Introduction to frameworks (Part 2)

Part 1
Second generation frameworks
This generation is an intermediate level of automated testing frameworks, among them there can be quite simple frameworks, and they can be quite well designed. Such frameworks should be considered in the case when the support of autotests is an important factor. A good understanding of this generation of frameworks is important, since third-generation frameworks are based on the concepts of frameworks of this level.Second-generation frameworks include data-oriented frameworks and frameworks using functional decomposition. Most frameworks of this level are hybrids and use both approaches, but since only one of them can be used, these approaches will be considered independently of each other.
Functional decomposition
Functional decomposition in a broad sense is the process of creating modular components (user-defined functions) in such a way that automated testing scripts can be created by combining these components.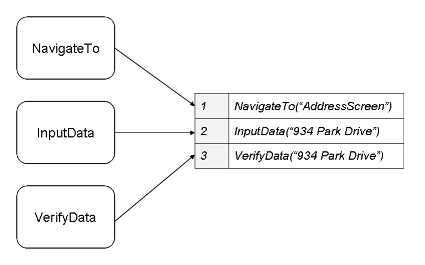
Modularity is often used to implement functionality tests for the application under test, but there are other user-defined functions that can be created. These functions include:
- Utilities - here you can include functions related to the main mechanisms of the framework or providing access to the basic functionality of the application under test. For example, the function responsible for logging into an application can be viewed as a utility function. These functions can be determined from requirements or based on “manual” test cases related to groups of tests intended for automation.
- Navigation functions - in most applications there are several main areas, the transition between which during testing is carried out repeatedly. The implementation of transitions is a basic component and can be easily determined at the very beginning of the automation process.
- Error handling functions are created to deal with unexpected situations that may arise during testing.
- All other functions are not in any of the categories listed above.
The advantages of functional decomposition
- Increase code reuse - after the application of functional decomposition the volume of reuse is greatly increased, since the code sections combined into functions can be accessed for calls by various tests. The redundancy of the source code can be reduced both for all tests of one application, and for tests of different applications, depending on the level of abstraction of functions created. With the increase in reuse volumes, the ease of support grows.
- Script independence - although a framework with functional decomposition may use external components, individual tests are not reused. This allows you to implement reuse while maintaining the independence of the scripts.
- Early development of scripts - in some cases, functional decomposition allows you to start developing automated tests even before the application is ready. Using information obtained from requirements or other documentation, a component template can be created, which can then be used to develop autotests using the top-down approach.
- Ease of reading - when dividing scripts into logical components, autotests are easier to maintain, since it is enough just to visually determine which result should be obtained when the script is applied.
- Standardization growth - with an increase in the number of reusable components standardization grows, which helps in the development of autotests, as the number of intuitive actions in writing code and its support decreases.
- Simple implementation of error handling - local solutions for error handling in different scripts create difficulties when adding and maintaining. With the use of reusable components, error handling can be implemented, spanning multiple scripts. Ultimately, this will improve the efficiency of automatic tests.
Disadvantages of functional decomposition
- It requires technical knowledge - after the automated testing framework begins to use more technical solutions than the first generation framework, more technically competent specialists are required for its design, development and support. This position is true for a framework that uses functional decomposition.
- Less effect from intuitive actions — to effectively use an advanced framework, you need to rely less on intuition and more on standards. Standardization is a positive result of functional decomposition, but at the same time it creates the need to provide sources of data on standards, to understand standards and to be able to apply them. Most likely, to familiarize yourself with the capabilities of the framework, you will need documentation describing them.
- The support process becomes more complex - along with the increasing complexity of the framework, the complexity of autotest support grows. When using linear scripts, fixes affect only the autotest that has stopped working. Although this may lead to redundancy (since one change to the application under test can lead to failures at once in several autotests), the use of linear scripts helps to make maintenance less complicated. When using functional decomposition, support is often required both for the framework itself and for the scripts using it. Although this may reduce the amount of support activities, it also increases the complexity of servicing autotests.
Data orientation
The frameworks created using this approach are similar to the first-generation frameworks in that the majority of components used in scripts are mainly within these scenarios. The difference is in the way of working with data. Data-oriented frameworks usually store information in sources that are external to scripts. Using parameterization of the fields for entering application data and binding external data to the corresponding parameters, test data is not placed inside the script itself.Below is an example of a linear script.
The data-oriented version of this script will use information from an external source (spreadsheet, database, XML file, etc.), something like the one shown below.
- Input “John” into Username textbox
- Input “JPass” into Password textbox
- Click Login button
- If “Welcome Screen” exists then
- Pass the test
- Else
- Fail the test
- End if
| NameParameter | PasswordParameter |
|---|---|
| John | Jpass |
| Sue | SPass |
| Randy | RPass |
| Trina | TPass |
Note that the data has been removed from the script and replaced with parameters.
- Open data table
- Input <NameParameter> in Username textbox
- Input <PasswordParameter> into Password textbox
- Click Login button
- If “Welcome Screen” exists then
- Pass the test
- Else
- Fail the test
- End if
- Close Data Table
This approach allows you to use the same code on different data. Data orientation is often viewed as a technique contrary to the frameworks, but its use can help reuse the same script using different information. This approach does not solve many of the problems inherent in linear scenarios, but it can be useful.
')
The benefits of data orientation
- Reuse - this approach provides a relatively simple way to reuse automated tests. A piece of code can be used with various data, providing the ability to perform many automated tests with minimization of the script creation phase.
- Simplicity of implementation - the simplicity is that only minimal updates of existing scripts are required, often consisting only of parameterization and the conclusion of the body of an already existing test inside the loop.
Lack of data orientation
The disadvantages of this approach include the following aspects inherited from linear scripts (see Part 1 ):- Redundancy.
- One dimensionality
- Difficult to read.
- Requires a higher level of knowledge to support.
Source: https://habr.com/ru/post/150603/
All Articles