewhere something broke." However, another context is possible.
Suppose now we needed to make a user interface for searching an object in the database by its unique code designation. Written SQL query, which returns zero or one record. A new method is written in a DB block, which, respectively, returns either a found object or null. In this case, null is a completely logical result, since the object code entered by the user may well be incorrect, in which case the user-friendly message “Object not found” is displayed on the UI. That is, in this context, the value of null carries a completely different meaning. And what happens if we try to use in this context the ready Translate method? A rhetorical question ...
Thus, if we want the Translate method to work reliably in both contexts, we must make its definition domain as wide as possible by adding the line
if (e == null) return null; at the beginning of the method. In fact, in the first context, the data access level cannot return null, and in the second, null is a completely valid value.
In the general case, when it is not known in what other contexts a method can be used, one should make the domain of its definition as wide as possible.
Theoretically, one could come up with another context in which the Translate method would have to throw an exception. For example, if the data access level is in the third-party library and is implemented crookedly, it returns null when it should throw an exception. In this case, the Translate method simply cannot be used in three contexts at once, since their requirements for this method contradict each other: the second context needs null to be passed to the output, the third one that an exception is thrown, and the first all the same. Therefore, in this situation, you will have to write two different implementations of the method (or, more beautifully, make the method virtual and overload).
To be continued.
Source: https://habr.com/ru/post/151607/
All Articles