Interception of video in a browser or TCP sniffer under Windows on the knee (part two)
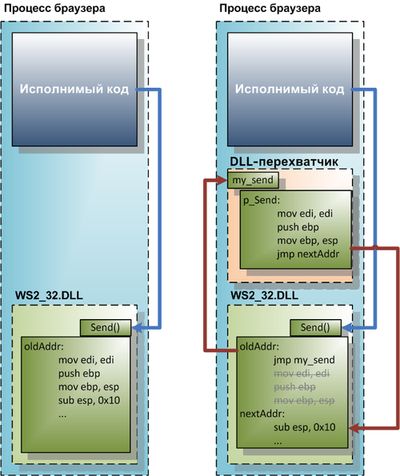
This is a promised addition to my previous post , which tells about an alternative technique for setting traps on functions. One of the drawbacks of the implementation of traps in the previous post was the constant rewriting of the code at the beginning of the intercepted function. As an alternative, a solution was mentioned that would not require permanent rewriting. A schematic diagram of his work is provided here:
Sources, details and explanations under the cat ...
So, I took the time to finish the implementation of the "so-called. permanent traps that do not require code rewriting when calling the original function. The source code is here , and the compiled version is here .
We did open the can of worms or Pandora’s box, as you like. And it's time for me to relinquish my commitment to writing the perfect interceptor, because the number of branches and checks for its implementation smoothly translates this task into a nondeterministic area.
')
In this regard, I have to immediately warn you that this code works correctly only for WS2_32 functions, and only within the framework of this example. To intercept other functions, the code must be completed in the direction of a more extensive analysis of instructions at the entry point (for a specific function or for real-time analysis). And the thing is this.
As can be seen from the figure above, the interceptor sets traps by changing the first five bytes at the entry point to an unconditional transition to its own handler. These bytes, which are overwritten, are stored in our structures. In the previous example, there were no problems in this regard, since we restored the entry point to its original state each time the original function was called. But now the conditions have changed - we will no longer rewrite bytes.
Therefore, we will execute the first instructions of the original code from the entry point directly from the place where we copied them, and at the end we will go back to those instructions that we did not erase. And here we come close to the features of the machine code x86 processors.
Processor instructions have a different size, which can vary from 1 to 15 bytes. Thus, it is not known a priori what and how exactly we break after installing the trap using the five-byte patch method. At the entry point, in theory, there can be anything, so there are two options - either move from the general method to the particular method or complicate the logic.
“From the general to the particular” means that we will set our traps for specific functions, having previously studied them all and found the best method for each separately. This is not very convenient, because for example, for the same WinSock, there are many versions of it such as XP, XPSP1, XPSP2, XPSP3, Vista, VistaSP1, Vista PU, Windows 7, etc. And there are all sorts of security updates that can also install their own versions of the system libraries. Therefore, in order for traps to work correctly using a private method, all possible versions of the same library will have to be scanned. Fortunately, for the most part, different versions of libraries are not so different from each other exactly at the entry point.
“Complicated logic” means writing an instruction analyzer which
a) It will be able to calculate the size of opcodes of the processor in order to always transfer control to the “whole” instruction, and not somewhere in the middle.
b) Will be able to detect problem areas and correctly process them.
The “other” trap will serve as the most obvious example of a problem area. Suppose we are not the first to infiltrate the process and intercept the function. In this case, we will see the first instruction in most cases JMP XX XX XX XX, in some cases PUSH XX XX XX XX RETN, and in theory anything at all. Therefore, in the case of JMP, we will not be able to correctly execute the copied code from another place, because the transition is relative and is considered relative to the address of its execution. Therefore, this transition will have to be recounted. But in the case of PUSH-RETN address is not necessary to recalculate. And in the case of “anything,” there could be such an example of a problem area:
In this case, we get a complexhemorrhoids case:
If you are filled with all the subtlety of bullying, then I can give one good advice. Writing a universal analyzer is possible, but for this it is necessary to prepare a set of solution templates for each such stumbling block. For example - “if unconditional transition is at the beginning”, “if there is a conditional transition”, “if there is a function call”, “if in the middle ...”, etc. Next, each template is applied according to the step-by-step analysis of instructions. But believe me, this requires tangible investments in writing code, for which I am not ready yet.
For the reasons given above, in this example, I focused on a particular solution for WS2_32. So, all the functions that we intercept, start as standard:
I suspect that Microsoft did it specifically to use similar techniques in some Microsoft Detours. But I personally did not see it and didn’t feel it, so I’m not going to fantasize further on this topic. So, the beginning of all the required WinSock functions is ideally suited to the size of the unconditional transition at the beginning of the function, because:
a) The first three instructions occupy exactly five bytes.
b) The first three instructions are not tied to a specific address and can be executed inside our handler.
Behind this, we begin to modify the Interceptor.cpp code ... First of all, we will create a directive that will separate the oldchaff from the new chaff and add the installation code:
Everything should be clear here except for calling the magic function getX86InstructionLength () . In order not to suffer with questions, I will answer. Initially, this function always returned 5. Since we agreed to implement a special case, there is no big demand — 5 bytes is the length of the first three instructions at the entry point. But I went a little further and in the source you will find a real x86 instruction length analyzer. This is my contribution to someone's future smart interceptor, so to speak ... In this post, I would not want to deviate in that direction because of the vastness of the issue.
So, the above described code copies the first 5 bytes from the entry point to itself and after them puts an unconditional transition back to the original function on the instruction with the sequence number 4, which remains intact. Thus, we “forward” a static call to the original function without using code rewriting tricks at the entry point.
Similarly, we add the removal of traps and restore the original state of the function:
It is worth noting that in order to work correctly with DEP (Data Execution Prevention) we need to set EXECUTE rights to a piece of memory where a copy of the original code will be stored. Otherwise, the system simply will not allow this code to execute. Since now we do not need to rewrite anything, it is worth adding the macros to the declaration of the functions being intercepted:
As can be seen from the code, instead of the original imported function, we now call its prototype at thisHook-> oldProc. This is exactly the place where we saved the original five bytes and added them back to the transition.
In general, that's all. In the source code, the PERSISTENT_HOOKS directive is responsible for switching the old and new interception methods, and by default the new method is used without overwriting.
By the way, I deliberately did not mention another method in which interception is carried out deep from the inside of the original code. This is an even more interesting task, albeit a more difficult one. Someone asked me, "why is it even necessary?". I answer with a hint that there are programs that count the checksums of code fragments at the entry point and are sensitive to their changes. But fortunately, browsers are not one of them yet.
Do not forget that I do not pretend to originality and is far from being a pioneer in this field. So there are people who have in their arsenal more elegant solutions than my attempts in this direction.
Respectfully,
// st
Sources, details and explanations under the cat ...
So, I took the time to finish the implementation of the "so-called. permanent traps that do not require code rewriting when calling the original function. The source code is here , and the compiled version is here .
We did open the can of worms or Pandora’s box, as you like. And it's time for me to relinquish my commitment to writing the perfect interceptor, because the number of branches and checks for its implementation smoothly translates this task into a nondeterministic area.
')
In this regard, I have to immediately warn you that this code works correctly only for WS2_32 functions, and only within the framework of this example. To intercept other functions, the code must be completed in the direction of a more extensive analysis of instructions at the entry point (for a specific function or for real-time analysis). And the thing is this.
As can be seen from the figure above, the interceptor sets traps by changing the first five bytes at the entry point to an unconditional transition to its own handler. These bytes, which are overwritten, are stored in our structures. In the previous example, there were no problems in this regard, since we restored the entry point to its original state each time the original function was called. But now the conditions have changed - we will no longer rewrite bytes.
Therefore, we will execute the first instructions of the original code from the entry point directly from the place where we copied them, and at the end we will go back to those instructions that we did not erase. And here we come close to the features of the machine code x86 processors.
Processor instructions have a different size, which can vary from 1 to 15 bytes. Thus, it is not known a priori what and how exactly we break after installing the trap using the five-byte patch method. At the entry point, in theory, there can be anything, so there are two options - either move from the general method to the particular method or complicate the logic.
“From the general to the particular” means that we will set our traps for specific functions, having previously studied them all and found the best method for each separately. This is not very convenient, because for example, for the same WinSock, there are many versions of it such as XP, XPSP1, XPSP2, XPSP3, Vista, VistaSP1, Vista PU, Windows 7, etc. And there are all sorts of security updates that can also install their own versions of the system libraries. Therefore, in order for traps to work correctly using a private method, all possible versions of the same library will have to be scanned. Fortunately, for the most part, different versions of libraries are not so different from each other exactly at the entry point.
“Complicated logic” means writing an instruction analyzer which
a) It will be able to calculate the size of opcodes of the processor in order to always transfer control to the “whole” instruction, and not somewhere in the middle.
b) Will be able to detect problem areas and correctly process them.
The “other” trap will serve as the most obvious example of a problem area. Suppose we are not the first to infiltrate the process and intercept the function. In this case, we will see the first instruction in most cases JMP XX XX XX XX, in some cases PUSH XX XX XX XX RETN, and in theory anything at all. Therefore, in the case of JMP, we will not be able to correctly execute the copied code from another place, because the transition is relative and is considered relative to the address of its execution. Therefore, this transition will have to be recounted. But in the case of PUSH-RETN address is not necessary to recalculate. And in the case of “anything,” there could be such an example of a problem area:
00004EE1: 3C01 cmp al,1 00004EE3: 7404 je 000004EE9 00004EE5: E916010000 jmp 000005000 In this case, we get a complex
- There is a relative conditional transition, which is buried by our 5 bytes and which we cannot correctly execute in our handler due to its relativity. There are two ways out: either recalculate the transition to the original address and, as a result, it is very likely to change the length of the instruction from two to six bytes, for a two-byte transition is short and runs at plus / minus 128 bytes; or copy to yourself also the code to which the conditional jump will probably jump. In the first case, since we will change the size of the instruction, we will have to recalculate all subsequent code to the new addresses. In the second case, it is obvious that we need to simulate the situation when the transition will occur and when it will not happen and squeeze the return to the place that is guaranteed to receive control. Again, if we consider that the code that the conditional transition points to may also have its own conditional and unconditional transitions, then we are faced with a very interesting task.
- Part of the unconditional transition, or rather the JMP instruction itself, is also rubbed with our five bytes. If we go back to the next intact instruction, then it is obvious that the original code will not work correctly, because we skip the unconditional transition. In another case, if we copy all the instructions entirely, then the unconditional transition will be made somewhere in the hyperspace, since it is relative. Therefore, it will be necessary to calculate the correct address from the new place, which, together with the previous item, promises us a dull life.
If you are filled with all the subtlety of bullying, then I can give one good advice. Writing a universal analyzer is possible, but for this it is necessary to prepare a set of solution templates for each such stumbling block. For example - “if unconditional transition is at the beginning”, “if there is a conditional transition”, “if there is a function call”, “if in the middle ...”, etc. Next, each template is applied according to the step-by-step analysis of instructions. But believe me, this requires tangible investments in writing code, for which I am not ready yet.
For the reasons given above, in this example, I focused on a particular solution for WS2_32. So, all the functions that we intercept, start as standard:
8BFF mov edi,edi 55 push ebp 8BEC mov ebp,esp 83ECXX sub esp,0000000XX I suspect that Microsoft did it specifically to use similar techniques in some Microsoft Detours. But I personally did not see it and didn’t feel it, so I’m not going to fantasize further on this topic. So, the beginning of all the required WinSock functions is ideally suited to the size of the unconditional transition at the beginning of the function, because:
a) The first three instructions occupy exactly five bytes.
b) The first three instructions are not tied to a specific address and can be executed inside our handler.
Behind this, we begin to modify the Interceptor.cpp code ... First of all, we will create a directive that will separate the old
/************************************************************************/ /* */ /************************************************************************/ BOOL hookInstall(PAPIHOOK thisHook) { ... #ifdef PERSISTENT_HOOKS // thisHook->oldCodeSize = 0; // 5 // . // (5 ) for (; thisHook->oldCodeSize < HOOK_CODE_SIZE; ) { // int opSize = getX86InstructionLength((PBYTE) thisHook->oldAddr + thisHook->oldCodeSize); // thisHook->oldCodeSize += opSize; } // + thisHook->oldCode = (UCHAR *) xmalloc(thisHook->oldCodeSize + HOOK_CODE_SIZE); if (NULL == thisHook->oldCode) { SetLastError(ERROR_NOT_ENOUGH_MEMORY); return FALSE; } DWORD fl; // EXECUTE DEP VirtualProtect(thisHook->oldCode, thisHook->oldCodeSize + HOOK_CODE_SIZE, PAGE_EXECUTE_READWRITE, &fl); // memcpy(thisHook->oldCode, thisHook->oldAddr, thisHook->oldCodeSize); // ... thisHook->oldCode[thisHook->oldCodeSize] = asmJMP; // ... , // JMP DWORD *d = (DWORD*) ((PBYTE) (thisHook->oldCode + thisHook->oldCodeSize + 1)); *d = (DWORD) ((PBYTE) thisHook->oldAddr + thisHook->oldCodeSize) - (DWORD) d - sizeof(DWORD); #else // // thisHook->oldCodeSize = HOOK_CODE_SIZE; memcpy(thisHook->oldCode, thisHook->oldAddr, HOOK_CODE_SIZE); #endif // thisHook->isInstalled = TRUE; // hookEnable(thisHook); #ifdef PERSISTENT_HOOKS // VirtualProtect(thisHook->oldAddr, HOOK_CODE_SIZE, oldFlags, &oldFlags); #endif return TRUE; } Everything should be clear here except for calling the magic function getX86InstructionLength () . In order not to suffer with questions, I will answer. Initially, this function always returned 5. Since we agreed to implement a special case, there is no big demand — 5 bytes is the length of the first three instructions at the entry point. But I went a little further and in the source you will find a real x86 instruction length analyzer. This is my contribution to someone's future smart interceptor, so to speak ... In this post, I would not want to deviate in that direction because of the vastness of the issue.
So, the above described code copies the first 5 bytes from the entry point to itself and after them puts an unconditional transition back to the original function on the instruction with the sequence number 4, which remains intact. Thus, we “forward” a static call to the original function without using code rewriting tricks at the entry point.
Similarly, we add the removal of traps and restore the original state of the function:
/************************************************************************/ /* */ /************************************************************************/ BOOL hookRemove(PAPIHOOK thisHook) { // , if (!thisHook->isInstalled) return FALSE; #ifdef PERSISTENT_HOOKS DWORD oldFlags; if (!VirtualProtect(thisHook->oldAddr, HOOK_CODE_SIZE, PAGE_EXECUTE_READWRITE, &oldFlags) || IsBadWritePtr(thisHook->oldAddr, HOOK_CODE_SIZE)) { SetLastError(ERROR_WRITE_PROTECT); return FALSE; // } #endif // hookDisable(thisHook); #ifdef PERSISTENT_HOOKS VirtualProtect(thisHook->oldAddr, HOOK_CODE_SIZE, oldFlags, &oldFlags); if (thisHook->oldCode != NULL) xfree(thisHook->oldCode); #endif // thisHook->isInstalled = FALSE; // thisHook->newAddr = (LPVOID) NULL; thisHook->oldAddr = (LPVOID) NULL; return TRUE; } It is worth noting that in order to work correctly with DEP (Data Execution Prevention) we need to set EXECUTE rights to a piece of memory where a copy of the original code will be stored. Otherwise, the system simply will not allow this code to execute. Since now we do not need to rewrite anything, it is worth adding the macros to the declaration of the functions being intercepted:
#ifdef PERSISTENT_HOOKS /************************************************************************/ /* */ /* : typedef int (WSAAPI *PF_send) (SOCKET s, char *buf, int len, int flags); int WSAAPI my_send(SOCKET s, char *buf, int len, int flags) { PAPIHOOK thisHook = hookFind(my_send); PF_send p_send = (PF_send) thisHook->oldProc; if (NULL == thisHook || NULL == p_send) return (int) 0; int rv; ... /************************************************************************/ #define DEFINE_HOOK(RTYPE, CTYPE, NAME, ARGS)\ typedef RTYPE(CTYPE *PF_##NAME) ##ARGS; \ RTYPE CTYPE my_##NAME ##ARGS \ { \ PAPIHOOK thisHook = hookFind(my_##NAME); \ PF_##NAME p_##NAME = (PF_##NAME) thisHook->oldProc; \ if (NULL == thisHook || NULL == p_##NAME) \ return (RTYPE) 0; \ RTYPE rv; #define LEAVE_HOOK() } \ return rv; As can be seen from the code, instead of the original imported function, we now call its prototype at thisHook-> oldProc. This is exactly the place where we saved the original five bytes and added them back to the transition.
In general, that's all. In the source code, the PERSISTENT_HOOKS directive is responsible for switching the old and new interception methods, and by default the new method is used without overwriting.
By the way, I deliberately did not mention another method in which interception is carried out deep from the inside of the original code. This is an even more interesting task, albeit a more difficult one. Someone asked me, "why is it even necessary?". I answer with a hint that there are programs that count the checksums of code fragments at the entry point and are sensitive to their changes. But fortunately, browsers are not one of them yet.
Do not forget that I do not pretend to originality and is far from being a pioneer in this field. So there are people who have in their arsenal more elegant solutions than my attempts in this direction.
Respectfully,
// st
Source: https://habr.com/ru/post/150933/
All Articles