Feelings that were confirmed by numbers
For a long time I was worried about articles on the Internet in which an attempt was made on the basis of checking small projects to judge the benefits of using static code analyzers.
Many of the articles I've read have made this assumption. If there are 2 errors in the project with the size of N lines of code, then in the full-size project with the size of N * 100 lines, you can find only 200 errors. And from this it is concluded that static analysis is certainly good, but not remarkable. Too few bugs. It is better to develop other methods for finding defects.
There are two main reasons why people test the analyzer on small projects. First, a large working draft is not so easy to check. It is necessary to configure something, to prescribe something somewhere, to exclude some libraries from the scan and so on. Naturally, you do not want to do all this. There is a desire to quickly check something, and not to bother with the settings. Secondly, a large number of diagnostic messages will be received on a large project. And again you do not want to spend a lot of time analyzing them. Much easier to learn is to take a smaller project.
As a result, a person does not touch a big project that he is working on, but takes something small. For example, it could be his old course project or a small open project with GitHub.
')
He checks this project and does linear interpolation, how many errors he can find in his big project. And then writes an article about the research.
At first glance, such studies look right and useful. But I was sure that it was not.
The first shortcoming of all these studies is obvious. They forget that a working debugged version of a project is being taken. Many of the errors that could be quickly found by static analysis were searched slowly and sadly. They were found during testing or after user complaints. That is, it is forgotten that static analysis is a tool of constant, rather than one-time use. After all, programmers regularly look at Warnings, issued by the compiler, and not once a year.
With the second shortcoming in the research, everything is more complicated and interesting. I had a clear feeling that it is impossible to evaluate small and large projects equally. Let the student write a good project for a term paper containing 5,000 lines of code in 5 days. I am sure that in 500 days he will not be able to write a good commercial application with a capacity of 100,000 lines of code. It will prevent the growth of complexity. The more a program becomes, the more difficult it is to add new functionality to it, the more it is required to test it and more to mess with errors.
In general, the feeling was, but I could not formulate it at all. Suddenly, one of the staff members came to my rescue. While studying Steve McConnell’s The Perfect Code, he noticed an interesting tablet in it. And I forgot about her. This plate puts everything right in its place!
Of course, considering small projects, it is incorrect to estimate the number of errors in large ones! They have different density of errors!
The larger the project, the more errors per 1000 lines of code it contains. Take a look at this wonderful table:

Table 1. Project size and typical error density. The book lists data sources: "Program Quality and Programmer Productivity" (Jones, 1977), "Estimating Software Costs" (Jones, 1998).
To make it easier to perceive the data, we will construct graphs.
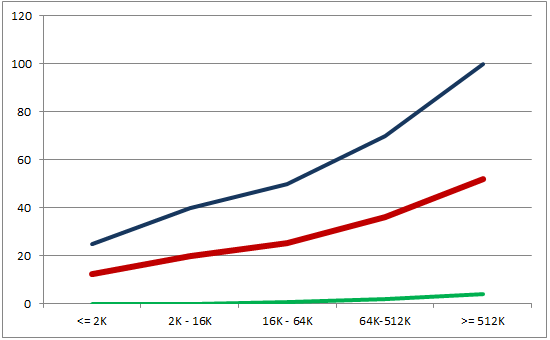
Chart 1. Typical density of errors in the project. Blue is the maximum amount. Red is the average. Green is the least.
I think, considering these graphs, it becomes clear that the dependence is not linear. The larger the project, the easier it is to make a mistake.
Of course, the static analyzer does not detect all errors. However, the larger the project, the more effective it is. And even more effective if used regularly.
By the way, in a small project there can be no errors at all. Or they will be just a couple. In this case, you can come to a completely wrong conclusion. Therefore, I highly recommend that you try various tools for finding errors on real work projects.
Yes, it is more difficult, but you get the right idea about the possibilities. For example, as one of the authors of PVS-Studio , I can promise that we are trying to help everyone who comes to us. If in the process of learning PVS-Studio something will not work, write to us. Often, many problems can be solved by setting the instrument correctly.
PS
I invite you to join my @Code_Analysis twitter or the Reddit community . In them I regularly publish links to interesting articles on topics: C / C ++, static code analysis, optimization, and other interesting things about programming. Articles and ours, and others. And then they kicked me out everywhere, except for "I am promoting".
Many of the articles I've read have made this assumption. If there are 2 errors in the project with the size of N lines of code, then in the full-size project with the size of N * 100 lines, you can find only 200 errors. And from this it is concluded that static analysis is certainly good, but not remarkable. Too few bugs. It is better to develop other methods for finding defects.
There are two main reasons why people test the analyzer on small projects. First, a large working draft is not so easy to check. It is necessary to configure something, to prescribe something somewhere, to exclude some libraries from the scan and so on. Naturally, you do not want to do all this. There is a desire to quickly check something, and not to bother with the settings. Secondly, a large number of diagnostic messages will be received on a large project. And again you do not want to spend a lot of time analyzing them. Much easier to learn is to take a smaller project.
As a result, a person does not touch a big project that he is working on, but takes something small. For example, it could be his old course project or a small open project with GitHub.
')
He checks this project and does linear interpolation, how many errors he can find in his big project. And then writes an article about the research.
At first glance, such studies look right and useful. But I was sure that it was not.
The first shortcoming of all these studies is obvious. They forget that a working debugged version of a project is being taken. Many of the errors that could be quickly found by static analysis were searched slowly and sadly. They were found during testing or after user complaints. That is, it is forgotten that static analysis is a tool of constant, rather than one-time use. After all, programmers regularly look at Warnings, issued by the compiler, and not once a year.
With the second shortcoming in the research, everything is more complicated and interesting. I had a clear feeling that it is impossible to evaluate small and large projects equally. Let the student write a good project for a term paper containing 5,000 lines of code in 5 days. I am sure that in 500 days he will not be able to write a good commercial application with a capacity of 100,000 lines of code. It will prevent the growth of complexity. The more a program becomes, the more difficult it is to add new functionality to it, the more it is required to test it and more to mess with errors.
In general, the feeling was, but I could not formulate it at all. Suddenly, one of the staff members came to my rescue. While studying Steve McConnell’s The Perfect Code, he noticed an interesting tablet in it. And I forgot about her. This plate puts everything right in its place!
Of course, considering small projects, it is incorrect to estimate the number of errors in large ones! They have different density of errors!
The larger the project, the more errors per 1000 lines of code it contains. Take a look at this wonderful table:
Table 1. Project size and typical error density. The book lists data sources: "Program Quality and Programmer Productivity" (Jones, 1977), "Estimating Software Costs" (Jones, 1998).
To make it easier to perceive the data, we will construct graphs.
Chart 1. Typical density of errors in the project. Blue is the maximum amount. Red is the average. Green is the least.
I think, considering these graphs, it becomes clear that the dependence is not linear. The larger the project, the easier it is to make a mistake.
Of course, the static analyzer does not detect all errors. However, the larger the project, the more effective it is. And even more effective if used regularly.
By the way, in a small project there can be no errors at all. Or they will be just a couple. In this case, you can come to a completely wrong conclusion. Therefore, I highly recommend that you try various tools for finding errors on real work projects.
Yes, it is more difficult, but you get the right idea about the possibilities. For example, as one of the authors of PVS-Studio , I can promise that we are trying to help everyone who comes to us. If in the process of learning PVS-Studio something will not work, write to us. Often, many problems can be solved by setting the instrument correctly.
PS
I invite you to join my @Code_Analysis twitter or the Reddit community . In them I regularly publish links to interesting articles on topics: C / C ++, static code analysis, optimization, and other interesting things about programming. Articles and ours, and others. And then they kicked me out everywhere, except for "I am promoting".
Source: https://habr.com/ru/post/150539/
All Articles