On the RAII idiom and locks
The RAII idiom (Resource Acquisition Is Initialization) originates in C ++ and consists in the fact that some resource is captured in the object's constructor and released in its destructor. And since the destructor of local objects is automatically called when the method exits (or just out of scope), regardless of the cause (normal completion of the method or when an exception is thrown), using this idiom is the simplest and most effective way to write followed C ++ code safe from a point view of exceptions.
When moving to “managed” platforms, such as .NET or Java, this idiom in some way loses its relevance, since the garbage collector deals with the release of memory, namely memory was the most popular resource that had to be taken care of in C ++. However, since the garbage collector deals only with memory and does not contribute to the deterministic release of resources (such as operating system descriptors), the RAII idiom is still used in .NET and in Java, even if few developers know about this intricate name.
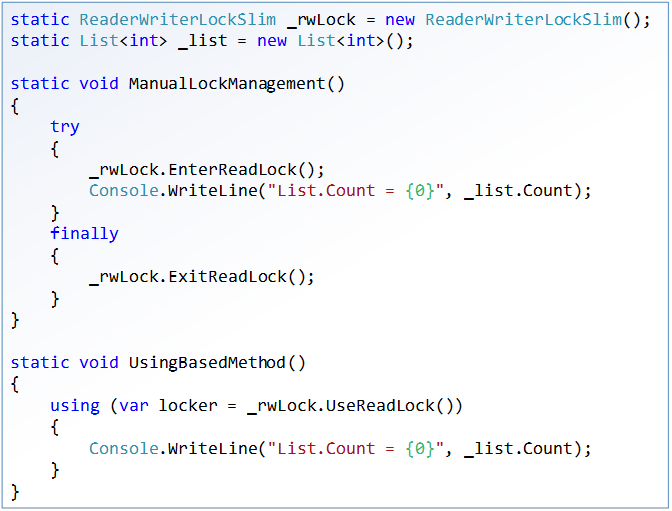
Starting with the first version of the C # language, we had at our disposal a using construct that provided automatic release of resources by calling the Dispose method. Another method of deterministic release of resources was (and remains) the manual use of a try / finally block. Let's look at the following couple of simple examples of using the ReaderWriterLockSlim class, which is designed to more effectively share a common resource between “readers” and “writers”:
')
In the ManualLockManagerment method, manual locking is used, while the UsingBasedMethod method is based on a small shell. A full example of this shell can be found here , but it’s not difficult to guess how it works : the UseReadLock extension method creates some object, the constructor of which takes the lock for reading, and the Dispose method frees it. The question is how much the two fragments are equivalent and what should be preferred? Of course, a “bicycle” with a using block looks more readable, but is this the only difference between them?
OK. Let's complicate the first example a little. That if in our code there is the possibility of recursive calls, when the method after the lock is captured for reading, it calls the method that locks the read lock again. I don’t think that every reader remembers the behavior of the ReaderWriterLockSlim object in terms of re-capture (default reentrancy mode), so I’ll immediately say that, unlike the lock construct, ReaderWriterLockSlim objects do not support recursive captures by default:
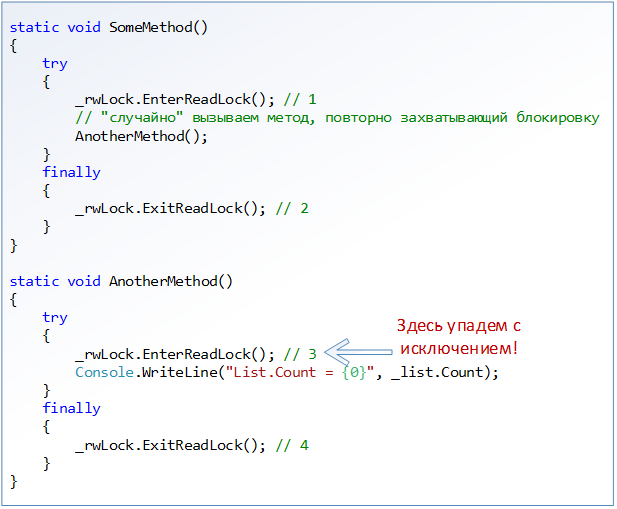
In this case, we get the mismatched state of the lock object and the generation of the SynchronizationLockException exception, but how obvious is exactly which point in the code will generate it, and what consequences will it cause? The problem with the above code is that it does not match the behavior of the RAII idiom and the using block: resources should be freed in the finally block only if they were successfully captured before .
In this case, the following occurs: since the ReaderWriterLockSlim object does not support recursive captures, when you try to call the EnterReadLock method a second time (line 3 of the AnotherMethod method), a LockRecusionException exception will be generated, but since this call is inside the try block, the AnotherMethod method’s finally block is called a subsequent call to ExitReadLock . As a result, in line 4 we will get a free lock, which in itself is not healthy, because we did not capture it; after that, the control is returned to the SomeMethod method and goes to the finally block, where the ExitReadLock method will be called again.
This is where the fun begins. When I thought about the problem of using the construction using vs manual resource management via try / finally , I assumed that this code would fall with the exception in the line for the first time, and then fall again in line 2 of the SomeMethod method. I reasoned like this: since ReaderWriterLockSlim does not support recursive captures, the original exception will occur in line 3, but since the lock will be released in line 4, then when you try to re-release the lock, the first method will generate another exception that will “mask” the original exception.
In such an artificial example, with this behavior, finding the real reason will be quite simple, but such behavior on the production server may make you feel good about the blood, because the code may not be so obvious, why does it say that the lock is not captured when it is necessarily captured in the beginning of the method.
However, in fact, the behavior will be somewhat different, or rather, it will be exactly like this in .NET 4.5, but it will be completely different in previous versions of the platform. Let's take it in order.
The problem is that on .NET 4.0 (and below) the behavior will be as follows: an attempt to call the ExitReadLock method before calling the EnterReadLock method results in an exception, but two ExitReadLock calls after one EnterReadLock call succeed !

The most unpleasant thing in this matter is that in thecurrent old versions of the framework, this code will not just succeed, it will lead to a mismatch of the state of the lock object, with the result that we will see the following on the console: “ ReadCount = 4294967295, ReadLockHeld = False ” . In fact, in line 3 we reduced the value of the lock counter to 0, and in line 4 we reduced it again; as a result, the counter became -1, and 4294967295 is just a representation of the value “-1” in an unsigned format. But most importantly, any subsequent attempt at capturing a lock on a record will stick forever, since the dork will assume that the lock on reading is still captured.
As it turned out, this is a known bug in the .NET Framework, which is finally fixed in .NET 4.5. After the VS2012 installation, we get quite expected, though not very pleasant behavior: the original exception that occurred when the lock was re-captured was masked by a new exception that occurs when trying to release an un-captured lock!
Now let's remember how the using block works :

The using construct is deployed in such a way that the resource is captured before the try block, so that when an exception is thrown when it is captured, the release will not be performed. This behavior can lead to unpleasant consequences if the using construct is combined with the object initializer (details in the note Initializers of objects in the using block ), but it fully corresponds to the behavior of constructors / destructors in C ++, in which the destructor was called only if the object was successfully created .
NOTE
Here we are confronted with another distinction between destructors in C ++ and a finalizer in C #. Unlike the destructor, the finalizer is called even if the constructor of the created object fell with an exception. This behavior is quite logical, as it simplifies the creation of a resource management code in the C # language, when the finalizer only needs to check the fact of successful resource capture (by checking for null , IntPtr . Zero , etc.).
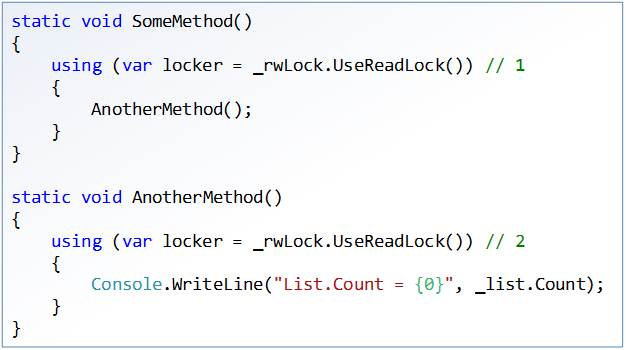
Since using the Dispose method is called only when the resource is successfully captured, the following code behaves as predictably as possible: the code calling the SomeMethod method will get an exception that occurred in line 2 of the AnotherMethod method when it tries to lock again, while the lock object is completely Normal condition in any version of the .NET Framework:
When moving to “managed” platforms, such as .NET or Java, this idiom in some way loses its relevance, since the garbage collector deals with the release of memory, namely memory was the most popular resource that had to be taken care of in C ++. However, since the garbage collector deals only with memory and does not contribute to the deterministic release of resources (such as operating system descriptors), the RAII idiom is still used in .NET and in Java, even if few developers know about this intricate name.
Starting with the first version of the C # language, we had at our disposal a using construct that provided automatic release of resources by calling the Dispose method. Another method of deterministic release of resources was (and remains) the manual use of a try / finally block. Let's look at the following couple of simple examples of using the ReaderWriterLockSlim class, which is designed to more effectively share a common resource between “readers” and “writers”:
')
In the ManualLockManagerment method, manual locking is used, while the UsingBasedMethod method is based on a small shell. A full example of this shell can be found here , but it’s not difficult to guess how it works : the UseReadLock extension method creates some object, the constructor of which takes the lock for reading, and the Dispose method frees it. The question is how much the two fragments are equivalent and what should be preferred? Of course, a “bicycle” with a using block looks more readable, but is this the only difference between them?
OK. Let's complicate the first example a little. That if in our code there is the possibility of recursive calls, when the method after the lock is captured for reading, it calls the method that locks the read lock again. I don’t think that every reader remembers the behavior of the ReaderWriterLockSlim object in terms of re-capture (default reentrancy mode), so I’ll immediately say that, unlike the lock construct, ReaderWriterLockSlim objects do not support recursive captures by default:
In this case, we get the mismatched state of the lock object and the generation of the SynchronizationLockException exception, but how obvious is exactly which point in the code will generate it, and what consequences will it cause? The problem with the above code is that it does not match the behavior of the RAII idiom and the using block: resources should be freed in the finally block only if they were successfully captured before .
In this case, the following occurs: since the ReaderWriterLockSlim object does not support recursive captures, when you try to call the EnterReadLock method a second time (line 3 of the AnotherMethod method), a LockRecusionException exception will be generated, but since this call is inside the try block, the AnotherMethod method’s finally block is called a subsequent call to ExitReadLock . As a result, in line 4 we will get a free lock, which in itself is not healthy, because we did not capture it; after that, the control is returned to the SomeMethod method and goes to the finally block, where the ExitReadLock method will be called again.
Deadlock and other troubles
This is where the fun begins. When I thought about the problem of using the construction using vs manual resource management via try / finally , I assumed that this code would fall with the exception in the line for the first time, and then fall again in line 2 of the SomeMethod method. I reasoned like this: since ReaderWriterLockSlim does not support recursive captures, the original exception will occur in line 3, but since the lock will be released in line 4, then when you try to re-release the lock, the first method will generate another exception that will “mask” the original exception.
In such an artificial example, with this behavior, finding the real reason will be quite simple, but such behavior on the production server may make you feel good about the blood, because the code may not be so obvious, why does it say that the lock is not captured when it is necessarily captured in the beginning of the method.
However, in fact, the behavior will be somewhat different, or rather, it will be exactly like this in .NET 4.5, but it will be completely different in previous versions of the platform. Let's take it in order.
The problem is that on .NET 4.0 (and below) the behavior will be as follows: an attempt to call the ExitReadLock method before calling the EnterReadLock method results in an exception, but two ExitReadLock calls after one EnterReadLock call succeed !
The most unpleasant thing in this matter is that in the
As it turned out, this is a known bug in the .NET Framework, which is finally fixed in .NET 4.5. After the VS2012 installation, we get quite expected, though not very pleasant behavior: the original exception that occurred when the lock was re-captured was masked by a new exception that occurs when trying to release an un-captured lock!
Use using or capture resources correctly!
Now let's remember how the using block works :
The using construct is deployed in such a way that the resource is captured before the try block, so that when an exception is thrown when it is captured, the release will not be performed. This behavior can lead to unpleasant consequences if the using construct is combined with the object initializer (details in the note Initializers of objects in the using block ), but it fully corresponds to the behavior of constructors / destructors in C ++, in which the destructor was called only if the object was successfully created .
NOTE
Here we are confronted with another distinction between destructors in C ++ and a finalizer in C #. Unlike the destructor, the finalizer is called even if the constructor of the created object fell with an exception. This behavior is quite logical, as it simplifies the creation of a resource management code in the C # language, when the finalizer only needs to check the fact of successful resource capture (by checking for null , IntPtr . Zero , etc.).
Since using the Dispose method is called only when the resource is successfully captured, the following code behaves as predictably as possible: the code calling the SomeMethod method will get an exception that occurred in line 2 of the AnotherMethod method when it tries to lock again, while the lock object is completely Normal condition in any version of the .NET Framework:
Source: https://habr.com/ru/post/150069/
All Articles