How does sorting work with Reddit
Now on Habré continue to discuss the sorting and rating of entities (records, posts, comments), so I myself became interested in it and, just being on the reddit, decided to find out how sorting works there, and came across an excellent and short article.
This post is a continuation of the analysis of sorting algorithms (last time was Hacker News ). This time, we will analyze how the sorting of posts and comments on Reddit works. Reddit's algorithms are simple enough to understand and implement them.
The first part of this post will focus on sorting posts, and the second on sorting comments. They are quite different, and Randall Munroe (by xkcd) is behind the idea of how comments are sorted.
')
Reddit is an open-source project and its code is fully accessible on github. It is written in python, the source code you can see here . Their sorting algorithms are written under Pyrex, for further compilation (translation) into C-code. Pyrex was chosen due to performance. I rewrote their implementations on a clean python so that they are easier to read.
The default sorting algorithm, called the “hot ranking”, is implemented as follows:
In mathematical writing, this algorithm looks like this:

Here is what can be said about obsolescence regarding sorting ratings (hereinafter simply ratings) and sorting:
Here is a visualization of what a rating of articles looks like with the same number of pros and cons, but different publication times:

Hot ranking uses the logarithm so that the first n votes weigh more than the future n + r votes. The result is that the first 10 pluses have the same weight as the next 100, which have the same weight as the next 1000, and so on.
Here's what it looks like:

But what would it look like without logarithm:

Reddit - one of those sites where you can minus. As you saw in the code, the “score” of the post is equal to the difference of pros and cons.
In the end, it looks like this:

This has a great impact on posts that get a lot of pros and cons (so-called controversial posts), they get a lower rating than posts with only pluses. Perhaps that’s why kittens are so often on the main one :) (approx. Lane - in fact, it’s because you didn’t unsubscribe from / r / aww)
Randall Munroe from xkcd is behind the idea of Redditovsky best ranking. He wrote a great article about it: reddit's new comment sorting system
You should read this article, in it he very clearly explains the principle of the algorithm. Summarizing it, you can say:
The trust sorting algorithm is implemented in _sorts.pyx , I also rewrote it to a clean python (and removed some cache optimizations):
Sorting by trust uses the Wilson interval and the mathematical notation looks like this:
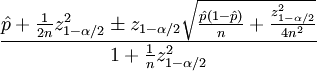
List of parameters for this formula:
Let's summarize the above:
Randall has a great example of how comments are rated:
As we see, this algorithm is not affected in any way by the obsolescence of records.
Let's see what it looks like:

As you can see, this sorting is not a matter of how many votes received a comment, but rather how many advantages in relation to the total number of votes and the sample size.
As Evan Miller notes, the Wilson interval can be used not only for rating.
Here are three examples that he cited:
This post is a continuation of the analysis of sorting algorithms (last time was Hacker News ). This time, we will analyze how the sorting of posts and comments on Reddit works. Reddit's algorithms are simple enough to understand and implement them.
The first part of this post will focus on sorting posts, and the second on sorting comments. They are quite different, and Randall Munroe (by xkcd) is behind the idea of how comments are sorted.
')
Parse post sorting
Reddit is an open-source project and its code is fully accessible on github. It is written in python, the source code you can see here . Their sorting algorithms are written under Pyrex, for further compilation (translation) into C-code. Pyrex was chosen due to performance. I rewrote their implementations on a clean python so that they are easier to read.
The default sorting algorithm, called the “hot ranking”, is implemented as follows:
#Rewritten code from /r2/r2/lib/db/_sorts.pyx from datetime import datetime, timedelta from math import log epoch = datetime(1970, 1, 1) def epoch_seconds(date): """Returns the number of seconds from the epoch to date.""" td = date - epoch return td.days * 86400 + td.seconds + (float(td.microseconds) / 1000000) def score(ups, downs): return ups - downs def hot(ups, downs, date): """The hot formula. Should match the equivalent function in postgres.""" s = score(ups, downs) order = log(max(abs(s), 1), 10) sign = 1 if s > 0 else -1 if s < 0 else 0 seconds = epoch_seconds(date) - 1134028003 return round(order + sign * seconds / 45000, 7) In mathematical writing, this algorithm looks like this:
Obsolescence of records
Here is what can be said about obsolescence regarding sorting ratings (hereinafter simply ratings) and sorting:
- The age of the article has a great influence on its rating, the newer - the higher the rating it will receive
- The rating does not decrease with the obsolescence of articles, but grows with new articles.
Here is a visualization of what a rating of articles looks like with the same number of pros and cons, but different publication times:
Logarithmic scale
Hot ranking uses the logarithm so that the first n votes weigh more than the future n + r votes. The result is that the first 10 pluses have the same weight as the next 100, which have the same weight as the next 1000, and so on.
Here's what it looks like:
But what would it look like without logarithm:
Impact of "cons"
Reddit - one of those sites where you can minus. As you saw in the code, the “score” of the post is equal to the difference of pros and cons.
In the end, it looks like this:
This has a great impact on posts that get a lot of pros and cons (so-called controversial posts), they get a lower rating than posts with only pluses. Perhaps that’s why kittens are so often on the main one :) (approx. Lane - in fact, it’s because you didn’t unsubscribe from / r / aww)
Conclusion on sorting posts
- Adding time is a very important parameter, newer posts will get a higher rating.
- The rating curve is based on the logarithm of ten. The first 10 advantages are the following 100
- Controversial posts that have received both pros and cons will be lower than simply “zaplyusovannyh” posts
How comment sorting works
Randall Munroe from xkcd is behind the idea of Redditovsky best ranking. He wrote a great article about it: reddit's new comment sorting system
You should read this article, in it he very clearly explains the principle of the algorithm. Summarizing it, you can say:
- The hot ranking algorithm is not suitable for comment rating, as it relies heavily on the age of the entry.
- In the comments, you need to put the best comments above, regardless of when they were sent
- The solution for this was found in 1927 by Edwin Wilson and called the “Wilson score interval”, the Wilson interval can be used to “sort by trust”
- When sorting by trust, the total number of votes is presented as a statistical sample of a hypothetical full vote from each - as in a survey of opinions.
- How Not To Sort By Average Rating - well describes the rating algorithm for trust, I highly recommend reading! (a comment of the lane - also there is a good article on Habré )
Examine the comment sorting code.
The trust sorting algorithm is implemented in _sorts.pyx , I also rewrote it to a clean python (and removed some cache optimizations):
#Rewritten code from /r2/r2/lib/db/_sorts.pyx from math import sqrt def _confidence(ups, downs): n = ups + downs if n == 0: return 0 z = 1.0 #1.0 = 85%, 1.6 = 95% phat = float(ups) / n return sqrt(phat+z*z/(2*n)-z*((phat*(1-phat)+z*z/(4*n))/n))/(1+z*z/n) def confidence(ups, downs): if ups + downs == 0: return 0 else: return _confidence(ups, downs) Sorting by trust uses the Wilson interval and the mathematical notation looks like this:
List of parameters for this formula:
- p - the proportion of positive ratings
- n - the total number of votes
- z α / 2 is the (1-α / 2) quantile of the standard normal distribution
Let's summarize the above:
- Sort by trust represents the number of votes as a statistical sample of a hypothetical full vote of each
- Sorting by trust gives a predictable score to a comment that he will receive with 85% probability
- The more votes, the closer the estimated rating comes to the actual
- The Wilson interval is also good for a small number of votes and in cases of extreme probability.
Randall has a great example of how comments are rated:
If a comment has one plus and zero minuses, it has a 100% rating, but since we have too little data, the system will keep it down. But, if he has 10 pros and only one minus, the system can have enough confidence (confidence) to put him above any comment with 40 pluses and 20 minuses, assuming that when he also gets 40 pros - he will have less 20 minuses. And the best part is that even if it is wrong (which happens in 15% of cases), the system will quickly get more data (because the bad comment is at the top, it will be seen and minted) and the comment will go where it should be.
As we see, this algorithm is not affected in any way by the obsolescence of records.
Let's see what it looks like:
As you can see, this sorting is not a matter of how many votes received a comment, but rather how many advantages in relation to the total number of votes and the sample size.
As Evan Miller notes, the Wilson interval can be used not only for rating.
Here are three examples that he cited:
- Detect spam: What percentage of people who see this will mark it as spam?
- Creating a “best” list: What percentage of people who see this will be marked as “best”?
- Creating a list of “most emailed”: what percentage of people who see this page will click on “Email”?
Source: https://habr.com/ru/post/150700/
All Articles