7 lessons learned from creating Reddit
UPD. The original article is quite old - 2010. Now the situation looks different.
In December 2010, Reddit had 829M hits and 119 servers.
At the end of 2011 - 2.07B views and 240 servers.
Thank you potomushto for the update.
')
UPD 2. Corrected scheme for people with color perception problems. Thank you second_pilot and spiritedflow
Steve Huffman, one of the creators of Reddit, told at the presentation what they had learned while building and developing Reddit to 7.5 million users per month, 270 million page views per month and more than 20 database servers.
Steve said that most of the lessons learned were obvious, so the presentation will not be radically new ideas. But Steve has a lot of experience, and if he couldn't see this rake, then maybe you should pay attention to these “obvious things”.
Each of the 7 lessons will be discussed in the corresponding section.
The most interesting point of the Reddit architecture is “Lesson 6 - save redundant data”. The basic idea is very simple - we reach speed by making a pre-calculation of everything and caching it. Reddit uses the maximum pre-calculation. It seems that everything that you see on Reddit was calculated in advance and cached, regardless of how many versions of the data they have to store. For example, they cache all 15 ways to sort messages (hot, new, best old, this week, etc.) for a list of messages as soon as someone adds a link. Ordinary developers will be afraid to make such an extreme cache, considering it a waste of resources. But the Reddit team thinks it's better to spend some resources than to slow down. Spending disk space and memory is better than keeping users waiting. So, if you were embarrassed to use pre-calculation and caching to the maximum, you have a good precedent.
The essence of the lesson is simple - automatically restart the crashed or failed services.
The problem with using dedicated servers is that you are constantly responsible for their support. When your service crashes, you should fix it right now, even at 2 am. This creates a constant background tension in your life. You must constantly carry a computer with you, and you know that at any moment someone can call to report about another disaster. Which will have to rake. Such an approach makes life unbearable.
One of the methods to solve this problem is to restart the service, which has died or began to behave incorrectly. Reddit uses supervisors to restart applications. Special monitoring programs kill processes that eat up too much memory, CPU time, or just hang. Instead of worrying, just restart the system. Of course, you will have to read the logs in order to understand the reason for the fall. But such an approach will keep you calm and reasonable.
The essence of the lesson - group similar processes and data on different machines.
Performing too many actions on one machine will require a large context switch for tasks. Try to make each of your servers serve a particular data type in a specific way. This means that all your indexes will fall into the cache, and will not fall out of it. Keep similar data as close as possible to each other. Do not use Python streams. They slow down. Reddit developers have divided everything into several services. Services include spam checking, image processing and query caching. This makes it easy to spread them across multiple machines. Thus, they solved the problem of process interactions. And when this problem is solved, the architecture becomes cleaner and grows easier.
The essence of the lesson - do not worry about the scheme.
The developers of Reddit have spent a lot of time worrying about the data structure and their normalization. Scheme changes became more and more expensive as they grew. Adding one column to 10 million lines required a bunch of locks, and worked very poorly. Reddit used replication for scaling and backup. Updating the schema and replication support is hard work. Sometimes you had to restart replication, and the backup might not work all day. The releases also caused problems, because they had to make sure that the software update and the update of the database schema were completed simultaneously.
Instead, they use the Table of Entities and the Data Table. In Reddit-e, everything is an entity — users, links, comments, sub-forums, awards, etc. Entities share several common attributes, such as votes for / against, type, date of creation. The Data Table contains 3 columns - thing id, key, value. On line for each attribute. There is a line for the title, for the link, the author, votes for spam, etc. Now, when adding a new feature, they don’t have to worry about the structure of the database. No need to add new tables for new entities or worry about updates. Easier to design and maintain. Price - the inability to use cool relational capabilities. You cannot use join and you must manually ensure data integrity. You do not have to worry about foreign keys when you join, or how to split data. In general, it turned out well. Concerns about relational databases are a thing of the past.
The goal of each server is simple - to process a request of any type. And while Reddit was growing up, they had to use more and more machines, and it was already impossible to rely on the application server cache. Initially, they duplicated the state of each application server, which was a waste of RAM. They could not use memcached, because they kept a huge amount of small data in their memory, which did not give an increase in speed. They rewrote the service to support memcache and no longer store state in the application servers. Even if the application servers are falling - life does not stop. And scaling is now just a matter of adding new servers.
The essence of the lesson - use memcache for everything.
Reddit uses memcache for:
Now they store all the data in Memcachedb, not Postgres. This is an analogue of memcache, but saves data to disk. Very quick fix. All requests are generated by the same piece of code and cached in memcache. Changed passwords, links are cached for 20 minutes or so. The same can be said about captcha. They use the same approach for links that do not want to keep forever.
They have built in their framework memoizatsiyu. Calculated results are also cached: normalized pages, lists, and everything else.
They limit the number of requests using memcache + a limited request lifetime. A good way to protect your system from attacks. Without such a subsystem, any unscrupulous user could put systems. Do not feng shui. Therefore, for users and indexers, they store data in memcache. If the user makes a second call in less than a second, he bounces off. Regular users do not click so quickly, so they do not notice anything. Google's indexer will process you as often as you allow, so when everything starts to slow down, just limit the frequency of requests. And the system will start to work quieter, without creating inconvenience for users.
Everything in Reddit is a list. Home page, private messages, comments page. All of them are calculated in advance and placed in the cache. When you get a list, it is taken from the cache. Each link and each comment is likely saved in 100 different variations. For example, a link with 2 votes created 30 seconds ago is expected and saved separately. After 30 seconds, it is rendered again. And so on. Every bit of HTML comes from the cache. Therefore, processor time is not spent on rendering pages. If everything starts to slow down - just add more cache.
When they come to work with their inconsistent database, they use memcache as a global lock. It works, although it is not the best option.
The essence of the lesson: in order to achieve maximum speed - calculate everything in advance and cache the result.
A guaranteed way to make a slow web site is to have a normalized database, access it on demand, and then generate HTML. It takes forever even for a single request. Therefore, if you have data that can be displayed in several formats, the links on the main page, in incoming messages, profiles, store all these views separately. But when someone comes in and accesses the data, they are ready.
Each list can have 15 different sorting orders (hot, new, best, old, current week). When someone adds a new link, they recount all the lists that this may concern. At first glance, it looks too wasteful, but it is better to spend money first than to brake. To waste disk space and memory is better than making the user wait.
The essence of the lesson: make at least the server part, and tell the user that everything is ready.
If you need to do something, do it when the user is not waiting for you. Put the job in the queue. When a user votes on Reddit, the lists, user's karma, and many other things are updated. Therefore, the voting database is updated to mark the fact of voting. After this task is queued, and the task knows all 20 things that need to be updated. When the user returns, all the necessary data will be cached.
What Reddit does in the background:
There is no need to do these things while the user is waiting for you. For example, when Reddit became popular, attempts to cheat the rating increased. Therefore, they spend a lot of server time to detect such situations. The work of this service in the background does not prevent users from voting further.
An architecture diagram is provided below:
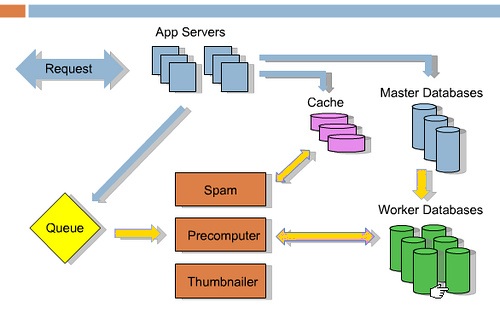
Blue arrows indicate what happens when a request is received. Suppose someone leaves a link or votes. This data goes to the cache, the main database, and to the work queue. The result is returned to the user. The remaining things that happen offline are represented by yellow arrows. Services like Spam, Precomputer, and Thumnailer receive tasks from the queue, execute them, and update the database. The main highlight of the technological solution is RabbitMQ.
PS It is very interesting to compare the lessons of Reddit with the practitioners of designing applications for Erlang. Let it fail, Supervision tree, mnesia. Russian translation of OTP documentation can be found here .
PPS There is an idea to translate a couple of chapters from RabbitMQ in Action. How interesting will it be?
In December 2010, Reddit had 829M hits and 119 servers.
At the end of 2011 - 2.07B views and 240 servers.
Thank you potomushto for the update.
')
UPD 2. Corrected scheme for people with color perception problems. Thank you second_pilot and spiritedflow
Steve Huffman, one of the creators of Reddit, told at the presentation what they had learned while building and developing Reddit to 7.5 million users per month, 270 million page views per month and more than 20 database servers.
Steve said that most of the lessons learned were obvious, so the presentation will not be radically new ideas. But Steve has a lot of experience, and if he couldn't see this rake, then maybe you should pay attention to these “obvious things”.
Each of the 7 lessons will be discussed in the corresponding section.
- Fall often
- Separation of services
- Open data schema
- Avoid storing states
- Memcache
- Save redundant data
- Perform maximum work in the background
The most interesting point of the Reddit architecture is “Lesson 6 - save redundant data”. The basic idea is very simple - we reach speed by making a pre-calculation of everything and caching it. Reddit uses the maximum pre-calculation. It seems that everything that you see on Reddit was calculated in advance and cached, regardless of how many versions of the data they have to store. For example, they cache all 15 ways to sort messages (hot, new, best old, this week, etc.) for a list of messages as soon as someone adds a link. Ordinary developers will be afraid to make such an extreme cache, considering it a waste of resources. But the Reddit team thinks it's better to spend some resources than to slow down. Spending disk space and memory is better than keeping users waiting. So, if you were embarrassed to use pre-calculation and caching to the maximum, you have a good precedent.
Lesson 1: Fall down often
The essence of the lesson is simple - automatically restart the crashed or failed services.
The problem with using dedicated servers is that you are constantly responsible for their support. When your service crashes, you should fix it right now, even at 2 am. This creates a constant background tension in your life. You must constantly carry a computer with you, and you know that at any moment someone can call to report about another disaster. Which will have to rake. Such an approach makes life unbearable.
One of the methods to solve this problem is to restart the service, which has died or began to behave incorrectly. Reddit uses supervisors to restart applications. Special monitoring programs kill processes that eat up too much memory, CPU time, or just hang. Instead of worrying, just restart the system. Of course, you will have to read the logs in order to understand the reason for the fall. But such an approach will keep you calm and reasonable.
Lesson 2: Sharing Services
The essence of the lesson - group similar processes and data on different machines.
Performing too many actions on one machine will require a large context switch for tasks. Try to make each of your servers serve a particular data type in a specific way. This means that all your indexes will fall into the cache, and will not fall out of it. Keep similar data as close as possible to each other. Do not use Python streams. They slow down. Reddit developers have divided everything into several services. Services include spam checking, image processing and query caching. This makes it easy to spread them across multiple machines. Thus, they solved the problem of process interactions. And when this problem is solved, the architecture becomes cleaner and grows easier.
Lesson 3: Open Database Schema
The essence of the lesson - do not worry about the scheme.
The developers of Reddit have spent a lot of time worrying about the data structure and their normalization. Scheme changes became more and more expensive as they grew. Adding one column to 10 million lines required a bunch of locks, and worked very poorly. Reddit used replication for scaling and backup. Updating the schema and replication support is hard work. Sometimes you had to restart replication, and the backup might not work all day. The releases also caused problems, because they had to make sure that the software update and the update of the database schema were completed simultaneously.
Instead, they use the Table of Entities and the Data Table. In Reddit-e, everything is an entity — users, links, comments, sub-forums, awards, etc. Entities share several common attributes, such as votes for / against, type, date of creation. The Data Table contains 3 columns - thing id, key, value. On line for each attribute. There is a line for the title, for the link, the author, votes for spam, etc. Now, when adding a new feature, they don’t have to worry about the structure of the database. No need to add new tables for new entities or worry about updates. Easier to design and maintain. Price - the inability to use cool relational capabilities. You cannot use join and you must manually ensure data integrity. You do not have to worry about foreign keys when you join, or how to split data. In general, it turned out well. Concerns about relational databases are a thing of the past.
Lesson 4: Avoid storing states
The goal of each server is simple - to process a request of any type. And while Reddit was growing up, they had to use more and more machines, and it was already impossible to rely on the application server cache. Initially, they duplicated the state of each application server, which was a waste of RAM. They could not use memcached, because they kept a huge amount of small data in their memory, which did not give an increase in speed. They rewrote the service to support memcache and no longer store state in the application servers. Even if the application servers are falling - life does not stop. And scaling is now just a matter of adding new servers.
Lesson 5: Memcache
The essence of the lesson - use memcache for everything.
Reddit uses memcache for:
- Database data
- Session data
- Generated pages
- Memoisation (caching previously calculated results) of internal functions
- Restrictions on the number of requests
- Storage of pre-calculated lists and pages
- Global locks
Now they store all the data in Memcachedb, not Postgres. This is an analogue of memcache, but saves data to disk. Very quick fix. All requests are generated by the same piece of code and cached in memcache. Changed passwords, links are cached for 20 minutes or so. The same can be said about captcha. They use the same approach for links that do not want to keep forever.
They have built in their framework memoizatsiyu. Calculated results are also cached: normalized pages, lists, and everything else.
They limit the number of requests using memcache + a limited request lifetime. A good way to protect your system from attacks. Without such a subsystem, any unscrupulous user could put systems. Do not feng shui. Therefore, for users and indexers, they store data in memcache. If the user makes a second call in less than a second, he bounces off. Regular users do not click so quickly, so they do not notice anything. Google's indexer will process you as often as you allow, so when everything starts to slow down, just limit the frequency of requests. And the system will start to work quieter, without creating inconvenience for users.
Everything in Reddit is a list. Home page, private messages, comments page. All of them are calculated in advance and placed in the cache. When you get a list, it is taken from the cache. Each link and each comment is likely saved in 100 different variations. For example, a link with 2 votes created 30 seconds ago is expected and saved separately. After 30 seconds, it is rendered again. And so on. Every bit of HTML comes from the cache. Therefore, processor time is not spent on rendering pages. If everything starts to slow down - just add more cache.
When they come to work with their inconsistent database, they use memcache as a global lock. It works, although it is not the best option.
Lesson 6: Save redundant data
The essence of the lesson: in order to achieve maximum speed - calculate everything in advance and cache the result.
A guaranteed way to make a slow web site is to have a normalized database, access it on demand, and then generate HTML. It takes forever even for a single request. Therefore, if you have data that can be displayed in several formats, the links on the main page, in incoming messages, profiles, store all these views separately. But when someone comes in and accesses the data, they are ready.
Each list can have 15 different sorting orders (hot, new, best, old, current week). When someone adds a new link, they recount all the lists that this may concern. At first glance, it looks too wasteful, but it is better to spend money first than to brake. To waste disk space and memory is better than making the user wait.
Lesson 7: Maximize your work in the background.
The essence of the lesson: make at least the server part, and tell the user that everything is ready.
If you need to do something, do it when the user is not waiting for you. Put the job in the queue. When a user votes on Reddit, the lists, user's karma, and many other things are updated. Therefore, the voting database is updated to mark the fact of voting. After this task is queued, and the task knows all 20 things that need to be updated. When the user returns, all the necessary data will be cached.
What Reddit does in the background:
- Cache Lists
- Process images
- Detect cheaters
- Remove spam
- Calculate rewards
- Update Search Index
There is no need to do these things while the user is waiting for you. For example, when Reddit became popular, attempts to cheat the rating increased. Therefore, they spend a lot of server time to detect such situations. The work of this service in the background does not prevent users from voting further.
An architecture diagram is provided below:
Blue arrows indicate what happens when a request is received. Suppose someone leaves a link or votes. This data goes to the cache, the main database, and to the work queue. The result is returned to the user. The remaining things that happen offline are represented by yellow arrows. Services like Spam, Precomputer, and Thumnailer receive tasks from the queue, execute them, and update the database. The main highlight of the technological solution is RabbitMQ.
PS It is very interesting to compare the lessons of Reddit with the practitioners of designing applications for Erlang. Let it fail, Supervision tree, mnesia. Russian translation of OTP documentation can be found here .
PPS There is an idea to translate a couple of chapters from RabbitMQ in Action. How interesting will it be?
Source: https://habr.com/ru/post/150802/
All Articles