Elastic MapReduce. Distributed implementation
It so happened that the first film I watched with the mention of the word "supercomputer" was Terminator. But, oddly enough, my (then) unformed psyche did not consider SkyNet a world evil, writing off the aggressive behavior of the world's first AI to insufficient coverage of the unit with tests.
At that time I had a ZX Spectrum (whose 128 Kb was clearly not enough to launch something similar to AI) and a lot of (I think 10 years) free time. Thanks to the latter fact, I happily waited for the era of virtualization. It was possible to remove at least 10K VPS, establish a communication channel between them and begin to create AI. But I wanted to do programming, not administration / configuration of the grid system, and I reasonably began to wait for computing resources to be provided as a service.
There was no end to my joy when cloud services appeared. But the joy did not last long: it became clear that so far direct communications between separate computing instances arefiction code that you need to write yourself (that is, with high probability it will not work). Having reared for a couple of years about this, I (we all) waited for Hadoop, first the “ on-premises ”, and then the elastic “ on-demand ”. But even there, as it turned out, not everything is so elastic smoothly. as we would like. But this is a completely different story ... about which, having slightly changed the comic tone of the narration, I am going to tell you.
')
The symbiosis of cloud technologies and the Apache Hadoop platform for several years now has been viewed as a source of interesting solutions related to Big Data analysis.
And the main point, why “symbiosis”, and not “pure” Hadoop, is, of course, a decrease in the level of input for developers of MPP applications (and not only) both in terms of qualifications (administrator) and initial financial investments in hardware the part on which the application will be executed.
The second point is that cloud providers will be able to circumvent some of the limitations of Hadoop * imposed by the master / slave architecture (the master is always a single point of failure and something needs to be done with this) and, perhaps (at Microsoft, due to the parallel developing project Dryad , there was particular hope), even a strong coupling of data storage ( HDFS ) and components of distributed computing ( Hadoop MapReduce ).
The hopes related to the first item - reducing the cost of ownership of the Hadoop cluster - came true more than: the largest triple cloud providers, with varying degrees of proximity to the release-mode, began to provide " Hadoop cluster as a Service " (my terminology and conditional) for prices , quite "lifting" for startups and / or research groups.
Hopes, connected with circumvention of the limitations of the Hadoop platform , did not come true at all.
Amazon Web Services, like the IaaS platform, has never sought to provide services as a service (although there is an exception - Amazon S3, Amazon DynamoDB). And back in 2009, Amazon provided developers with Amazon Elastic MapReduce as an infrastructure, not as a service.
Following Amazon in mid-2010, Google announced an experimental version of the App Engine API MapReduce , as part of its Google App Engine cloud platform.
The App Engine MapReduce API provides developers with “Hadoop MapReduce” -like interfaces to their services that are already working on the map / reduce paradigm. But this did not remove the limitations of the strong connectivity of the data warehouse and the components of the calculations. Moreover, Google itself added restrictions there — the possibilities of redefining only the map-phases **, and the GAE platform itself, with its characteristic quotas, imposed (as I suspect) a couple more restrictions on the App Engine MapReduce API.
In 2011, the turn came to Microsoft. In October 2011, Microsoft announced the opening of the Hadoop on Azure service . Currently it is in the CTP version. I did not manage to try this service due to the lack of an invitation (and the presence of laziness). But, in the absence of articles about the overcome limitations of Hadoop, it is clear that the “problems” of the Hadoop platform in this case were left to be solved by Hadoop itself.
The above limitations of solutions based on "cloud platforms + Hadoop" allow us to understand the range of problems solved by the project Cloud MapReduce , which will be discussed in the rest of the article.
Cloud MapReduce (CMR) is an open source project that implements the map / reduce software paradigm based on (on top) Amazon Web Services cloud services.
CMR is based on the concept of a cloud operating system. If we draw an analogy with traditional OS, then in cloud OS:
Having laid the principles of cloud OS in the Cloud MapReduce architecture, the developers got me an impressive result. In their blog, they cite the following facts from comparing their platform with the Hadoop platform:
In addition, Cloud MapReduce, unlike Apache Hadoop, is not designed on the basis of a master / slave architecture. In addition to the obvious advantages of peer-like architectures (the absence of single point of failure), the developers of CMR lead to the advantages of their implementation of MapReduce, which is simpler than configuration in Hadoop, configuration, redundancy, recovery after failures.
The merits of CMR also imply incremental scalability: when adding new computational instances to the cluster, they are "hot" connected to the execution of the map / reduce-task. Also, CMR does not require (recommends) to have a homogeneous cluster (that is, from machines with the same computing power). In a cluster of heterogeneous machines, the fastest machine will perform a larger number of tasks than a slower machine.
I’ll add that incremental scalability really lacked the Hadoop platform. But the absence of a requirement (recommendation) for cluster homogeneity is hardly relevant for cloud environments.
Cloud MapReduce architecture is divided into the following logical layers:
The relationships of these layers, the information flows and the services by which it is represented in AWS are shown in the figure below.
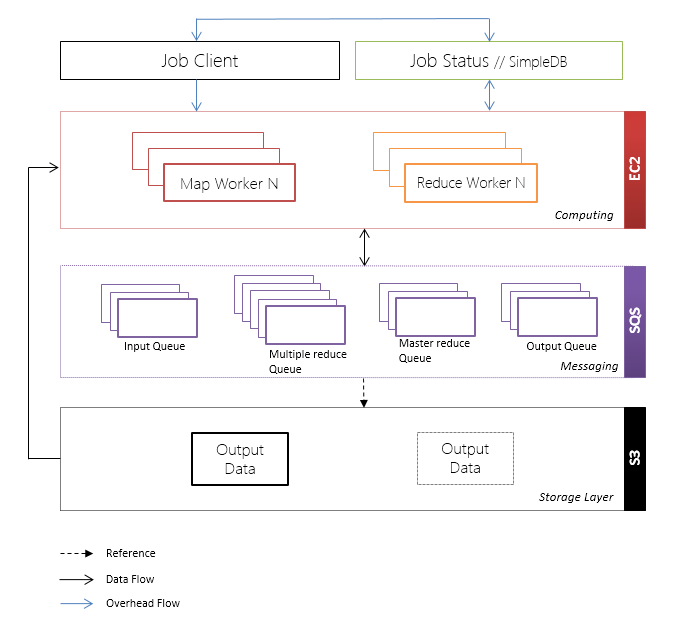
Below we analyze in more detail the function of each of the above layers.
The interaction between the Map Workers and Reduce Workers nodes is based on queues. Queues in Cloud MapReduce are represented by Amazon SQS.
The CMR has the following types of queues:
Messages in Amazon SQS / Azure Queue queues have an “invisibility timeout” mechanism. The logic of the mechanism is as follows: the message is taken from the queue, after which the message becomes invisible in the queue for a while. Upon successful processing of the message, the last of the queue is deleted, otherwise, after the invisibility timeout expires, the message reappears in the queue.
Thanks to the “invisibility timeout” mechanism provided by the queue services, a very simple support for the processing of Map and Reduce Worker failures is realized and the overall fault tolerance of the cluster is increased.
The data store stores the application's input data and is represented by the Amazon S3 service.
Amazon S3 also introduces a cleaner abstraction of the storage layer, because access is provided to data as resources (which are typical of REST services), and not as files (which is typical of file systems). It should be noted that the approach of storing data in the cloud storage has a downside - less manageability.
Amazon S3 stores data analyzed at the map stage. The Input Queue contains a pair of <k, v>, where k, in general, is the identifier of the map job, and v is the link file in S3 and optionally a pointer to the part inside the file.
This approach removes the inconvenience / problem (for whom how) with copying data from Amazon S3 to HDFS at the first stage of launching a MapReduce task in Amazon Elastic MapReduce.
The developer also mentioned that the output is also possible to save directly to Amazon S3:
It follows from the documentation that all the results of the reduce stage are stored in the Reduce Queue as pairs <k ', v'>.
User-defined map and reduce tasks are executed on compute nodes. Compute Nodes are represented by EC2 instances and are divided into 2 types: Map Workers and Reduce Workers . Map Workers executes map functions on the Map Workers, and reduce functions on the Reduce Workers.
On the same EC2 Instance, the Map Worker and the Reduce Worker can consistently play the role.
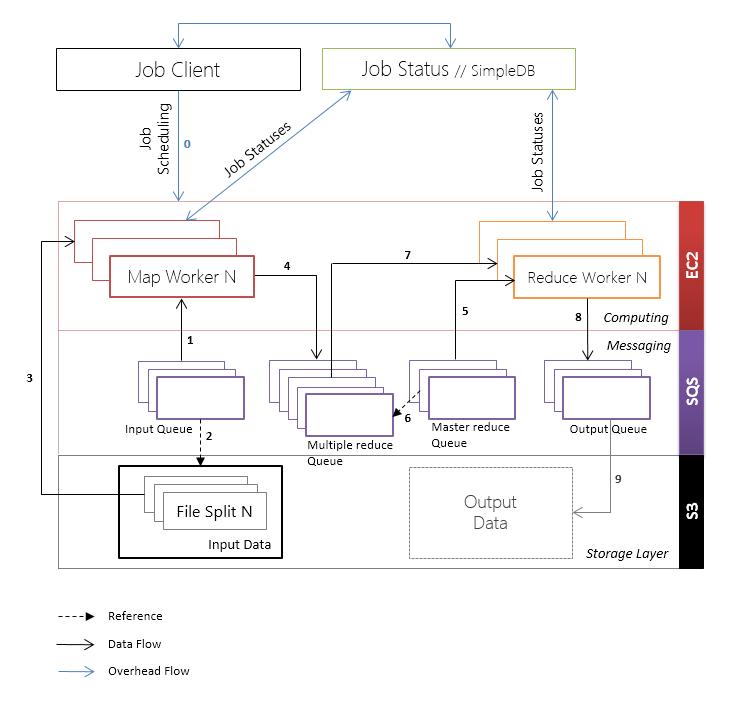
The workflows of map and reduce operations are listed below.
Mapper workflow:
Reducer workflow:
The client ( Job Client ) is a software client that manages the execution of map / reduce tasks.
The client from the CMR documentation is least clear. But, considering what we know about the Map workflow and reduce Workers and the principles of building such systems, let me make a couple of near-scientific assumptions about the Job Client workflow.
The work client job flow is divided into the following stages:
The operations of saving / updating the status of execution of map- / reduce-tasks are implemented on the basis of non-relational databases. AWS nonrelational databases are represented by Amazon SimpleDB (since 2007) and Amazon DynamoDB (since 2012).
Since the CMR architecture assumes that all nodes in a computing cluster are equivalent, then the center of node coordination is Amazon SimpleDB, which provides distributed non-relational data storage.
I do not urge to switch to Cloud MapReduce neither today nor tomorrow ***, just as I don’t intend, when I read a book on Haskell, to become a programmer on this undoubtedly excellent PL.
Cloud MapReduce has flaws that make business risks from its use essential (small team, rare updates, lack of an ecosystem like that of Hadoop), and prospects are hazy. But the ideas drawn from thefunctional programming of the Cloud MapReduce project architecture make it even more distributed to look at the already established Hadoop-oriented presentation among IT professionals in Data Intensive Computing.
* I now do not take into account the alpha-version of Apache Hadoop 2.0, which is “deprived” (more precisely, to the release-version “is going to be deprived”) of the described architectural constraints.
** I remember (or maybe I dreamed?) That at the Google I / O 2011 conference, besides mitigating the existing limits of the App Engine platform, Mike Aizatsky (I won’t even distort it) said that Google engineers are working to provide redefinition and other steps of the map algorithm / reduce in App Engine MapReduce API.
*** Just as I do not call for the opposite.
At that time I had a ZX Spectrum (whose 128 Kb was clearly not enough to launch something similar to AI) and a lot of (I think 10 years) free time. Thanks to the latter fact, I happily waited for the era of virtualization. It was possible to remove at least 10K VPS, establish a communication channel between them and begin to create AI. But I wanted to do programming, not administration / configuration of the grid system, and I reasonably began to wait for computing resources to be provided as a service.
There was no end to my joy when cloud services appeared. But the joy did not last long: it became clear that so far direct communications between separate computing instances are
')
Distributed introduction to Hadoop elastic problems
The symbiosis of cloud technologies and the Apache Hadoop platform for several years now has been viewed as a source of interesting solutions related to Big Data analysis.
And the main point, why “symbiosis”, and not “pure” Hadoop, is, of course, a decrease in the level of input for developers of MPP applications (and not only) both in terms of qualifications (administrator) and initial financial investments in hardware the part on which the application will be executed.
The second point is that cloud providers will be able to circumvent some of the limitations of Hadoop * imposed by the master / slave architecture (the master is always a single point of failure and something needs to be done with this) and, perhaps (at Microsoft, due to the parallel developing project Dryad , there was particular hope), even a strong coupling of data storage ( HDFS ) and components of distributed computing ( Hadoop MapReduce ).
The hopes related to the first item - reducing the cost of ownership of the Hadoop cluster - came true more than: the largest triple cloud providers, with varying degrees of proximity to the release-mode, began to provide " Hadoop cluster as a Service " (my terminology and conditional) for prices , quite "lifting" for startups and / or research groups.
Hopes, connected with circumvention of the limitations of the Hadoop platform , did not come true at all.
Amazon Web Services, like the IaaS platform, has never sought to provide services as a service (although there is an exception - Amazon S3, Amazon DynamoDB). And back in 2009, Amazon provided developers with Amazon Elastic MapReduce as an infrastructure, not as a service.
Following Amazon in mid-2010, Google announced an experimental version of the App Engine API MapReduce , as part of its Google App Engine cloud platform.
The App Engine MapReduce API provides developers with “Hadoop MapReduce” -like interfaces to their services that are already working on the map / reduce paradigm. But this did not remove the limitations of the strong connectivity of the data warehouse and the components of the calculations. Moreover, Google itself added restrictions there — the possibilities of redefining only the map-phases **, and the GAE platform itself, with its characteristic quotas, imposed (as I suspect) a couple more restrictions on the App Engine MapReduce API.
In 2011, the turn came to Microsoft. In October 2011, Microsoft announced the opening of the Hadoop on Azure service . Currently it is in the CTP version. I did not manage to try this service due to the lack of an invitation (and the presence of laziness). But, in the absence of articles about the overcome limitations of Hadoop, it is clear that the “problems” of the Hadoop platform in this case were left to be solved by Hadoop itself.
The above limitations of solutions based on "cloud platforms + Hadoop" allow us to understand the range of problems solved by the project Cloud MapReduce , which will be discussed in the rest of the article.
1. Cloud MapReduce. Basic concepts
Cloud MapReduce (CMR) is an open source project that implements the map / reduce software paradigm based on (on top) Amazon Web Services cloud services.
CMR is based on the concept of a cloud operating system. If we draw an analogy with traditional OS, then in cloud OS:
- computing resources are not represented by a CPU, but by Amazon EC2 / Windows Azure Workers / Google Compute Engine instances;
- data storage is not represented by a hard disk (SD, flash drives, etc.), but by Amazon S3 / Windows Azure Blob / Google Cloud Storage services;
- The state store (which is not lost after the OS reload) is not represented by the registry (or local structure with a similar function), but by Amazon SimpleDB / Windows Azure Table / Google BigQuery services;
- The interprocess communication mechanism is implemented using Amazon SQS / Windows Azure Queue / Google App Engine Task Queue API services.
Having laid the principles of cloud OS in the Cloud MapReduce architecture, the developers got me an impressive result. In their blog, they cite the following facts from comparing their platform with the Hadoop platform:
- no single point of failure;
- no need to copy data from storage services (such as Amazon S3) to HDFS before running the MapReduce job;
- acceleration in some cases more than 60 times;
- the project takes only 3000 lines of Java code, while Hadoop is “located” as much as 280K of code.
In addition, Cloud MapReduce, unlike Apache Hadoop, is not designed on the basis of a master / slave architecture. In addition to the obvious advantages of peer-like architectures (the absence of single point of failure), the developers of CMR lead to the advantages of their implementation of MapReduce, which is simpler than configuration in Hadoop, configuration, redundancy, recovery after failures.
The merits of CMR also imply incremental scalability: when adding new computational instances to the cluster, they are "hot" connected to the execution of the map / reduce-task. Also, CMR does not require (recommends) to have a homogeneous cluster (that is, from machines with the same computing power). In a cluster of heterogeneous machines, the fastest machine will perform a larger number of tasks than a slower machine.
I’ll add that incremental scalability really lacked the Hadoop platform. But the absence of a requirement (recommendation) for cluster homogeneity is hardly relevant for cloud environments.
2. Cloud MapReduce. Architecture
Cloud MapReduce architecture is divided into the following logical layers:
- Storage Layer
- layer processing and computing ( Computing Layer );
- Messaging layer.
The relationships of these layers, the information flows and the services by which it is represented in AWS are shown in the figure below.
Below we analyze in more detail the function of each of the above layers.
2.1. Interaction between nodes
The interaction between the Map Workers and Reduce Workers nodes is based on queues. Queues in Cloud MapReduce are represented by Amazon SQS.
The CMR has the following types of queues:
- Input / Map Queue - a queue of map tasks;
- Multiple Reduce Queue - queues of intermediate results of map functions;
- Master Reduce Queue - queue of reduce-tasks;
- Output Queue - the output queue.
Messages in Amazon SQS / Azure Queue queues have an “invisibility timeout” mechanism. The logic of the mechanism is as follows: the message is taken from the queue, after which the message becomes invisible in the queue for a while. Upon successful processing of the message, the last of the queue is deleted, otherwise, after the invisibility timeout expires, the message reappears in the queue.
Thanks to the “invisibility timeout” mechanism provided by the queue services, a very simple support for the processing of Map and Reduce Worker failures is realized and the overall fault tolerance of the cluster is increased.
2.2. Data storage
The data store stores the application's input data and is represented by the Amazon S3 service.
Amazon S3 also introduces a cleaner abstraction of the storage layer, because access is provided to data as resources (which are typical of REST services), and not as files (which is typical of file systems). It should be noted that the approach of storing data in the cloud storage has a downside - less manageability.
Amazon S3 stores data analyzed at the map stage. The Input Queue contains a pair of <k, v>, where k, in general, is the identifier of the map job, and v is the link file in S3 and optionally a pointer to the part inside the file.
This approach removes the inconvenience / problem (for whom how) with copying data from Amazon S3 to HDFS at the first stage of launching a MapReduce task in Amazon Elastic MapReduce.
The developer also mentioned that the output is also possible to save directly to Amazon S3:
We store our input and output data in S3
It follows from the documentation that all the results of the reduce stage are stored in the Reduce Queue as pairs <k ', v'>.
2.3. Compute nodes
User-defined map and reduce tasks are executed on compute nodes. Compute Nodes are represented by EC2 instances and are divided into 2 types: Map Workers and Reduce Workers . Map Workers executes map functions on the Map Workers, and reduce functions on the Reduce Workers.
On the same EC2 Instance, the Map Worker and the Reduce Worker can consistently play the role.
The workflows of map and reduce operations are listed below.
Mapper workflow:
- Getting data queuing from map queue for map tasks;
- Extract data from Amazon S3;
- Execution of a user-defined map function;
- Adding the result of executing <k ', v'> to some queue, determined on the basis of the hash k '(if it is not overridden), from among multiple queues Multiple Reduce Queues;
- Remove map job from Map Queue.
Reducer workflow:
- Receives from the Master Reduce Queue a reference to the Reduce Queue to which the convolution function should be applied;
- Extracts <k ', v'> - pairs from the corresponding queue of multiple queues Multiple Reduce Queues;
- Performs a user-defined reduce-function and adds output <k '', v ''> pairs to the Output Queue;
- Removes a reduce job from the Master Reduce Queue.
2.4. Customer
The client ( Job Client ) is a software client that manages the execution of map / reduce tasks.
The client from the CMR documentation is least clear. But, considering what we know about the Map workflow and reduce Workers and the principles of building such systems, let me make a couple of near-scientific assumptions about the Job Client workflow.
The work client job flow is divided into the following stages:
- Saving input data in Amazon S3;
- Creating a map task for each data split and adding the created task to the Map Queue;
- Creating multiple queues Multiple Reduce Queues;
- Creating the Master Reduce Queue and adding the created reduce queue for each Partition Queue;
- Creating an Output Queue;
- Creating a Job Request and adding the created request to SimpleDB;
- Run EC2 instances for Map Workers and Reduce Workers;
- Poll Map Workers and Reduce Workers to get job execution status;
- When all tasks are completed, load the results from the Output Queue.
2.5. Auxiliary operations
The operations of saving / updating the status of execution of map- / reduce-tasks are implemented on the basis of non-relational databases. AWS nonrelational databases are represented by Amazon SimpleDB (since 2007) and Amazon DynamoDB (since 2012).
Since the CMR architecture assumes that all nodes in a computing cluster are equivalent, then the center of node coordination is Amazon SimpleDB, which provides distributed non-relational data storage.
Conclusion and footnotes
I do not urge to switch to Cloud MapReduce neither today nor tomorrow ***, just as I don’t intend, when I read a book on Haskell, to become a programmer on this undoubtedly excellent PL.
Cloud MapReduce has flaws that make business risks from its use essential (small team, rare updates, lack of an ecosystem like that of Hadoop), and prospects are hazy. But the ideas drawn from the
* I now do not take into account the alpha-version of Apache Hadoop 2.0, which is “deprived” (more precisely, to the release-version “is going to be deprived”) of the described architectural constraints.
** I remember (or maybe I dreamed?) That at the Google I / O 2011 conference, besides mitigating the existing limits of the App Engine platform, Mike Aizatsky (I won’t even distort it) said that Google engineers are working to provide redefinition and other steps of the map algorithm / reduce in App Engine MapReduce API.
*** Just as I do not call for the opposite.
Source: https://habr.com/ru/post/151419/
All Articles