We return to the distribution or how to do the impossible
Prehistory
Not so long ago, namely on June 5, the habrechelope named alan008 asked a question . In order not to force to go for the details, I will give it here:
Help is needed!
For several years, different trackers (mainly c rutracker'a) by different clients (mostly uTorrent) downloaded many gigabytes of various useful content. The downloaded files were subsequently manually moved from one disk to another, uTorrent, respectively, does not see them. Many .torrent files are outdated by themselves (for example, the show was distributed by adding new episodes by replacing the .torrent file).
')
Now the question itself: is there a way to automatically (not manually) establish a correspondence between the .torrent files on a computer and the content scattered across different logical drives of the computer? The goal: to remove unnecessary (irrelevant) .torrent files, and for the most current - to put everything into distribution. Who has any ideas? :)
If necessary (if required), you can place all data files in one directory on one logical drive.
The discussions agreed that if this can be done, then only with pens. This question seemed interesting to me, and after returning from a vacation I took the time to figure it out.
Having spent a total of a week analyzing the format of a .torrent file, searching for a normally working library for parsing it, I started writing a program that would solve the problem raised in the above-mentioned question.
Before you begin, it is worth noting a few points:
- It turned out a lot, but not all.
- The format of the .torrent file will be given only the necessary explanations.
- For people who are sensitive to poor-quality code at times, I ask you to forgive me in advance - I know that much could have been written better, more optimally and more seamlessly.
For those who are interested in what came out of it, technical details and pitfalls - please under the cat.
In this case, there is a great way to solve it - siphon again. But we are not looking for easy ways, and such an option was offered! So, we will solve the problem on the complex - do not download .
Starting to write any program, you must first think of at least the basic algorithm of its work. In our case, the algorithm, in fact, consists of two steps:
- Find and read all .torrent files;
- Find in the heap of files the one that corresponds to the one described in .torrent, and move it to the folder corresponding to the path to .torrent.
To implement my idea, I used C #, but any language that has libraries for reading bencode files and the ability to read the SHA-1 hash is suitable for this.
Well, let's get down to the task.
We are looking for torrents and read them.
After I dealt with the device of .torrent files, I faced the question of parsing the whole miracle. Having reviewed the Internet on this issue, I found several .NET libraries for this case. I stopped my choice on the BencodeLibrary library, which is more or less comprehensible and working out of the box, but later I had to add it a little to fit my needs, but more on that later.
Let's start with the simplest point - reading .torrent.
The structure of a .torrent file is quite simple - it is a bencode dictionary. In this dictionary, we are only interested in a couple with the info key - a block of file descriptions. This is also a dictionary and contains information about the name of files, their size. In addition, as many know, the torrent hashes files not entirely, but in chunks of a certain length, which depends on the size of these files. Information about the size of this piece is also contained in the info dictionary.
To store information from a read file, we will use the following
Torrent class:class Torrent
public class Torrent { public Torrent(string name, List<LostFile> files, int pieceLength, char[] hash, string fileName) { Name = name; Files = files; PieceLength = pieceLength; Hash = hash; FileName= fileName; } public string Name; public int PieceLength; public char[] Hash; public List<LostFile> Files; public string FileName; ... } Here the fields store the following information:
*
Name - the name of the torrent (generally speaking - the name of the folder or the file name)*
Files - the list of files that we will need to look for in the future.*
PieceLength - the size of those pieces, the hash of which we have to count*
Hash - a hash of all files*
FileName - the name of the .torrent file on diskNow it is necessary to focus on the string hash. It is very simple. All files are glued together in one (virtually of course) one after the other, thus forming one BIGGI-TIAL imaginary file. In this imaginary file, take a piece of
PieceLength length, consider the SHA1 hash, put the hash on the line, take the next piece, count the hash, append to the end of the line with the hash of the previous piece. That is, this is the usual concatenation of hashes of all chunks.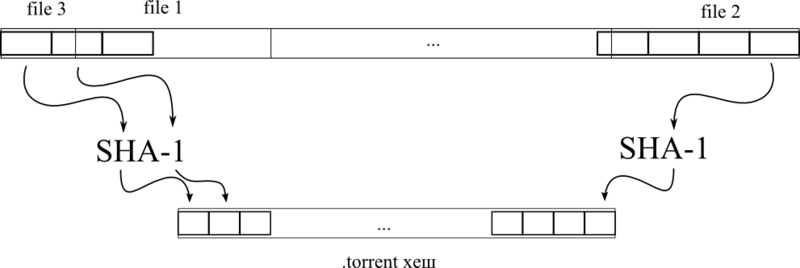
As the attentive reader could notice, the file inside the class is not just a file, but a special data type in which the file is described by a certain
LostFile type LostFile . Here she is:class LostFile
public class LostFile { public LostFile(string name, long length, long beginFrom) { Name = name; Length = length; BeginFrom = beginFrom; } public string Name; public long Length; public long BeginFrom; . . . } Everything is simple here: the name of the file and its size. In addition, this class contains another field -
BeginFrom . It describes the beginning of this file in that BOLUSHOOOOM imaginary file. It is needed to take the correct part of the file to calculate the hash - because the length of the file is very rarely a multiple of the length of the piece.
Having prepared the structures for storing the necessary information, you can start filling them out.
Using the BencodeLibrary library found on the Internet, we read our .torrent file and uproot the info block from it:
List<LostFile> files = new List<LostFile>(); // , BDict torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.UTF8); BDict fileInfo = (BDict)torrent["info"]; Further from this block it is necessary to take data about the name of the torrent, the size of the piece.
string name = ((BString)fileInfo["name"]).Value; int pieceLength = (int)((BInt)fileInfo["piece length"]).Value; There was a problem with reading the hash, the solution of which I don’t really like, but it works. The fact is that by specification all the lines in the .torrent file should be in UFT8. If you read a hash that, according to the specification, is written in the format of a bencode string, as a UTF8 string, then a comparison problem will arise - the hashes of the same pieces will not match. Reading the torrent in the proposed codepage-437 encoding, we get problems with Russian letters in the paths. The way out of this situation, which slowed me down for two days, I found not the best, but working - to read two times in different encodings.
torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437)); char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray(); At this point, we pass the encoding information to the `BencodingUtils.DecodeFile` method as the second parameter. This is exactly the moment when I had to add one method to the library - initially codepage-437 was embedded in the code.
We got to the most interesting point in this part - reading information about files. Torrent files are of two types. These types differ in how many files they describe. When describing only one file, its name and size are written to .torrent.
At first we will sort .torrent with the description of one file.
long Length = ((BInt)fileInfo["length"]).Value; files.Add(new LostFile(name, Length, 0)); // files - Everything is simple - the name of the torrent coincides with the file name. In the case when there are a lot of files in the distribution, then the name of the folder in which they should be put is written in the name field (in fact, it can be anything, but for some reason everyone writes the name of the folder in which these files lay during creation). In addition, a list of files appears that contains information about each file: the path to it and the size. If the size is just an integer, then the file path is a list of strings (directory names), passing through which we will see this file.
This is best illustrated by example. For files
level_1\level_2_1\file_1.txt and level_1\level_2_2\file_2.txt , if we want to distribute them, the name field will contain the name of the top level folder ( "level_1" ), and the path list for one of the files will look like this: {"level_2_1", "file_1.txt"} and {"level_2_2", "file_2.txt"} for another.We for .torrent with several files need to collect the path to each file in one line. In addition, it is necessary to store the beginning of each file in BOLSHOOOOM (not forgotten, right ?!):
BList filesData = (BList)fileInfo["files"]; long begin = 0; foreach (BDict file in filesData) { BList filePaths = (BList)file["path"]; long length = ((BInt)file["length"]).Value; string fullPath = name; foreach (BString partOfPath in filePaths) { fullPath += @"\" + partOfPath.Value; } files.Add(new LostFile(fullPath, length, begin)); // files - begin += length; } It is very important to note that the order of the files in the BIG file can be any, not necessarily alphabetically or in size. But the order of the files in the files list will be exactly the same. This is a key point for understanding the principle of hashing. For example, in the situation depicted in the first figure, the list of files will be as follows:
{"file_3","file_1", ..., "file_2"} . Thus, considering the hash of one file, we know which file will need to be taken next.When we have read and calculated this whole thing, let's create and return a
Torrent instance: new Torrent(name, files, pieceLength, pieces, filename); Now collecting all the reading and parsing of a .torrent file together, we get:
ReadTorrent
static Torrent ReadTorrent(string filename) { List<LostFile> files = new List<LostFile>(); BDict torrent = (BDict)BencodingUtils.DecodeFile(filename); BDict fileInfo = (BDict)torrent["info"]; string name = ((BString)fileInfo["name"]).Value; int pieceLength = (int)((BInt)fileInfo["piece length"]).Value; torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437)); char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray(); if (fileInfo.ContainsKey("files")) // Multifile torrent { BList filesData = (BList)fileInfo["files"]; long begin = 0; foreach (BDict file in filesData) { BList filePaths = (BList)file["path"]; long length = ((BInt)file["length"]).Value; string fullPath = name; foreach (BString partOfPath in filePaths) { fullPath += @"\" + partOfPath.Value; } files.Add(new LostFile(fullPath, length, begin)); begin += length; } } else // Singlefile torrent { long Length = ((BInt)fileInfo["length"]).Value; files.Add(new LostFile(name, Length, 1)); } return new Torrent(name, files, pieceLength, pieces, filename); } Now that we have all the necessary data, we are ready for the most interesting part - the search for our files.
Looking for files
We came close to implementing the second step of our algorithm. For this we will use the
FindFiles method of this type: void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath) {} Here
files is the list of files among which we will search, destinationPath is the path to the destination folder where the found files will be placed.For each file in .torrent we will iterate through all the files from the heap and compare them. Since hash checking is quite expensive, we must first weed out obviously left files. Well, judge for yourself: if I downloaded the discography in .mp3 and moved it, I obviously did not change the file extensions. The name could change, but the extension is unlikely.
FileInfo fileOnDisk = files[j]; if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name)) continue; It is also worth checking the length of the file, but this is doubtful and can sometimes give false positives. Only after we explicitly left files have been screened out by extension, can we proceed to check the hash.
if (!torrent.CheckHash(i, fileOnDisk)) continue; After the check is completed, and we have made sure that the file matches the desired one, we move it to the destination folder with the correct path. Before moving we will naturally check the presence of a directory, and also check whether there is already such a file or not.
copyFile is a variable passed from the form by the user, its purpose, I think, is clear to everyone. FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name); if (!Directory.Exists(fileToMove.DirectoryName)) Directory.CreateDirectory(fileToMove.DirectoryName); if (!fileToMove.Exists) { // - if (copyFile) File.Copy(fileOnDisk.FullName, fileToMove.FullName); else File.Move(fileOnDisk.FullName, fileToMove.FullName); // files.Remove(fileOnDisk); // torrent.Files.RemoveAt(i--); break; // , torrent } There are in the code above three important points for explanation. I'll start with the last two - these lines:
files.Remove(fileOnDisk); torrent.Files.RemoveAt(i--); I found it quite logical to remove already sorted files from consideration, which will allow to somewhat reduce the search execution time. The second line has the construction
.RemoveAt(i--); since the current element is removed from the collection, the pointer must be moved back so that the next element is taken at the next iteration of the loop, and not after one.Now, about the first moment. I know about the presence of
foreach for the list, but when used it is impossible to modify this spikok, that is, we will not be able to delete already unnecessary more elements. So, collecting all the above described in one method, we have:ReadTorrent
public static void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath, bool copyFile) { for (int i = 0; i < torrent.Files.Count; i++)// (LostFile fileInTorrent in torrent.Files) { LostFile fileInTorrent = torrent.Files[i]; for (int j = 0; j < files.Count; j++) { FileInfo fileOnDisk = files[j]; // if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name)) continue; // if (fileOnDisk.Length != fileInTorrent.Length) continue; // if (!torrent.CheckHash(i, fileOnDisk)) continue; // . // FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name); if (!Directory.Exists(fileToMove.DirectoryName)) Directory.CreateDirectory(fileToMove.DirectoryName); if (!fileToMove.Exists) { if (copyFile) File.Copy(fileOnDisk.FullName, fileToMove.FullName); else File.Move(fileOnDisk.FullName, fileToMove.FullName); // files.Remove(fileOnDisk); // torrent.Files.RemoveAt(i--); break; } } } } Here you go! Most delicious.
Hash check
As can be seen from the code above, to verify the hash, we pass the file name on the disk and the file number in the list of torrent files. This is necessary in order not to run a search in the file list, and immediately take it by the number, since it is known (another "+1"
for loop). public class Torrent { public string Name; public int PieceLength; public char[] Hash; public List<LostFile> Files; public string FileName; public bool CheckHash(int index, FileInfo fileOnDisk) {} } Now let's get down to implementing our hash verification method. At this stage, we know the number in the list of torrent files and the path to the file on disk.
LostFile checkingFile = this.Files[index]; if (checkingFile.Length < this.PieceLength * 2 - 1) return false; In principle, we can consider the hash of any file, but let's simplify our task a little. We will only
PieceLength * 2 - 1 with files whose length is greater than or equal to PieceLength * 2 - 1 . Such a restriction will give us the opportunity to isolate at least one piece for verification, which is completely in the file. This approach has several significant advantages:- There is no need to additionally look for adjacent files on the disk;
- The length of the piece for hashing very rarely exceeds 2-4 MB, which gives us another plus - in terms of performance and time, downloading such files is much easier than looking for them on disk.
At this stage we come to the most difficult of all that we had to do - finding the right piece for verification. Let's move away a bit from programming and turn to mathematics, having formulated an auxiliary task.
When a torrent client performs file hashing, it considers the hash in order, but it happens that there is no one or more files. Then the torrent client needs to know which next piece to take and where it will start in the next available file. To calculate these two digits, we will use the following code, in which the variable
firstChunkNumber contains the number of the first piece that is completely contained in this file, and bytesOverhead - the number of bytes from the beginning of the file to the beginning of this piece. For a better understanding of this point, take a look at the explanatory picture after the code. long start = 0; long firstChunkNumber = 0; long bytesOveload = checkingFile.BeginFrom % this.PieceLength; if (bytesOveload == 0) // { start = checkingFile.BeginFrom; firstChunkNumber = checkingFile.BeginFrom / this.PieceLength; } else { firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1; start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom; } 
Answer the question "Why is the number of the piece different for the case when its beginning coincides with the beginning of the file, and for the case when the piece lies inside?" Is proposed independently.
Now, knowing the number of the piece, we must take its hash from the torrent using this design:
char[] hashInTorrent = new char[20]; // 20 - SHA1 Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20); After that, you need to read a piece from the file and calculate its hash:
char[] fileHash = new char[this.PieceLength]; using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open))) { using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider()) { byte[] piece = new byte[this.PieceLength]; fs.BaseStream.Position = start; fs.Read(piece, 0, this.PieceLength); fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray(); } } Well, the most important thing is to check it. For some reason, none of the
Equals() methods that I could find, wanted to work for me, so we check it like this: for (int i = 0; i < fileHash.Length; i++) { if (fileHash[i] != hashInTorrent[i]) return false; } Putting together this creation of the excited brain, we obtain the method of the following content:
Checkhash
public bool CheckHash(int index, FileInfo fileOnDisk) { LostFile checkingFile = this.Files[index]; if (checkingFile.Length < this.PieceLength * 2 - 1) return false; long start = 0; long firstChunkNumber = 0; long bytesOveload = checkingFile.BeginFrom % this.PieceLength; if (bytesOveload == 0) { start = checkingFile.BeginFrom; firstChunkNumber = checkingFile.BeginFrom / this.PieceLength; } else { firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1; start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom; } char[] hashInTorrent = new char[20]; Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20); char[] fileHash = new char[this.PieceLength]; using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open))) { using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider()) { byte[] piece = new byte[this.PieceLength]; fs.BaseStream.Position = start; fs.Read(piece, 0, this.PieceLength); fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray(); } } for (int i = 0; i < fileHash.Length; i++) if (fileHash[i] != hashInTorrent[i]) return false; return true; } On this beautiful note, the story of the methods and algorithms ends, and we turn to the story of the implementation in real life of this creation. It is quite clear that this problem was solved by me not in order to solve it, but in order to implement it. Therefore, I bring my creation to the public, which implements everything described above.
Program
The program is written, as already mentioned in C #. When working is not very whimsical, requires only. NET 2.0. However, there is one restriction on use: it is better to remove the torrent files and the collection from the root of the logical disk. The reason for this restriction is the use of the `SearchOption.AllDirectories` parameter when scanning directories, which leads to a crash when trying to read closed directories like the basket or` System Volume Information` (if knowledgeable people tell you how to get around this, I would be very grateful). Naturally, there are no special restrictions for the destination folder, the main thing is that it fits, and you can write to it, otherwise it will crash with an error (it did not model it, but it is logical).
In the process, after the completion of processing the next file, the result is displayed - the name of the .torrent file on the disk and the number of processed files.
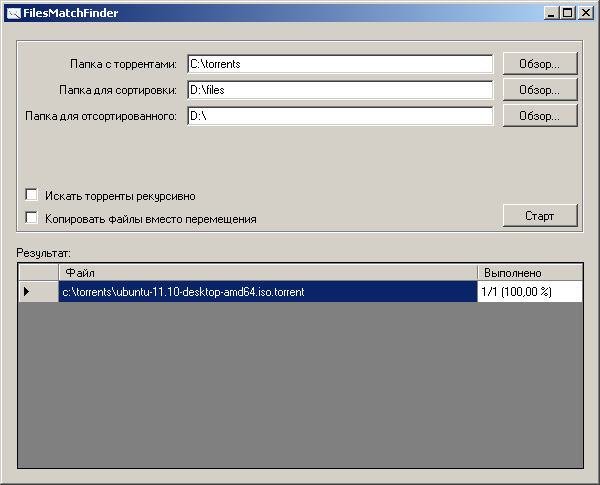
To start a scan, you must select three directories (with .torrent files, with files to sort and a folder for sorted), optionally specify two options and start scanning.
About performance. It is so far low: processing 10 large torrent files took about 5 minutes.
Since the application works in one thread, the interface hangs at runtime, but I'm working on it. I also want to remind you that small files (less than 2 megabytes) will not be moved due to the inability to verify the hash. False alarms are quite likely due to the fact that only one piece is checked with the number
firstChunkNumber . So far, checking all the pieces is too expensive, but there are plans.Do not look for torrents recursively if they are collected in the root of the disk.
Copying may take a long time, so the interface may hang - do not be alarmed.
Since this program was written 4fun, the quality of the code there is a little bit different, but it works for me. This program was not tested, only obvious errors were corrected, so there may be, yes, something to hide, there are hidden bugs. BY USING THIS PROGRAM, YOU USE IT AT YOUR OWN RISK.
You can get the source code on github . Distributed by GPLv2. There is an archive with an executable file. The work requires the Bencode Library, but not the original one, but the one I modified (I have it in the repository , connected by a submodule).
Thanks to everyone who showed patience and read this article to the end. I am glad to hear your questions. All possible assistance in improving the algorithm and, in particular, the code is welcome.
Sources: BitTorrentSpecification .
UPD1. As a result of the discussion, it became clear to me that it would be more correct not to break existing collections by pulling out files for distribution, but on the contrary - to create hardlinks in the right place for distribution to files inside ordered collections (film and discographies, for example). In the future, the program will work that way.
UPD2. If those who used this utility have any other suggestions on the functionality or bug reports, then please leave them on the github in the issue tracker.
Source: https://habr.com/ru/post/150608/
All Articles