IMAP: transition difficulties
What rake buried in IMAP
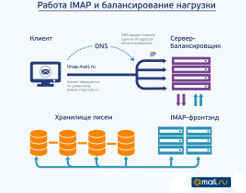 For some time now, IMAP has been working in Mail.Ru Mail in full force, and I’m ready to talk about the problems we encountered when launching it. Some of them were related to the peculiarities of the protocol itself and its history, others were due to the specifics of the interaction of IMAP with our repository. A separate category of difficulties is caused by the variety of mail clients.
For some time now, IMAP has been working in Mail.Ru Mail in full force, and I’m ready to talk about the problems we encountered when launching it. Some of them were related to the peculiarities of the protocol itself and its history, others were due to the specifics of the interaction of IMAP with our repository. A separate category of difficulties is caused by the variety of mail clients.For details - welcome under cat.
The current launch of IMAP is our second approach to the projectile. Last time, we took the Dovecot server and tried to sharpen it for ourselves. The result did not suit us: it did not combine well with our workloads and our infrastructure. This time we decided to choose a different path, and wrote our own solution.
')

IMAP we launched in May, but announced only in June. In fact, the May audience is our employees and those users whose clients automatically determined the presence of IMAP in our Mail and connected new added accounts to it.
IMAP-specific issues
1. The bulkiness of the protocol itself
The first version of the IMAP protocol appeared in 1986. The IMAP standard version 4rev1, which was updated in 2003, is currently relevant. For such a long time, the standard has grown significantly: its current version has about 200 pages.
Now many of the points described in the standard are outdated - in today's conditions they are no longer a necessity. For example, the protocol provides for the return of the number of lines and MD5 sums of parts of a letter - a functional that is not actually used in modern clients.
In addition, there are many optional protocol extensions. Some of them, in fact, are necessary for convenient work with the mailbox.
To overcome the historical legacy, we had to implement several extensions. One of them is UID +: when we copy or add a letter, we return the ID of the new letter that appeared on the server as a result of copying or adding. This allows us to save on the resource-intensive search operation that the client had to carry out in order to recognize which letter was added.
2. The lack of a standard pattern of work with the server
IMAP provides many ways to solve the same problem and, as a result, the work pattern of almost all clients is different. It is also important that the work patterns are significantly different from how webmail or POP3 works.
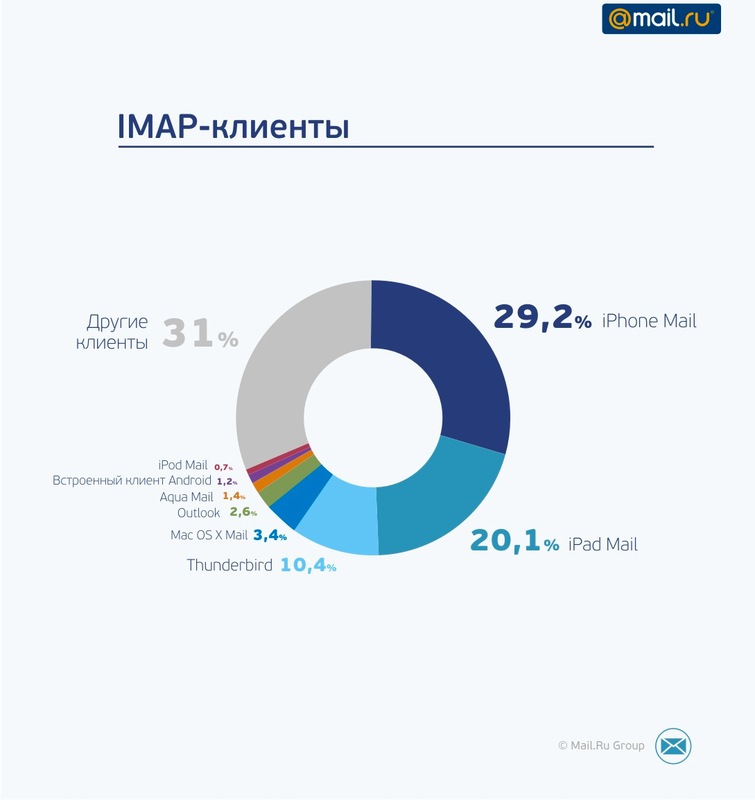
More than half is accounted for by customers for Apple devices: the reason is that IMAP autodetection works well for them. Outloook, by contrast, works by default on POP3, and you need to configure IMAP by hand.
Here you can distinguish 2 main categories: desktop clients, which immediately request information about all the letters in the mailbox or folder, and mobile clients, which initially request information only about the newest letters. Then we had to examine the requests that they make to update the state, how exactly they are pulling information about the letters.
Why for us it was a necessary step? With modest loads (for example, if the server serves the corporate mail of a small company), the issue of optimality is not so acute. However, with our volumes, optimality becomes critical: therefore, we had to study the work patterns of the entire zoo of mail clients accessing the repository.
3. Number of simultaneous sessions
According to the standard, the minimum server timeout is 30 minutes. In addition, one client can hold several connections to the server at once (the protocol does not indicate the maximum number of allowed connections). In fact, on our scale, this means that one server should work optimally with tens of thousands of simultaneous connections. When operating in synchronous mode, such a number of connections would simply consume all resources.
To solve this problem, I wrote a library for asynchronous work, built on the basis of an edge-triggered epoll. Initially, I set myself the task of making a library with which I could write my asynchronous server in the future for a couple of days to solve other tasks besides IMAP; as a result, almost all the code can be used to write other services.
4. Inability to uniquely identify the client
Our server supports the extension ID, which allows us to identify about half of the clients. Unfortunately, the other half do not know about this extension (among the popular ones, for example, Outlook can be called).
Understanding which client we work with allows us to bypass its characteristic bugs, and also to predict what the pattern of work will be during this session and, accordingly, to optimize the work. For us, this is critical, so if the client does not name the ID, we try to identify it in other ways (in the case of Outlook, by tags).
5. No command to move messages
In clients, the movement is implemented through copying + deletion. We, of course, want the copy of the letter to be placed in the right folder, and the original deleted and not littered with a basket. On the other hand, sometimes the user himself copies the letter to a new folder, and then deletes the original: in this case, the deleted letter should be placed in the trash.
In order to distinguish these two cases, after copying we mark the letter in the same session with a special internal flag. When the user himself copies the letter and deletes the original, the client, as a rule, updates the list of letters. When updating, the checkbox is automatically reset, and the deleted letter is in the basket. If the letter (as part of the move) is deleted by the client, the update does not occur, and the letter marked with a flag is permanently deleted.
Difficulties associated with adapting the current store of letters and indexes
1. Message Identification
To work on IMAP, it was necessary to maintain two types of message identifiers: a sequence number, which may differ from session to session, as well as a unique number, which remains for the entire lifetime of the message. Both identifiers must meet fairly strict criteria that did not match the scheme used by webmail and the POP3 server.
The most rational is to keep in memory the entire set of sequence numbers, their correspondence to internal identifiers, as well as IMAP ID. When opening a folder, we pull out from the store a list of all letters, our internal identifiers, IMAP ID, checkboxes, and message size — all that I want to give out without unnecessary requests.
We must notify the client about all changes in the sequence number in one session. According to the standard, the sequence of IMAP ID must match the sequence of sequence numbers. We will get the sequence numbers by sorting the list of letters by unique numbers. When the client issues a new command, we reopen the connection to the repository, request the time of the latest changes that were made in the box. If there have been no changes since the last such request, then we simply return the response to the command. Otherwise, we re-request the list of messages in the folder and compare with the same list of the client. Next, we either return the information about the changes, or if the protocol does not allow doing this right away, we mark the letter that the letter has been deleted and wait for the right moment to inform the client.
Because of this specificity - the letter is no longer in the box, but the client has not yet learned about it - the client may request information about an already deleted letter. Moreover, some of them experienced serious problems if there was no response to their request. So that the client does not break, we return stubs in response to such requests. The client receives the information he needs for normal operation, and the next time the list of letters is updated (it usually happens right away), the message is deleted from it.
2. The need to optimally return information about the MIME structure of the letter
Almost all customers request information about the structure of the letter. Often, during the first session, they request such information at once about all the letters in the folder. Parse letter to each such request would be extremely suboptimal.
Instead, we made a cache of MIME structures. The presence of the cache helped us to overcome several difficulties related to the features of IMAP - in particular, the lack of a standard pattern of work with the server: since some of the information is stored in the cache, it helps to level the load associated with different patterns of clients.
Now we cache up to 50 messages. Why not 2-3? The fact is that some clients first request the structure of the letter, and then the body, and for several messages at once; The maximum number of letters in such a “bundle” is usually 50 pieces.
3. Optimum return of parts of the letter
Often, customers only ask for the text parts of the letter, which may be at the end of the message itself. To display snippets, clients can request text parts from 50-200 emails immediately. You do not want to read the entire message file in its entirety (and process 10 MB of letters in order to give up 10 KB of text); using the index to determine the position of the part within the file with each request would also be costly. In this situation also saves the cache structure of the letter.
The advantages of this approach are especially obvious when a client loads snippets for several dozen letters: if we did not use the cache structure, then for this we would have to look through many megabytes and sacrifice speed.
To save space in our repositories, the base64 parts are stored in decoded form inside the letter: when working with webmail, this allows you to give attachments without extra transcoding. It was necessary to make a scheme of the recoil of the parts, taking into account this recoding. We wrote streaming transcoding on the IMAP server. Here the cache also helped - thanks to it, without rereading the structure, we can understand in what form (binary or not) one fragment or another is stored.
4. Features of the work of some clients
Some clients do not fully comply with the RFC standard: for example, standard Android 2.2 - 2.3 clients cannot correctly display letters without returning some optional fields. The main difficulty was to determine exactly which fields each of these clients considered obligatory: it had to be solved by a search method.
It has already been mentioned above that customers may have different approaches to deleting letters: some move them to the trash, others delete them immediately and irrevocably. However, some clients do not understand the standard XLIST extension, which we support, which allows us to determine which folder is the basket. Instead, they use their own folder as a recycle bin (this is the behavior of Sparrow, for example).
Outlook behaves in an interesting way: when a command is deleted, letters are not moved to the recycle bin, but are marked as crossed out, and then deleted later. It turned out that for users it looks like a bug - many simply do not understand what to do next and how to ensure that the client behaves in the usual way and the letters are in the basket.
In the face of such diversity, we also needed to empirically understand how each of the customers behaves, and adapt to these options - in such a way that the user could be sure that no matter what client he works in, the mail will react to his actions as usual and predictably (in this case, the deleted letter will be in the basket). We solved this by trying different responses through a test proxy server and tracking the client's reaction to each of the options.
What we learned for ourselves: IMAP is a fairly “spreading” thing, with a lot of historical features acquired in 26 years, which are multiplied by the variety of email clients. With our loads, this results in the fact that it’s irrational to take a ready-made solution and try to sharpen it for yourself: at best, the amount of work will be the same as when developing a solution on your own. This way we went :)
Victor Starodub,
Mail.ru Mail team
Source: https://habr.com/ru/post/151001/
All Articles