Newbie Compiler Manual
David Drysdale , Beginner's guide to linkers ( http://www.lurklurk.org/linkers/linkers.html ).
The purpose of this article is to help C and C ++ programmers understand the essence of what the linker does. Over the past few years, I explained this to a large number of colleagues and finally decided that it was time to transfer this material to paper so that it became more accessible (and so I did not have to explain it again). [Update in March 2009: added additional information about layout features in Windows, as well as a more detailed rule for one definition (one-definition rule).
A typical example of why people turned to me for help is the following layout error:
If your reaction is 'surely forgot extern "C"', then you most likely know everything that is given in this article.
This chapter is a brief reminder of the various components of a C file. If everything in the listing below makes sense to you, then most likely you can skip this chapter and go straight to the next one .
')
First you need to understand the difference between the declaration and the definition. The definition associates a name with an implementation, which can be either code or data:
The declaration tells the compiler that the definition of a function or variable (with a specific name) exists elsewhere in the program, probably in another C file. (Note that the definition is also an ad — in fact, this is an ad in which the “other place” of the program coincides with the current one).
For variables, there are two kinds of definitions:
In this case, the term “available” means “you can refer to the name associated with the variable at the moment of definition”.
There are a couple of special cases that from the first time do not seem obvious:
It is worth noting that, by defining a static function, the number of places from which this function can be accessed by name is simply reduced.
For global and local variables, we can distinguish between a variable initialized or not, i.e. whether the space allocated for a variable in memory will be filled with a specific value.
Finally, we can store information in memory that is dynamically allocated by
Summing up:
Probably the easier way to learn is to simply look at the sample program.
The C compiler’s job is to convert text that is (usually) human-readable to something the computer understands. At the output, the compiler produces an object file . On UNIX platforms, these files usually have the suffix .o; on Windows, the .obj suffix. The contents of the object file are essentially two things:
The code and data, in this case, will have names associated with them — the names of the functions or variables with which they are associated.
Object code is a sequence of (appropriately composed) machine instructions that correspond to C instructions written by a programmer: all these
No matter where the code refers to a variable or function, the compiler allows this only if it has seen the declaration of this variable or function before. An announcement is a promise that a definition exists somewhere else in the program.
Job linker check these promises. However, what does the compiler do with all these promises when it generates an object file?
Essentially, the compiler leaves empty spaces. An empty space (link) has a name, but the value corresponding to this name is not yet known.
Given this, we can portray the object file corresponding to the program above , as follows:
So far we have considered everything at a high level. However, it is useful to see how this works in practice. The main tool for us will be the
Let's see what gives
The result may look slightly different on different platforms (refer to
You can also see characters that are not part of the original C code. We will not focus our attention on this, since this is usually part of the internal compiler mechanism, so that your program can still be put together.
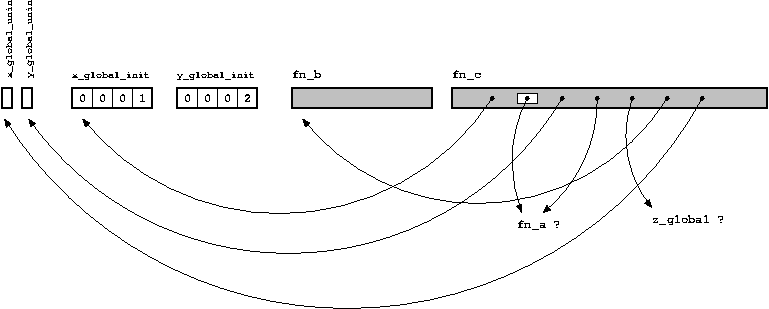
Earlier, we mentioned that the declaration of a function or variable is a promise to the compiler, that somewhere else in the program there is a definition of this function or variable, and that the work of the linker is to fulfill this promise. Looking at the object file diagram , we can describe this process as “filling in empty places”.
We illustrate this with an example, considering another C file in addition to what was mentioned above .
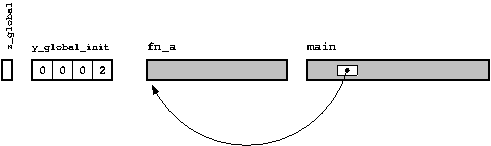
From both diagrams, we can see that all points can be connected (if not, the linker would give an error message). Every thing has its place, and every place has its own thing. Also, the linker can fill all empty spaces as shown here (on UNIX systems, the linking process is usually called with the

As with object files , we can use
It contains the characters of both object files and all undefined links have disappeared. The characters are reordered so that similar types are found together. There are also a few add-ons to help the OS deal with such a thing as an executable file.
There is a sufficient number of complex parts that obstruct the conclusion, but if you drop everything that begins with an underscore, it will become much easier.
In the previous chapter, it was mentioned that the linker gives an error message if it cannot find a definition for the character to which the link was found. And what happens if two definitions are found for a symbol at the time of composition?
In C ++, the solution is straightforward. A language has a limitation known as the rule of one definition , which states that there must be only one definition for each character occurring at the time of composition, no more, no less. (The corresponding chapter of the C ++ standard is 3.2, which also mentions some exceptions, which we will discuss a little later .)
For C, things are less obvious. There must be exactly one definition for any function and an initialized global variable, but the definition of a non-initialized variable can be interpreted as a preliminary definition . The C language thus allows (or at least does not prohibit) different source files to contain a preliminary definition of the same object.
However, linkers should be able to manage with other languages besides C and C ++, for which the rule of one definition is not necessarily followed. For example, it is normal for Fortran to have a copy of each global variable in each file that references it. The linker then needs to remove duplicates by selecting one copy (the largest representative, if they differ in size) and discard all the others. This model is sometimes called the “generic layout” model because of the COMMON (generic) Fortran language.
As a result, it is quite common for UNIX compilers not to swear for the presence of duplicate characters, at least if they are duplicate characters of uninitialized global variables (this layout model is sometimes called a “weak link model”) . def model. More successful suggestions are welcome]). If this worries you (probably should be worried), refer to the documentation of your linker to find the -
Now that the linker has made an executable file, assigning a suitable definition to each symbol reference, you can make a short pause to understand what the operating system does when you start the program for execution.
Running the program of course entails the execution of machine code, i.e. The OS should obviously transfer the machine code of the executable file from the hard disk to the operational memory, from where the CPU can pick it up. These portions are called a code segment (code segment or text segment).
Code without data is useless by itself. Therefore, all global variables also need a place in the computer's memory. However, there is a difference between initialized and uninitialized global variables. Initialized variables have certain starting values that must also be stored in object and executable files. When the program is launched at the start, the OS copies these values into the virtual space of the program, into a data segment.
For uninitialized OS variables, it can be assumed that they all have 0 as the initial value, i.e. There is no need to copy any values. A chunk of memory that is initialized with zeros is known as the bss segment.
This means that space for global variables can be allotted in an executable file stored on disk; for initialized variables, their initial values should be saved, but for uninitialized ones, you only need to keep their size.
As you can see, so far in all the arguments about object files and linker, we have only been talking about global variables; however, we did not mention local variables and dynamically occupied memory mentioned earlier .
This data does not require the intervention of the linker, because the time of their life begins and ends during the execution of the program - much later than the linker has already done his job. However, for the sake of completeness, we briefly indicate that:
For completeness, it is worth adding what the memory space of the process being performed looks like. Since the heap and the stack can change their sizes dynamically, the fact that the stack grows in one direction is quite common, and the heap is reversed. Thus, the program will generate an error of lack of free memory only if the stack and the heap meet somewhere in the middle (in this case, the memory space of the program will really be filled).
Now that we’ve covered the basics of what the linker does, we can dive into the description of more complex parts — roughly in the chronological order they were added to the linker.
The main observation that affects the linker’s functions is the following: if a number of different programs do about the same things (output to the screen, read files from a hard disk, etc.), then obviously it makes sense to isolate this code in a certain place and give it to others programs use it.
One possible solution would be to use the same object files, but it would be much more convenient to keep the entire collection of ... object files in one easily accessible place: a library .
Technical digression: This chapter completely omits the important property of the linker: relocation. Different programs have different sizes, i.e. if the shared library is mapped into the address space of various programs, it will have different addresses.This in turn means that all functions and variables in the library will be in different places. Now, if all references to addresses are relative (“value +1020 bytes from here”) rather than absolute (“value in 0x102218BF”), then this is not a problem, but this is not always the case. In such cases, all absolute addresses need to add a suitable offset - this is relocation . I’m not going to return to this topic again, but I’ll add that since it’s almost always hidden from a C / C ++ programmer, it’s very rare for layout problems to be caused by redirection difficulties.
The simplest embodiment of the library is the static library. In the previous chapter it was mentioned that you can share (share) the code simply by reusing the object files; this is the essence of static libraries.
On UNIX systems, the command to build a static library is usually ar , and the library file, which is obtained, has the extension * .a. Also, these files usually have the prefix “lib” in their name and they are passed to the linker with the "-l" option followed by the library name without the prefix and extension (i.e., "-lfred" will pick up the file "libfred.a").
(In the past, a program called
In Windows, static libraries have an extension
As the linker iterates over the collection of object files to merge them together, it maintains a list of characters that cannot be implemented yet. Once all the explicitly specified object files are processed, the linker now has a new place to search for characters that remain in the list — in the library. If an unrealized character is defined in one of the library objects, then the object is added, just as if it were added to the list of object files by the user, and the layout continues.
Pay attention to the granularity of what is added from the library: if you need to define a certain character, then the whole objectcontaining the definition of the character will be included. This means that this process can be either a step forward or a step back — a newly added object can either resolve an undefined link or bring in a whole collection of new unresolved links.
Another important detail is the order of events; libraries are attracted only when the normal layout is complete, and they are processed in order from left to right. This means that if the object retrieved from the library last requires a symbol from the library that was previously in the line of the build command, then the linker will not find it automatically.
We give an example to clarify the situation; suppose we have the following object files and a build command line that contains
Once the linker has processed
Linker is still dealing with
Here is about the same and linker includes
Notice that the situation changes somewhat, if we
(By the way, this example has a cyclical dependency between libraries
For popular libraries such as the standard C library (usually
A less obvious drawback is that in a statically linked program, the code is fixed forever. If someone finds and corrects a bug in
To get rid of these and other problems, dynamically shared libraries were presented (usually they have an extension
All this boils down to the fact that if the linker detects that the definition of a particular symbol is in a shared library, then it does not include this definition in the final executable file. Instead, the linker records the name of the symbol and the library from which the symbol is supposed to appear.
When a program is called for execution, the OS takes care that the remaining parts of the build process are completed on time before the program starts. Before a function is called
This means that no executable file contains a copy of the code
There is another big difference between how dynamic libraries work compared to static libraries and this is manifested in the granularity of the layout. If a particular symbol is taken from a specific dynamic library (say
We formulate differently, shared libraries themselves are obtained as the result of the linker's work (and not as the formation of a large heap of objects, as it does
So by the way, another useful tool is this
The reason for the greater granularity is that modern operating systems are intelligent enough to allow you to do more than just save duplicate items on disk than static libraries suffer. Different executable processes that use the same shared library can also share a code segment (but not a data segment or bss segment — for example, two different processes can be found in different places when used, say,
Despite the fact that the general principles of shared libraries are about the same on both Unix and Windows platforms, there are still a few details that beginners can get.
There are three ways to export the symbol and the Windows DLL (and all these three methods can be mixed in the same library).
As soon as C ++ is connected to this jumble, the first of these options becomes the simplest, since in this case the compiler undertakes to take care of decorating the names
We come to the second difficulty with the Windows libraries: information about exported symbols that the linker must associate with other symbols is not contained in itself
To make it even more confusing, the extension is
In fact, there are a number of different files that can relate in any way to the Windows libraries. As well as
This is a big difference to Unix, where almost all the information contained in these all additional files is simply added to the library itself.
To do this, declare the symbol as __declspec (dllimport) in the source code like this:
At the same time, an individual declaration of functions or global variables in one header file is a good programming tone in C. This leads to some rebus: the code in the DLL containing the definition of the function / variable must export the character, but any other code using the DLL must import the character.
The standard way out of this situation is to use preprocessor macros.
The source file in the DLL that defines the function and variable ensures that the preprocessor variable is
For most systems, this is not a problem. Executable files depend on high-level libraries, high-level libraries depend on low-level libraries, and everything is arranged in reverse order — first low-level libraries, then high, and then the executable file, which depends on all the others.
However, if there is a cyclic relationship between the binaries then everything gets a bit more complicated. If it
Windows provided a workaround similar to the following.
But it is undoubtedly better to reorganize the libraries in such a way as to avoid any cyclic dependencies ...
C ++ offers a number of additional features beyond what is available in C, and some of these features affect the work of the linker. This was not always the case - the first C ++ implementations appeared as an external interface to the C compiler, so there was no need for compatibility of the linker’s work. Over time, however, more advanced features of the language were added, so that the linker already had to be changed to support them.
The first difference in C ++ is that functions can be overloaded, that is, functions with the same name can exist at the same time, but with different types accepted (with different function signatures ):
This state of affairs definitely makes the linker’s work harder: if any code accesses a function
The solution to this problem is called name decoration (name mangling), because all the information about the signature of the function is translated (to mangle = distort, deform, comment ) in a text form that becomes the actual symbol name from the layout perspective. Different signatures are translated into different names. Thus, the problem of uniqueness of names is solved.
I'm not going to go into the details of the decorating schemes used (which also differ from platform to platform), but a quick glance at the object file corresponding to the code above will give an idea of how to understand all this (remember
Here we see three functions
It is also worth noting that there is usually a way to convert between names visible to the programmer and names visible to the linker. It can be a separate program (for example,
The area where decoration schemes are most often made to err is located at the intersection of C and C ++. All characters produced by the C ++ compiler are decorated; all the characters produced by the C compiler look the same as in the source code. To get around this, the C ++ language allows you to put
Returning to the example at the very beginning of the article, you can easily notice that there is a rather high probability that someone forgot to use
The great clue is that the error message contains the signature of the function - it is not just a message that was
By the way, notice that the declaration is
The next C ++ property that goes beyond C, which affects the operation of the linker, is the existence of object constructors . A constructor is a piece of code that sets the initial state of an object. In essence, his work is conceptually equivalent to initializing the value of a variable, but with the important difference that we are talking about arbitrary code fragments.
Recall from the first chapter that global variables can begin their existence already with a certain value. In C, the construction of the initial value of such a global variable is a simple matter: a certain value is simply copied from the data segment of the executable file to the appropriate place in the program's memory that is about to be executed.
In C ++, the initialization process can be much more complicated than just copying fixed values; all code in various constructors across the entire class hierarchy must be executed before the program itself actually starts.
To cope with this, the compiler places some additional information in the object file for each C ++ file; namely, this is a list of constructors that should be called for a specific file. During linking, the linker merges all of these lists into one large list, and also places the code that passes through the entire list, invoking the constructors of all global objects.
Note that the orderin which constructors of global objects are called not defined - it is completely at the mercy of what the linker intends to do. (See Scott Myers Effective C ++ for further details - note 47 in the second edition , note 4 in the third edition )
We can follow these lists, again by resorting to help
For this code ( not decorated) the output
As usual, we can see a bunch of different things here, but one of them is most interesting for us are records with class W (which means “weak” symbol) and also records with the name of a section like ".gnu.linkonce. t. stuff ". These are markers for constructors of global objects and we see that the corresponding “Name” field shows what we actually could expect there - each of the two designers is involved.
Earlier, we gave an example with three different implementations of a function
C ++ introduces the concept of a template (templates), which allows you to use the code below for all cases at once. We can create a header file
and include this file in the source file to try out the template function:
This C ++ code uses
Each of these different instances generates a different machine code. Thus, at the time when the program is finalized, the compiler and the linker must ensure that the code of each instance of the template used is included in the program (and no unused instance of the template is included, so as not to exaggerate the size of the program).
How is this done? There are usually two ways of doing things: either thinning out the repetitive instances or postponing the instances to the build stage (I usually call these approaches the reasonable way and the Sun way).
The method of thinning repetitive instances implies that each object file contains the code of all the patterns encountered. For example, for the file above, the contents of the object file look like this:
And we see the presence of both instances
Both definitions are marked as weak characters , which means that the linker, when creating the final executable file, can throw out all the repeated instances of the same template and leave only one (and if it considers it necessary, then it can check whether all the repeated instances of the template are displayed in the same code). The biggest disadvantage in this approach is the increase in the size of each individual object file.
Another approach (which is used in Solaris C ++) is not to include template definitions in object files in general, but to mark them as undefined characters. When it comes to the build stage, the linker can collect all the undefined characters that actually belong to the template instances, and then generate the machine code for each of them.
This definitely reduces the size of each object file, but the disadvantage of this approach is that the linker should keep track of where the source code is and should be able to run the C ++ compiler during linking (which can slow down the whole process)
The last feature we discuss here is the dynamic loading of shared libraries. In the previous chapter, we saw how the use of shared libraries postpones the final layout until the program itself starts. In modern operating systems, this is even possible at later stages.
This is done by a pair of system calls
Of course, characters from a dynamically loaded library cannot have a name. However, this is simply solved, as well as other programmer problems are solved by adding an additional level of workarounds. In this case, a pointer to the character space is used. Call
The dynamic loading process is fairly straightforward, but how does it interact with various C ++ features that affect the entire behavior of the linker?
The first observation concerns the decoration of names. When called
Since the decorating process can vary from platform to platform and from compiler to compiler, this means that it is almost impossible to dynamically find a C ++ symbol by a universal method. Even if you work with only one compiler and delve into its inner world, there are other problems - besides simple C-like functions, there are a lot of other things (virtual method tables and the like) that need to be taken care of.
Summarizing the above, we note the following: it is usually better to have one prisoner at the
The compiler can easily deal with the constructors of global objects in the library being loaded
And in conclusion, we add that dynamic loading copes well with the “thinning out of repeated instances”, if we are talking about instantiating templates; and everything looks ambiguous with “postponing instantiation”, since the “build stage” comes after the program is already running (and quite likely on another machine that does not store the source code). Refer to the compiler and linker documentation to find a way out of this situation.
In this article, many details were intentionally omitted on how the linker works, because I believe that the content of the written covers 95% of the everyday problems that the programmer has to deal with when building his program.
If you want to know more, you can read the information from the links below:
Many thanks to Mike Capp and Ed Wilson for useful suggestions about this page.
Copyright © 2004-2005,2009-2010 David Drysdale
Permission is given by the Free Software Foundation; Front Cover Texts, with Back Cover Texts. A copy of the license is available here .
The purpose of this article is to help C and C ++ programmers understand the essence of what the linker does. Over the past few years, I explained this to a large number of colleagues and finally decided that it was time to transfer this material to paper so that it became more accessible (and so I did not have to explain it again). [Update in March 2009: added additional information about layout features in Windows, as well as a more detailed rule for one definition (one-definition rule).
A typical example of why people turned to me for help is the following layout error:
g++ -o test1 test1a.o test1b.o test1a.o(.text+0x18): In function `main': : undefined reference to `findmax(int, int)' collect2: ld returned 1 exit status If your reaction is 'surely forgot extern "C"', then you most likely know everything that is given in this article.
Content
- Definitions: what is in the C file?
- What makes the C compiler
- What the linker does: part 1
- What does the operating system do
- What the linker does: part 2
- C ++ to complete the picture
- Dynamically loadable libraries
- Additionally
Definitions: what is in the C file?
This chapter is a brief reminder of the various components of a C file. If everything in the listing below makes sense to you, then most likely you can skip this chapter and go straight to the next one .
')
First you need to understand the difference between the declaration and the definition. The definition associates a name with an implementation, which can be either code or data:
- Defining a variable causes the compiler to reserve a certain area of memory, possibly setting it to some specific value.
- The function definition causes the compiler to generate code for this function.
The declaration tells the compiler that the definition of a function or variable (with a specific name) exists elsewhere in the program, probably in another C file. (Note that the definition is also an ad — in fact, this is an ad in which the “other place” of the program coincides with the current one).
For variables, there are two kinds of definitions:
- global variables that exist throughout the program’s life cycle (“static allocation”) and which are available in various functions;
- local variables that exist only within a certain executable function (“local location”) and which are available only within that function itself.
In this case, the term “available” means “you can refer to the name associated with the variable at the moment of definition”.
There are a couple of special cases that from the first time do not seem obvious:
- static local variables are actually global because they exist throughout the life of the program, even if they are visible only within a single function.
- static global variables are also global with the only difference that they are available only within the same file where they are defined.
It is worth noting that, by defining a static function, the number of places from which this function can be accessed by name is simply reduced.
For global and local variables, we can distinguish between a variable initialized or not, i.e. whether the space allocated for a variable in memory will be filled with a specific value.
Finally, we can store information in memory that is dynamically allocated by
malloc or new . In this case, it is not possible to refer to the allocated memory by name, so you must use pointers - named variables that contain the address of the unnamed memory area. This area of memory can also be freed with free or delete . In this case, we are dealing with a “dynamic allocation”.Summing up:
| Code | Data | |||||
| Global | Local | Dynamic | ||||
| Initiate lisor the bathrooms | Noninitiate lisor the bathrooms | Initiate lisor the bathrooms | Noninitiate lisor the bathrooms | |||
| Announce perception | int fn(int x); | extern int x; | extern int x; | N / A | N / A | N / A |
| Define perception | int fn(int x) { ... } | int x = 1;(scope - file) | int x;(scope - file) | int x = 1;(scope is a function) | int x;(scope is a function) | int* p = malloc(sizeof(int)); |
Probably the easier way to learn is to simply look at the sample program.
/* */ int x_global_uninit; /* */ int x_global_init = 1; /* , * C */ static int y_global_uninit; /* , * C */ static int y_global_init = 2; /* , - * */ extern int z_global; /* , - * ( "extern", * ) */ int fn_a(int x, int y); /* . static, * C . */ static int fn_b(int x) { return x+1; } /* . */ /* . */ int fn_c(int x_local) { /* */ int y_local_uninit; /* */ int y_local_init = 3; /* , , * */ x_global_uninit = fn_a(x_local, x_global_init); y_local_uninit = fn_a(x_local, y_local_init); y_local_uninit += fn_b(z_global); return (x_global_uninit + y_local_uninit); } What makes the C compiler
The C compiler’s job is to convert text that is (usually) human-readable to something the computer understands. At the output, the compiler produces an object file . On UNIX platforms, these files usually have the suffix .o; on Windows, the .obj suffix. The contents of the object file are essentially two things:
- code corresponding to the definition of the function in the C file
- data corresponding to the definition of global variables in the C file (for initialized global variables, the initial value of the variable must also be stored in the object file).
The code and data, in this case, will have names associated with them — the names of the functions or variables with which they are associated.
Object code is a sequence of (appropriately composed) machine instructions that correspond to C instructions written by a programmer: all these
if and while and even goto . These spells have to manipulate information of a certain kind, and the information must be located somewhere - for this we need variables. The code can also refer to other code (in particular, to other C functions in the program).No matter where the code refers to a variable or function, the compiler allows this only if it has seen the declaration of this variable or function before. An announcement is a promise that a definition exists somewhere else in the program.
Job linker check these promises. However, what does the compiler do with all these promises when it generates an object file?
Essentially, the compiler leaves empty spaces. An empty space (link) has a name, but the value corresponding to this name is not yet known.
Given this, we can portray the object file corresponding to the program above , as follows:
Analyzing the object file
So far we have considered everything at a high level. However, it is useful to see how this works in practice. The main tool for us will be the
nm command, which provides information about the symbols of the object file on the UNIX platform. For Windows, dumpbin with the /symbols option is an approximate equivalent. There are also GNU binutils tools ported to Windows , which include nm.exe .Let's see what gives
nm for the object file obtained from our example above : Symbols from c_parts.o: Name Value Class Type Size Line Section fn_a | | U | NOTYPE| | |*UND* z_global | | U | NOTYPE| | |*UND* fn_b |00000000| t | FUNC|00000009| |.text x_global_init |00000000| D | OBJECT|00000004| |.data y_global_uninit |00000000| b | OBJECT|00000004| |.bss x_global_uninit |00000004| C | OBJECT|00000004| |*COM* y_global_init |00000004| d | OBJECT|00000004| |.data fn_c |00000009| T | FUNC|00000055| |.text The result may look slightly different on different platforms (refer to
man 's to get the relevant information), but the key information is the class of each character and its size (if present). A class may have different meanings:- The class U denotes the undefined references, the very “empty spaces” mentioned above. There are two objects for this class:
fn_aandz_global. (Some versions ofnmcan output a section that would be*UND*orUNDEFin this case.) - Classes t and T indicate the code that is defined; the difference between t and t is whether the function is local ( t ) in the file or not ( t ), i.e. Whether the function was declared
static. Again, on some systems, a section may be displayed, for example.text. - Classes d and D contain initialized global variables. At the same time static variables belong to the class d . If section information is present, it will be .data .
- For uninitialized global variables, we get b if they are static and B or C otherwise. The section in this case will most likely be .bss or * COM * .
You can also see characters that are not part of the original C code. We will not focus our attention on this, since this is usually part of the internal compiler mechanism, so that your program can still be put together.
What the linker does: part 1
Earlier, we mentioned that the declaration of a function or variable is a promise to the compiler, that somewhere else in the program there is a definition of this function or variable, and that the work of the linker is to fulfill this promise. Looking at the object file diagram , we can describe this process as “filling in empty places”.
We illustrate this with an example, considering another C file in addition to what was mentioned above .
/* */ int z_global = 11; /* y_global_init, static */ static int y_global_init = 2; /* */ extern int x_global_init; int fn_a(int x, int y) { return(x+y); } int main(int argc, char *argv) { const char *message = "Hello, world"; return fn_a(11,12); } From both diagrams, we can see that all points can be connected (if not, the linker would give an error message). Every thing has its place, and every place has its own thing. Also, the linker can fill all empty spaces as shown here (on UNIX systems, the linking process is usually called with the
ld command).As with object files , we can use
nm to examine the final executable file. Symbols from sample1.exe: Name Value Class Type Size Line Section _Jv_RegisterClasses | | w | NOTYPE| | |*UND* __gmon_start__ | | w | NOTYPE| | |*UND* __libc_start_main@@GLIBC_2.0 | U | FUNC|000001ad| |*UND* _init |08048254| T | FUNC| | |.init _start |080482c0| T | FUNC| | |.text __do_global_dtors_aux|080482f0| t | FUNC| | |.text frame_dummy |08048320| t | FUNC| | |.text fn_b |08048348| t | FUNC|00000009| |.text fn_c |08048351| T | FUNC|00000055| |.text fn_a |080483a8| T | FUNC|0000000b| |.text main |080483b3| T | FUNC|0000002c| |.text __libc_csu_fini |080483e0| T | FUNC|00000005| |.text __libc_csu_init |080483f0| T | FUNC|00000055| |.text __do_global_ctors_aux|08048450| t | FUNC| | |.text _fini |08048478| T | FUNC| | |.fini _fp_hw |08048494| R | OBJECT|00000004| |.rodata _IO_stdin_used |08048498| R | OBJECT|00000004| |.rodata __FRAME_END__ |080484ac| r | OBJECT| | |.eh_frame __CTOR_LIST__ |080494b0| d | OBJECT| | |.ctors __init_array_end |080494b0| d | NOTYPE| | |.ctors __init_array_start |080494b0| d | NOTYPE| | |.ctors __CTOR_END__ |080494b4| d | OBJECT| | |.ctors __DTOR_LIST__ |080494b8| d | OBJECT| | |.dtors __DTOR_END__ |080494bc| d | OBJECT| | |.dtors __JCR_END__ |080494c0| d | OBJECT| | |.jcr __JCR_LIST__ |080494c0| d | OBJECT| | |.jcr _DYNAMIC |080494c4| d | OBJECT| | |.dynamic _GLOBAL_OFFSET_TABLE_|08049598| d | OBJECT| | |.got.plt __data_start |080495ac| D | NOTYPE| | |.data data_start |080495ac| W | NOTYPE| | |.data __dso_handle |080495b0| D | OBJECT| | |.data p.5826 |080495b4| d | OBJECT| | |.data x_global_init |080495b8| D | OBJECT|00000004| |.data y_global_init |080495bc| d | OBJECT|00000004| |.data z_global |080495c0| D | OBJECT|00000004| |.data y_global_init |080495c4| d | OBJECT|00000004| |.data __bss_start |080495c8| A | NOTYPE| | |*ABS* _edata |080495c8| A | NOTYPE| | |*ABS* completed.5828 |080495c8| b | OBJECT|00000001| |.bss y_global_uninit |080495cc| b | OBJECT|00000004| |.bss x_global_uninit |080495d0| B | OBJECT|00000004| |.bss _end |080495d4| A | NOTYPE| | |*ABS* It contains the characters of both object files and all undefined links have disappeared. The characters are reordered so that similar types are found together. There are also a few add-ons to help the OS deal with such a thing as an executable file.
There is a sufficient number of complex parts that obstruct the conclusion, but if you drop everything that begins with an underscore, it will become much easier.
Duplicate characters
In the previous chapter, it was mentioned that the linker gives an error message if it cannot find a definition for the character to which the link was found. And what happens if two definitions are found for a symbol at the time of composition?
In C ++, the solution is straightforward. A language has a limitation known as the rule of one definition , which states that there must be only one definition for each character occurring at the time of composition, no more, no less. (The corresponding chapter of the C ++ standard is 3.2, which also mentions some exceptions, which we will discuss a little later .)
For C, things are less obvious. There must be exactly one definition for any function and an initialized global variable, but the definition of a non-initialized variable can be interpreted as a preliminary definition . The C language thus allows (or at least does not prohibit) different source files to contain a preliminary definition of the same object.
However, linkers should be able to manage with other languages besides C and C ++, for which the rule of one definition is not necessarily followed. For example, it is normal for Fortran to have a copy of each global variable in each file that references it. The linker then needs to remove duplicates by selecting one copy (the largest representative, if they differ in size) and discard all the others. This model is sometimes called the “generic layout” model because of the COMMON (generic) Fortran language.
As a result, it is quite common for UNIX compilers not to swear for the presence of duplicate characters, at least if they are duplicate characters of uninitialized global variables (this layout model is sometimes called a “weak link model”) . def model. More successful suggestions are welcome]). If this worries you (probably should be worried), refer to the documentation of your linker to find the -
--- option that pacifies its behavior. For example, in the GNU toolchain, the -fno-common compiler option forces you to place an uninitialized variable in the BBS segment instead of generating common (COMMON) blocks.What does the operating system do
Now that the linker has made an executable file, assigning a suitable definition to each symbol reference, you can make a short pause to understand what the operating system does when you start the program for execution.
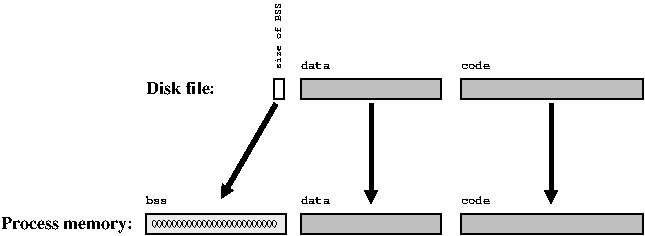
Running the program of course entails the execution of machine code, i.e. The OS should obviously transfer the machine code of the executable file from the hard disk to the operational memory, from where the CPU can pick it up. These portions are called a code segment (code segment or text segment).
Code without data is useless by itself. Therefore, all global variables also need a place in the computer's memory. However, there is a difference between initialized and uninitialized global variables. Initialized variables have certain starting values that must also be stored in object and executable files. When the program is launched at the start, the OS copies these values into the virtual space of the program, into a data segment.
For uninitialized OS variables, it can be assumed that they all have 0 as the initial value, i.e. There is no need to copy any values. A chunk of memory that is initialized with zeros is known as the bss segment.
This means that space for global variables can be allotted in an executable file stored on disk; for initialized variables, their initial values should be saved, but for uninitialized ones, you only need to keep their size.
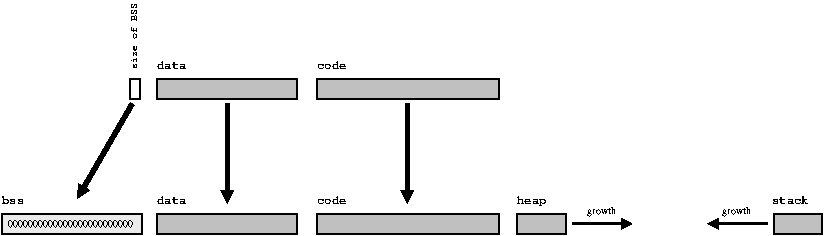
As you can see, so far in all the arguments about object files and linker, we have only been talking about global variables; however, we did not mention local variables and dynamically occupied memory mentioned earlier .
This data does not require the intervention of the linker, because the time of their life begins and ends during the execution of the program - much later than the linker has already done his job. However, for the sake of completeness, we briefly indicate that:
- Local variables are located in a memory area called the stack , which grows and shrinks as you call and execute various functions.
- dynamically allocated memory is taken from a memory area known as a heap , and the malloc function controls access to free space in that area.
For completeness, it is worth adding what the memory space of the process being performed looks like. Since the heap and the stack can change their sizes dynamically, the fact that the stack grows in one direction is quite common, and the heap is reversed. Thus, the program will generate an error of lack of free memory only if the stack and the heap meet somewhere in the middle (in this case, the memory space of the program will really be filled).
What the linker does; part 2
Now that we’ve covered the basics of what the linker does, we can dive into the description of more complex parts — roughly in the chronological order they were added to the linker.
The main observation that affects the linker’s functions is the following: if a number of different programs do about the same things (output to the screen, read files from a hard disk, etc.), then obviously it makes sense to isolate this code in a certain place and give it to others programs use it.
One possible solution would be to use the same object files, but it would be much more convenient to keep the entire collection of ... object files in one easily accessible place: a library .
Technical digression: This chapter completely omits the important property of the linker: relocation. Different programs have different sizes, i.e. if the shared library is mapped into the address space of various programs, it will have different addresses.This in turn means that all functions and variables in the library will be in different places. Now, if all references to addresses are relative (“value +1020 bytes from here”) rather than absolute (“value in 0x102218BF”), then this is not a problem, but this is not always the case. In such cases, all absolute addresses need to add a suitable offset - this is relocation . I’m not going to return to this topic again, but I’ll add that since it’s almost always hidden from a C / C ++ programmer, it’s very rare for layout problems to be caused by redirection difficulties.
Static libraries
The simplest embodiment of the library is the static library. In the previous chapter it was mentioned that you can share (share) the code simply by reusing the object files; this is the essence of static libraries.
On UNIX systems, the command to build a static library is usually ar , and the library file, which is obtained, has the extension * .a. Also, these files usually have the prefix “lib” in their name and they are passed to the linker with the "-l" option followed by the library name without the prefix and extension (i.e., "-lfred" will pick up the file "libfred.a").
(In the past, a program called
ranlibwas also needed for static libraries to generate a list of characters at the beginning of the library. Nowadays, toolsarthey do it themselves.)In Windows, static libraries have an extension
.LIBand are built with LIB tools, but this fact can be misleading, since the same extension is used for the “import library”, which contains only the list of what is in the DLL - see the Windows DLL chapterAs the linker iterates over the collection of object files to merge them together, it maintains a list of characters that cannot be implemented yet. Once all the explicitly specified object files are processed, the linker now has a new place to search for characters that remain in the list — in the library. If an unrealized character is defined in one of the library objects, then the object is added, just as if it were added to the list of object files by the user, and the layout continues.
Pay attention to the granularity of what is added from the library: if you need to define a certain character, then the whole objectcontaining the definition of the character will be included. This means that this process can be either a step forward or a step back — a newly added object can either resolve an undefined link or bring in a whole collection of new unresolved links.
Another important detail is the order of events; libraries are attracted only when the normal layout is complete, and they are processed in order from left to right. This means that if the object retrieved from the library last requires a symbol from the library that was previously in the line of the build command, then the linker will not find it automatically.
We give an example to clarify the situation; suppose we have the following object files and a build command line that contains
ao, bo, -lxand -ly.| File | ao | bo | libx.a | liby.a | ||||
| An object | ao | bo | x1.o | x2.o | x3.o | y1.o | y2.o | y3.o |
| Oprede- Lenia | a1, a2, a3 | b1, b2 | x11, x12, x13 | x21, x22, x23 | x31, x32 | y11, y12 | y21, y22 | y31, y32 |
| unsolvable shonnye links | b2, x12 | a3, y22 | x23, y12 | y11 | y21 | x31 | ||
Once the linker has processed
aoand bolinked b2and a3will be allowed, while x12and y22are still unresolved. At this point, the linker checks the first library libx.afor missing characters and finds what it can include x1.oto compensate for the link to x12; however, by doing this, x23they y12are added to the list of undefined links (now the list looks like y22, x23, y12).Linker is still dealing with
libx.a, so the link to is x23easily compensated, including x2.ofrom libx.a. However, this adds y11to the list of uncertain (which has become y22, y12, y11). None of these links can be resolved usinglibx.aso the linker is taken for liby.a.Here is about the same and linker includes
y1.oand y2.o. The first object adds a link to y21, but since it y2.owill still be included, this link is resolved simply. The result of this process is that all undefined references are allowed, and some (but not all) library objects are included in the final executable file.Notice that the situation changes somewhat, if we
boalso have a link to y32. If this were the case, the layout libx.awould also occur, but the processing liby.awould entail inclusion y3.o. By including this object we will addx31to the list of unresolved symbols and this link will remain unresolved - at this stage the linker has already completed processing libx.aand therefore will not find the definition of this symbol (c x3.o).(By the way, this example has a cyclical dependency between libraries
libx.aand liby.a; usually this is bad especially under Windows )Dynamic shared libraries
For popular libraries such as the standard C library (usually
libc) being a static library has an obvious disadvantage - each executable program will have a copy of the same code. Indeed, if each executable file will have a copy printf, fopenand the like, there will be an unnecessarily large amount of disk space.A less obvious drawback is that in a statically linked program, the code is fixed forever. If someone finds and corrects a bug in
printf, then each program will need to be rebuilt to get the corrected code.To get rid of these and other problems, dynamically shared libraries were presented (usually they have an extension
.soor .dllin Windows and.dylibon Mac OS X). For this type of library, the linker does not necessarily connect all points. Instead, the linker issues an IOU coupon (I owe you = I owe you) and postpones the cashout of that coupon until the program starts.All this boils down to the fact that if the linker detects that the definition of a particular symbol is in a shared library, then it does not include this definition in the final executable file. Instead, the linker records the name of the symbol and the library from which the symbol is supposed to appear.
When a program is called for execution, the OS takes care that the remaining parts of the build process are completed on time before the program starts. Before a function is called
main, a small version of the linker (often calledld.so) goes through the list of promises and performs the last act of linking right on the spot - puts the library code and connects all points.This means that no executable file contains a copy of the code
printf. If the new version printfis available, then it can be used simply by changing it libc.so- the next time the program starts, a new one will be printfcalled.There is another big difference between how dynamic libraries work compared to static libraries and this is manifested in the granularity of the layout. If a particular symbol is taken from a specific dynamic library (say
printffromlibc.so), then the entire contents of the library is placed in the address space of the program. This is the main difference from static libraries, where only specific objects related to an undefined symbol are added.We formulate differently, shared libraries themselves are obtained as the result of the linker's work (and not as the formation of a large heap of objects, as it does
ar), containing links between objects in the library itself. I will repeat it again nm- a useful tool to illustrate what is happening: for the example above, it will produce multiple outcomes for each object file separately, if this tool is run on a static version of a library, but for a shared version of a library it liby.sohas only one undefined symbolx31. Also in the example of the order of libraries included in the end of the previous chapter , too, no problems will not be: add links to y32in the bcwill not entail any changes, because all the contents y3.oand x3.oit was involved.So by the way, another useful tool is this
ldd; on the Unix platform, it shows all shared libraries on which the executable binary depends (or another shared library), along with an indication of where these libraries can be found. In order for the program to start successfully, the loader needs to find all these libraries along with all their dependencies. (Usually the loader searches for libraries in the list of directories specified in the environment variable LD_LIBRARY_PATH.) /usr/bin:ldd xeyes linux-gate.so.1 => (0xb7efa000) libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000) libXmu.so.6 => /usr/lib/libXmu.so.6 (0xb7ec6000) libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000) libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000) libSM.so.6 => /usr/lib/libSM.so.6 (0xb7d8b000) libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000) libm.so.6 => /lib/libm.so.6 (0xb7d4e000) libc.so.6 => /lib/libc.so.6 (0xb7c05000) libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000) libxcb-xlib.so.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000) libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000) libdl.so.2 => /lib/libdl.so.2 (0xb7be4000) /lib/ld-linux.so.2 (0xb7efb000) libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000) The reason for the greater granularity is that modern operating systems are intelligent enough to allow you to do more than just save duplicate items on disk than static libraries suffer. Different executable processes that use the same shared library can also share a code segment (but not a data segment or bss segment — for example, two different processes can be found in different places when used, say,
strtok). To achieve this, the entire library must be addressed in one fell swoop so that all internal links are built in one-to-one manner. Indeed, if one process picks up aoand co, and the other boand co, then the OS will not be able to use any matches.Windows dll
Despite the fact that the general principles of shared libraries are about the same on both Unix and Windows platforms, there are still a few details that beginners can get.
Exported characters
The biggest difference is that symbols are not automatically exported to Windows libraries . In Unix, all characters of all object files that have been authenticated to a shared library are visible to the user of this library. In Windows, the programmer must explicitly make some characters visible, i.e. export them.There are three ways to export the symbol and the Windows DLL (and all these three methods can be mixed in the same library).
- In the source code, declare a symbol as
__declspec(dllexport), like this:__declspec(dllexport) int my_exported_function(int x, double y) - When executing a linker command, use the option
LINK.EXEexport:symbol_to_exportLINK.EXE /dll /export:my_exported_function - Feed the module definition file (DEF) to the linker (using the option
/DEF:def_file) by including a section in this fileEXPORTthat contains the characters to be exported.EXPORTS my_exported_function my_other_exported_function
As soon as C ++ is connected to this jumble, the first of these options becomes the simplest, since in this case the compiler undertakes to take care of decorating the names
.LIB and other library related files
We come to the second difficulty with the Windows libraries: information about exported symbols that the linker must associate with other symbols is not contained in itself DLL. Instead, this information is contained in the corresponding .LIBfile..LIBThe file associated with DLLdescribes which (exported) characters are located DLLalong with their location. Any binary that uses DLLmust access the .LIBfile in order to bind the characters correctly.To make it even more confusing, the extension is
.LIBalso used for static libraries.In fact, there are a number of different files that can relate in any way to the Windows libraries. As well as
.LIBfile, as well as (optional) .DEFfile you can see all the files listed below associated with your Windows library.- Layout output files
- library
.DLL: the actual library code; This file is needed (at runtime) by any binary using the library. - library
.LIB: a “library import” file that describes where and which character is in the resulting oneDLL. This file is generated only if itDLLexports some of its characters. If the characters are not exported, then there is no sense in the.LIBfile. This file is needed at build time. - library
.EXP: “Export file” of the compiled library, which is needed if there is an arrangement of binaries with circular dependency . - library
.ILK:/INCREMENTAL, , . . - library
.PDB:/DEBUG, , . - library
.MAP:/MAP, .
- library
- :
- library
.LIB: « »,DLL, . - library
.LIB: , , ..LIB - library
.DEF: «», , . - library
.EXP: , ,LIB.EXE.LIB. . - library
.ILK: ; . . - library
.RES: A resource file that contains information about the various GUI widgets used by the executable file. These resources are included in the final binary.
- library
This is a big difference to Unix, where almost all the information contained in these all additional files is simply added to the library itself.
Imported characters
Along with the requirement for the DLL to explicitly declare exported characters , Windows also allows binaries that use library code to explicitly declare characters to be imported. This is not mandatory, but gives some speed optimization, caused by the historical properties of 16-bit windows .To do this, declare the symbol as __declspec (dllimport) in the source code like this:
__declspec(dllimport) int function_from_some_dll(int x, double y); __declspec(dllimport) extern int global_var_from_some_dll; At the same time, an individual declaration of functions or global variables in one header file is a good programming tone in C. This leads to some rebus: the code in the DLL containing the definition of the function / variable must export the character, but any other code using the DLL must import the character.
The standard way out of this situation is to use preprocessor macros.
#ifdef EXPORTING_XYZ_DLL_SYMS #define XYZ_LINKAGE __declspec(dllexport) #else #define XYZ_LINKAGE __declspec(dllimport) #endif XYZ_LINKAGE int xyz_exported_function(int x); XYZ_LINKAGE extern int xyz_exported_variable; The source file in the DLL that defines the function and variable ensures that the preprocessor variable is
EXPORTING_XYZ_DLL_SYMSdefined (by means #define) before including the corresponding header file and thus exports the symbol. Any other code that includes this header file does not define this character and thus imports it.Cyclic dependencies
Another difficulty associated with using a DLL is the fact that Windows is stricter with the requirement that each character must be resolved at link time. In Unix, it is quite possible to build a shared library that contains unresolved characters, i.e. symbols, whose definition is unknown to the linker In this situation, any other code using this shared library will have to provide a definition of unresolved symbols, otherwise the program will not run. Windows does not allow such licentiousness.For most systems, this is not a problem. Executable files depend on high-level libraries, high-level libraries depend on low-level libraries, and everything is arranged in reverse order — first low-level libraries, then high, and then the executable file, which depends on all the others.
However, if there is a cyclic relationship between the binaries then everything gets a bit more complicated. If it
X.DLLneeds a symbol from Y.DLL, but Y.DLLneeds a symbol from X.DLL, then it is necessary to solve the problem about the chicken and the egg: whatever library would be combined first, it will not be able to find a resolution to all the characters.Windows provided a workaround similar to the following.
- X.
LIB.EXE(LINK.EXE),X.LIB,LINK.EXE.X.DLL,X.EXP. Y,X.LIB, ,Y.DLLY.LIB.- In the end, we are compiling the library
Xnow fully. This happens almost as usual, using additionally the fileX.EXPobtained in the first step. The usual thing in this step is what the linker usesY.LIBand producesX.DLL. Unusual - the linker skips the creation stepX.LIB, since this file was already created in the first step, as indicated by the presence of the.EXPfile.
But it is undoubtedly better to reorganize the libraries in such a way as to avoid any cyclic dependencies ...
C ++ to complete the picture
C ++ offers a number of additional features beyond what is available in C, and some of these features affect the work of the linker. This was not always the case - the first C ++ implementations appeared as an external interface to the C compiler, so there was no need for compatibility of the linker’s work. Over time, however, more advanced features of the language were added, so that the linker already had to be changed to support them.
Function overloading and name decoration
The first difference in C ++ is that functions can be overloaded, that is, functions with the same name can exist at the same time, but with different types accepted (with different function signatures ):
int max(int x, int y) { if (x>y) return x; else return y; } float max(float x, float y) { if (x>y) return x; else return y; } double max(double x, double y) { if (x>y) return x; else return y; } This state of affairs definitely makes the linker’s work harder: if any code accesses a function
max, which one was meant?The solution to this problem is called name decoration (name mangling), because all the information about the signature of the function is translated (to mangle = distort, deform, comment ) in a text form that becomes the actual symbol name from the layout perspective. Different signatures are translated into different names. Thus, the problem of uniqueness of names is solved.
I'm not going to go into the details of the decorating schemes used (which also differ from platform to platform), but a quick glance at the object file corresponding to the code above will give an idea of how to understand all this (remember
nm - Your friend!): Symbols from fn_overload.o: Name Value Class Type Size Line Section __gxx_personality_v0| | U | NOTYPE| | |*UND* _Z3maxii |00000000| T | FUNC|00000021| |.text _Z3maxff |00000022| T | FUNC|00000029| |.text _Z3maxdd |0000004c| T | FUNC|00000041| |.text Here we see three functions
max, each of which received a different name in the object file, and we can be smart and assume that the next two letters after “max” denote the types of input parameters - “i” as int, “f” as floatwell as “d” as double(however, things get more complicated if classes, namespaces, templates, and overloaded operators come into play!).It is also worth noting that there is usually a way to convert between names visible to the programmer and names visible to the linker. It can be a separate program (for example,
c++filt) or an option on the command line (for example --demanglefor GNU nm), which gives something similar to this: Symbols from fn_overload.o: Name Value Class Type Size Line Section __gxx_personality_v0| | U | NOTYPE| | |*UND* max(int, int) |00000000| T | FUNC|00000021| |.text max(float, float) |00000022| T | FUNC|00000029| |.text max(double, double) |0000004c| T | FUNC|00000041| |.text The area where decoration schemes are most often made to err is located at the intersection of C and C ++. All characters produced by the C ++ compiler are decorated; all the characters produced by the C compiler look the same as in the source code. To get around this, the C ++ language allows you to put
extern "C"around declarations and function definitions. In essence, we tell C ++ to the compiler that a particular name should not be decorated - either because it is the definition of the C ++ function that will be called by C code, or later that it is the definition of the C function, which will be called by C ++ code.Returning to the example at the very beginning of the article, you can easily notice that there is a rather high probability that someone forgot to use
extern "C"when composing C and C ++ objects. g++ -o test1 test1a.o test1b.o test1a.o(.text+0x18): In function `main': : undefined reference to `findmax(int, int)' collect2: ld returned 1 exit status The great clue is that the error message contains the signature of the function - it is not just a message that was
findmaxnot found. In other words, C ++ code looks for something like "_Z7findmaxii", but only finds "findmax". Therefore, a layout error occurs.By the way, notice that the declaration is
extern "C"ignored for class member functions (§7.5.4 of the C ++ standard)Initialization of static objects
The next C ++ property that goes beyond C, which affects the operation of the linker, is the existence of object constructors . A constructor is a piece of code that sets the initial state of an object. In essence, his work is conceptually equivalent to initializing the value of a variable, but with the important difference that we are talking about arbitrary code fragments.
Recall from the first chapter that global variables can begin their existence already with a certain value. In C, the construction of the initial value of such a global variable is a simple matter: a certain value is simply copied from the data segment of the executable file to the appropriate place in the program's memory that is about to be executed.
In C ++, the initialization process can be much more complicated than just copying fixed values; all code in various constructors across the entire class hierarchy must be executed before the program itself actually starts.
To cope with this, the compiler places some additional information in the object file for each C ++ file; namely, this is a list of constructors that should be called for a specific file. During linking, the linker merges all of these lists into one large list, and also places the code that passes through the entire list, invoking the constructors of all global objects.
Note that the orderin which constructors of global objects are called not defined - it is completely at the mercy of what the linker intends to do. (See Scott Myers Effective C ++ for further details - note 47 in the second edition , note 4 in the third edition )
We can follow these lists, again by resorting to help
nm. Consider the following C ++ file: class Fred { private: int x; int y; public: Fred() : x(1), y(2) {} Fred(int z): x(z), y(3) {} }; Fred theFred; Fred theOtherFred(55); For this code ( not decorated) the output
nmlooks like this: Symbols from global_obj.o: Name Value Class Type Size Line Section __gxx_personality_v0| | U | NOTYPE| | |*UND* __static_initialization_and_destruction_0(int, int) |00000000| t | FUNC|00000039| |.text Fred::Fred(int) |00000000| W | FUNC|00000017| |.text._ZN4FredC1Ei Fred::Fred() |00000000| W | FUNC|00000018| |.text._ZN4FredC1Ev theFred |00000000| B | OBJECT|00000008| |.bss theOtherFred |00000008| B | OBJECT|00000008| |.bss global constructors keyed to theFred |0000003a| t | FUNC|0000001a| |.text As usual, we can see a bunch of different things here, but one of them is most interesting for us are records with class W (which means “weak” symbol) and also records with the name of a section like ".gnu.linkonce. t. stuff ". These are markers for constructors of global objects and we see that the corresponding “Name” field shows what we actually could expect there - each of the two designers is involved.
Templates
Earlier, we gave an example with three different implementations of a function
max, each of which took arguments of different types. However, we see that the code of the function body is identical in all three cases. And we know that duplicating the same code is a bad programming tone.C ++ introduces the concept of a template (templates), which allows you to use the code below for all cases at once. We can create a header file
max_template.hwith only one copy of the function code max: template <class T> T max(T x, T y) { if (x>y) return x; else return y; } and include this file in the source file to try out the template function:
#include "max_template.h" int main() { int a=1; int b=2; int c; c = max(a,b); // , max<int>(int,int) double x = 1.1; float y = 2.2; double z; z = max<double>(x,y); // , max<double>(double,double) return 0; } This C ++ code uses
max<int>(int,int)and max<double>(double,double). However, some other code could use other instances of this pattern. Well, let's say, max<float>(float,float)or even max<MyFloatingPointClass>(MyFloatingPointClass,MyFloatingPointClass).Each of these different instances generates a different machine code. Thus, at the time when the program is finalized, the compiler and the linker must ensure that the code of each instance of the template used is included in the program (and no unused instance of the template is included, so as not to exaggerate the size of the program).
How is this done? There are usually two ways of doing things: either thinning out the repetitive instances or postponing the instances to the build stage (I usually call these approaches the reasonable way and the Sun way).
The method of thinning repetitive instances implies that each object file contains the code of all the patterns encountered. For example, for the file above, the contents of the object file look like this:
Symbols from max_template.o: Name Value Class Type Size Line Section __gxx_personality_v0 | | U | NOTYPE| | |*UND* double max<double>(double, double) |00000000| W | FUNC|00000041| |.text _Z3maxIdET_S0_S0_ int max<int>(int, int) |00000000| W | FUNC|00000021| |.text._Z3maxIiET_S0_S0_ main |00000000| T | FUNC|00000073| |.text And we see the presence of both instances
max<int>(int,int)and max<double>(double,double).Both definitions are marked as weak characters , which means that the linker, when creating the final executable file, can throw out all the repeated instances of the same template and leave only one (and if it considers it necessary, then it can check whether all the repeated instances of the template are displayed in the same code). The biggest disadvantage in this approach is the increase in the size of each individual object file.
Another approach (which is used in Solaris C ++) is not to include template definitions in object files in general, but to mark them as undefined characters. When it comes to the build stage, the linker can collect all the undefined characters that actually belong to the template instances, and then generate the machine code for each of them.
This definitely reduces the size of each object file, but the disadvantage of this approach is that the linker should keep track of where the source code is and should be able to run the C ++ compiler during linking (which can slow down the whole process)
Dynamically loadable libraries
The last feature we discuss here is the dynamic loading of shared libraries. In the previous chapter, we saw how the use of shared libraries postpones the final layout until the program itself starts. In modern operating systems, this is even possible at later stages.
This is done by a pair of system calls
dlopenand dlsym(approximate equivalents in Windows, respectively, are called LoadLibraryand GetProcAddress). The first one takes the name of the shared library and loads it into the address space of the running process. Of course, this library may also have unresolved characters, so a call dlopenmay entail loading other shared libraries.dlopenIt offers the choice of either eliminating all unresolved issues as soon as the library is loaded, ( RTLD_NOW) or resolving characters as necessary ( RTLD_LAZY). The first method means that the call dlopenmay take enough time, however, the second method lays a certain risk that during the execution of the program an undefined link will be found that cannot be resolved - at this point the program will be completed.Of course, characters from a dynamically loaded library cannot have a name. However, this is simply solved, as well as other programmer problems are solved by adding an additional level of workarounds. In this case, a pointer to the character space is used. Call
dlsymtakes a literal parameter that gives the name of the character to be found and returns a pointer to its location (or NULL, if the character is not found).Interacting with C ++
The dynamic loading process is fairly straightforward, but how does it interact with various C ++ features that affect the entire behavior of the linker?
The first observation concerns the decoration of names. When called
dlsym, the name of the character to be found is transmitted. So this should be the version of the name visible to the linker, i.e. decorated name.Since the decorating process can vary from platform to platform and from compiler to compiler, this means that it is almost impossible to dynamically find a C ++ symbol by a universal method. Even if you work with only one compiler and delve into its inner world, there are other problems - besides simple C-like functions, there are a lot of other things (virtual method tables and the like) that need to be taken care of.
Summarizing the above, we note the following: it is usually better to have one prisoner at the
extern "C"point of entry that can be found dlsym. This entry point can be a factory method that returns pointers to all instances of a C ++ class, allowing access to all the advantages of C ++.The compiler can easily deal with the constructors of global objects in the library being loaded
dlopen, as there are a couple of special characters that can be added to the library and that will be called by the linker (no matter during loading or execution) if the library is dynamically loaded or unloaded - that is, necessary calls to constructors or destructors can occur here. In Unix, these are functions _initand_fini, or for newer systems using the GNU toolkit, there are functions labeled as __attribute__((constructor))or __attribute__((destructor)). In Windows, the corresponding function is DllMainwith the parameter DWORD fdwReasonequal to DLL_PROCESS_ATTACHor DLL_PROCESS_DETACH.And in conclusion, we add that dynamic loading copes well with the “thinning out of repeated instances”, if we are talking about instantiating templates; and everything looks ambiguous with “postponing instantiation”, since the “build stage” comes after the program is already running (and quite likely on another machine that does not store the source code). Refer to the compiler and linker documentation to find a way out of this situation.
Additionally
In this article, many details were intentionally omitted on how the linker works, because I believe that the content of the written covers 95% of the everyday problems that the programmer has to deal with when building his program.
If you want to know more, you can read the information from the links below:
- John Levine, Linkers and Loaders : contains a huge amount of information about the intricacies of the linker and the loader, including all the things missed in this article. There is also an online version of this book (or its draft) here .
- An excellent link to the description of the Mach-O format for binaries on Mac OS X.
- Peter Van Der Linden, Expert C Programming : , , , C, , C, .
- Scott Meyers, More Effective C++ : 34 , C C++ ( )
- Bjarne Stroustrup, The Design and Evolution of C++ : 11.3 C++ .
- Margaret A. Ellis & Bjarne Stroustrup, The Annotated C++ Reference Manual : 7.2c
- ELF format reference [PDF]
- Two interesting articles about creating lightweight executable files in Linux and the minimum Hello World in particular.
- The How To Write Shared Libraries [PDF] of the notorious Ulrich Drepper contains more details about ELF and redirection.
Many thanks to Mike Capp and Ed Wilson for useful suggestions about this page.
Copyright © 2004-2005,2009-2010 David Drysdale
Permission is given by the Free Software Foundation; Front Cover Texts, with Back Cover Texts. A copy of the license is available here .
Source: https://habr.com/ru/post/150327/
All Articles