Recommended systems: LDA
Last time I talked about the Bayes theorem and gave a simple example - the naive Bayes classifier. This time we will move on to a more complex topic, which develops and continues the work of naive Bayes: we will learn how to highlight topics using the LDA (latent Dirichlet allocation) model, and also apply this to recommender systems.

The LDA model solves the classical text analysis problem: to create a probabilistic model of a large collection of texts (for example, for information retrieval or classification). We already know the naive approach: the hidden variable is the topic, and the words are obtained with a fixed topic independently of the discrete distribution. Similarly, approaches based on clustering work. Let's complicate the model a bit.
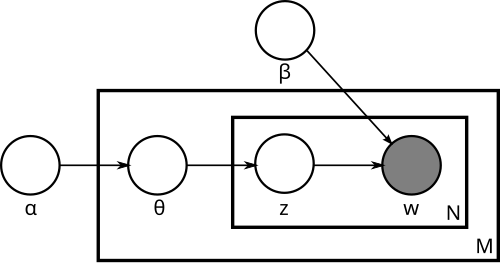
Obviously, one document may have several topics; approaches that cluster documents on topics do not take this into account. LDA is a hierarchical Bayesian model consisting of two levels:
Here is the graph of the model (picture taken from Wikipedia ):
')
Complex models are often easiest to understand this way - let's see how the model will generate a new document:
For simplicity, we fix the number of those k and we will assume that β is just a set of parameters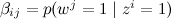 that need to be assessed, and we will not worry about the distribution on N. The joint distribution then looks like this:
that need to be assessed, and we will not worry about the distribution on N. The joint distribution then looks like this:
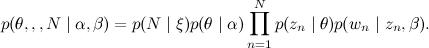
Unlike conventional clustering with a priori Dirichlet distribution or ordinary naive Bayes, we don’t select a cluster here once, and then add words from this cluster, and for each word, first select the theme for the θ distribution, and then we throw the word on this topic .
At the exit after learning the LDA model, we obtain the θ vectors, showing how the topics are distributed in each document, and the β distributions, which words are more likely to be in certain topics. Thus, from the LDA results it is easy to get for each document a list of topics in it, and for each topic a list of words characteristic for it, i.e. an actual topic description. Note: all this learning without a teacher (unsupervised learning), it is not necessary to mark out the texts from the texts!
As for how it all works, I confess honestly - I don’t think that in a brief Habrapost you can easily tell how the conclusion was organized in the initial work about the LDA; it was based on the search for variational approximations to the distribution of the model (we simplify the structure of the model, breaking the bonds, but adding free variables for which we optimize). However, much simpler approaches were soon developed, based on Gibbs sampling; Maybe someday I will return to this topic when I talk about sampling, but now they are too narrow for this field. Let me just leave here the link to MALLET - the most popular and, as far as I can tell, the best ready LDA implementation. MALLET'a you enough for almost all occasions, except that if you want to select topics from the entire Internet entirely - on the cluster MALLET, it seems, does not know how to work.
And I will tell you how LDA can be applied in the recommender system; This method is particularly well suited for situations where “ratings” are not set on a long scale of stars, but simply binary “expressions of approval”, like in Surfingbird. The idea is quite simple: let's consider the user as a document consisting of the products he likes . At the same time, products become “words” for LDA, users - “documents”, and as a result, “topics” of user preferences are highlighted. In addition, you can evaluate which products are most typical for a particular topic — that is, select the product group that is most relevant for the corresponding user group, and also enter from distributions on the topics of distance both on users and on products.
We applied this analysis to the Surfingbird.ru database. and got a lot of interesting topics - it turned out that in almost all cases groups of sites are really distinguished, united by one theme and quite similar to each other. In the pictures below, I drew statistics of words that are often found on the pages of some of the topics obtained with the help of LDA (while LDA itself did not work with the text of the pages, but only with user preferences!); I cut out the links to the pages themselves, just in case.
The LDA model solves the classical text analysis problem: to create a probabilistic model of a large collection of texts (for example, for information retrieval or classification). We already know the naive approach: the hidden variable is the topic, and the words are obtained with a fixed topic independently of the discrete distribution. Similarly, approaches based on clustering work. Let's complicate the model a bit.
Obviously, one document may have several topics; approaches that cluster documents on topics do not take this into account. LDA is a hierarchical Bayesian model consisting of two levels:
- at the first level - a mixture, the components of which correspond to the "themes";
- at the second level, a multinomial variable with the Dirichlet a priori distribution, which specifies the “distribution of themes” in the document.
Here is the graph of the model (picture taken from Wikipedia ):
')
Complex models are often easiest to understand this way - let's see how the model will generate a new document:
- choose the length of the document N (this is not drawn on the graph - it is not that part of the model);
- choose vector
 - the vector of "severity" of each topic in this document
- the vector of "severity" of each topic in this document - for each of the N words w :
- choose a topic
 by distribution
by distribution  ;
; - choose a word
 with probabilities given in β.
with probabilities given in β.
- choose a topic
For simplicity, we fix the number of those k and we will assume that β is just a set of parameters
that need to be assessed, and we will not worry about the distribution on N. The joint distribution then looks like this:Unlike conventional clustering with a priori Dirichlet distribution or ordinary naive Bayes, we don’t select a cluster here once, and then add words from this cluster, and for each word, first select the theme for the θ distribution, and then we throw the word on this topic .
At the exit after learning the LDA model, we obtain the θ vectors, showing how the topics are distributed in each document, and the β distributions, which words are more likely to be in certain topics. Thus, from the LDA results it is easy to get for each document a list of topics in it, and for each topic a list of words characteristic for it, i.e. an actual topic description. Note: all this learning without a teacher (unsupervised learning), it is not necessary to mark out the texts from the texts!
As for how it all works, I confess honestly - I don’t think that in a brief Habrapost you can easily tell how the conclusion was organized in the initial work about the LDA; it was based on the search for variational approximations to the distribution of the model (we simplify the structure of the model, breaking the bonds, but adding free variables for which we optimize). However, much simpler approaches were soon developed, based on Gibbs sampling; Maybe someday I will return to this topic when I talk about sampling, but now they are too narrow for this field. Let me just leave here the link to MALLET - the most popular and, as far as I can tell, the best ready LDA implementation. MALLET'a you enough for almost all occasions, except that if you want to select topics from the entire Internet entirely - on the cluster MALLET, it seems, does not know how to work.
And I will tell you how LDA can be applied in the recommender system; This method is particularly well suited for situations where “ratings” are not set on a long scale of stars, but simply binary “expressions of approval”, like in Surfingbird. The idea is quite simple: let's consider the user as a document consisting of the products he likes . At the same time, products become “words” for LDA, users - “documents”, and as a result, “topics” of user preferences are highlighted. In addition, you can evaluate which products are most typical for a particular topic — that is, select the product group that is most relevant for the corresponding user group, and also enter from distributions on the topics of distance both on users and on products.
We applied this analysis to the Surfingbird.ru database. and got a lot of interesting topics - it turned out that in almost all cases groups of sites are really distinguished, united by one theme and quite similar to each other. In the pictures below, I drew statistics of words that are often found on the pages of some of the topics obtained with the help of LDA (while LDA itself did not work with the text of the pages, but only with user preferences!); I cut out the links to the pages themselves, just in case.
 |  |  |
 |  |  |
Source: https://habr.com/ru/post/150607/
All Articles