Teach computer feelings (sentiment analysis in Russian)
Sentiment analysis (in Russian, tonality analysis) is the field of computational linguistics, which studies the opinions and emotions in text documents. Recently, an article appeared on Habré about using machine learning for tonality analysis, however, it was so poorly compiled that I decided to write my own version. So, in this article I will try to explain in an easy way what the analysis of tonality is and how to implement such a system for the Russian language.
Tonality analysis
The purpose of the analysis of tonality is to find opinions in the text and determine their properties. Depending on the task, we may be interested in different properties, for example:
- author - who owns this opinion
- topic - what is said in the opinion
- tonality - the position of the author relative to the mentioned topic (usually "positive" or "negative")
: " – , », — " : : " " : "" In the literature there are different ways to formalize the model of opinions. I just gave an example of one of them. Different terminology is also used. In English, this area of research is commonly referred to as opinion mining and sentiment analysis (literally: “seeking opinions and analyzing feelings”). In Russian articles, the term “tonality analysis” is usually used. Despite the fact that tonality is only one of the characteristics of opinion, it is the task of classifying the tonality that is the most frequently studied in our day. This can be explained by several reasons:
- Identifying the author and the topic is much more difficult than classifying the tonality, so it makes sense to first solve a simpler problem and then switch to the others.
- In many cases, we only need to determine the tonality, because other characteristics are already known to us. For example, if we collect opinions from blogs, usually authors of opinions are authors of posts, i.e. we do not need to identify the author. Also, we often already know the topic: for example, if we search Twitter for the keyword "Windows 8", then we only need to determine the tone of the tweets found. Of course, this does not work in all cases, but only in most of them. But these assumptions make it possible to considerably simplify the already difficult task.
')
The analysis of tonality finds its practical application in various fields:
- Sociology - collect data from the social. networks (for example, religious beliefs)
- political science - collect data from blogs about political views of the population
- marketing - we analyze Twitter to find out which notebook model is most in demand
- medicine and psychology - we define depression in social users. nets
Approaches to the classification of tonality
Analysis of tonality is usually defined as one of the tasks of computational linguistics, i.e. implies that we can find and classify tonality using natural language processing tools (such as teggers, parsers, etc.). Having made a large generalization, it is possible to divide the existing approaches into the following categories:

- Rule based approaches
- Dictionary Based Approaches
- Machine learning with a teacher
- Machine learning without a teacher
The first type of system consists of a set of rules , applying which the system makes a conclusion about the tonality of the text. For example, for the sentence "I love coffee", you can apply the following rule:
("") ("", "", "" ...) , "" Many commercial systems use this approach, despite the fact that it is costly, because for a good system to work, you need to make a large number of rules. Often, the rules are tied to a specific domain (for example, “restaurant theme”) and when you change the domain (“camera review”), you must re-create the rules. Nevertheless, this approach is the most accurate with a good rule base, but completely uninteresting to research.
Dictionary based approaches use so-called tonal dictionaries (affective lexicons) to analyze text. In its simplest form, a pitch dictionary is a list of words with a pitch value for each word. Here is an example from the ANEW database translated into Russian:
| word | valence (1-9) |
|---|---|
| happy | 8.21 |
| good | 7.47 |
| boring | 2.95 |
| angry | 2.85 |
| sad | 1.61 |
To analyze the text, you can use the following algorithm: first, assign each word in the text to its value from the dictionary key (if it is present in the dictionary), and then calculate the overall tonality of the entire text. You can calculate the overall tonality in different ways. The simplest of them is the arithmetic average of all values. More difficult is to train a classifier (for example, a neural network).
Machine learning with a teacher is the most common method used in research. Its essence is to train the machine classifier on a collection of pre-marked texts, and then use the resulting model to analyze new documents. About this method I will tell further.
Machine learning without a teacher is probably the most interesting and at the same time the least accurate method for analyzing tonality. One example of this method may be automatic clustering of documents.
Machine learning with a teacher
The process of creating a tonality analysis system is very similar to the process of creating other systems using machine learning:
- it is necessary to collect a collection of documents for classifier training
- Each document from the training collection must be represented as a feature vector.
- for each document you need to specify the "correct answer", i.e. type of tonality (for example, positive or negative), the classifier will be trained according to these answers
- choice of classification algorithm and classifier training
- using the resulting model
Number of classes
The number of classes into which the tonality is divided is usually given from the system specification. For example, the customer requires the system to distinguish between three types of tonality: “positive”, “neutral”, “negative”. In studies, the problem of binary classification of tonality is usually considered, i.e. There are only two classes: “positive” and “negative”. From my experience I can say that the classification of tonality into more than two classes is a very difficult task. Even with three classes it is very difficult to achieve good accuracy regardless of the approach used.
If there is a task of classifying into more than two classes, then the following options are available for classifier training:
- Flat classification - we train only one classifier for all classes.

- Hierarchical classification - we divide classes into groups and train several classifiers to define groups. For example, if we have 5 classes (“strongly positive”, “moderately positive”, “neutral”, “moderately negative”, “strongly negative”), then we can first teach a binary classifier that separates neutral texts from subjective ones; then train a classifier that separates positive opinions from negative ones; and as a result, a classifier that separates strongly expressed opinions from the average.
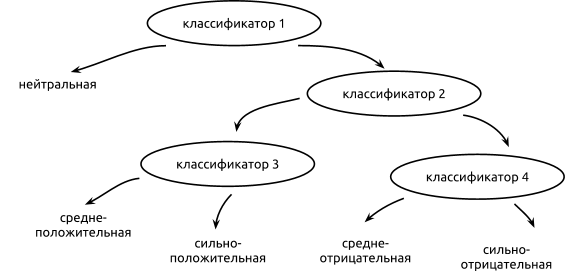
- Regression - we train the classifier to obtain a numerical value of tonality, for example, from 1 to 10, where a larger value means a more positive tonality.
Usually hierarchical classification gives better results than flat, because For each classifier, you can find a set of attributes that allows you to improve the results. However, it requires a lot of time and effort for training and testing. Regression can show the best results if there are really many classes (from 5 and more).
Feature selection
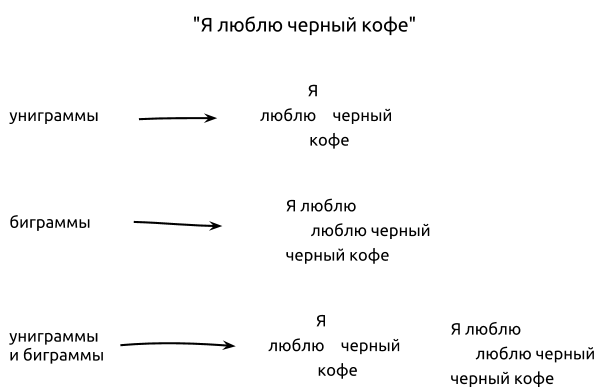
The quality of the results directly depends on how we present the document for the classifier, namely, which set of characteristics we will use to compile the feature vector. The most common way to present a document in a comp task. linguistics and search is either in the form of a set of words (bag-of-words) or in the form of a set of N-grams. For example, the sentence “I love black coffee” can be represented as a set of unigrams (I, love, black, coffee) or bigrams (I love, I love black, black coffee).
Usually unigrams and bigrams give better results than higher-order N-grams (trigrams and higher), because In most cases, the sample of training is not large enough to calculate higher-order N-grams. It always makes sense to test the results using unigrams, bigrams and their combinations (I, love, black, coffee, I love, I love black, black coffee). Depending on the type of data, unigrams may show better results than bigrams, and vice versa. Also, sometimes a combination of unigrams and bigrams improves results.
Stemming and lemmatization
In some studies, when presenting a text, all words go through a stemming procedure (deletion of the ending) or lemmatization (reduction to the initial form). The purpose of this procedure is to reduce the dimension of the problem, in other words, if the text contains the same words, but with different endings, using stemming and lemmatization, they can be reduced to the same type. However, in practice it usually does not give any tangible results. The reason for this is that by getting rid of the endings of words, we lose morphological information, which can be useful for analyzing the tonality. For example, the words “I want” and “wanted” have different tonality. If in the first case the tonality is most likely positive, since Since the author can express hope and positive emotions, then in a verb in the past tense, the tonality can be negative if the author expresses regret.
Another way of presenting text is symbolic N-grams. The text from the example can be represented as the following 4-character N-grams: “I love,” “love,” “celebrate,” “blue,” etc. Despite the fact that this method may seem too primitive, because at first glance, the character set does not carry any semantics; nevertheless, this method sometimes gives results even better than N-grams of words. If you take a closer look, you can see that the N-grams of characters correspond to some degree to the morphemes of words, and in particular the root of the word (“love”) bears in itself its meaning. Character N-grams can be useful in two cases:
- in the presence of spelling errors in the text - the set of characters in the text with errors and the set of characters in the text without errors will be almost the same as in words.
- for languages with rich morphology (for example, for Russian) - the same words can be found in texts, but in different variations (different gender or number), but the root of the words does not change, and therefore the common set of characters.
Symbolic N-grams are used much less frequently than N-grams of words, but sometimes they can improve results.
You can also use additional features such as: parts of speech, punctuation (smiles, exclamation marks in the text), negative signs in the text (“not”, “no”, “never”), interjections, etc.
Weighted Vector
The next step in the compilation of the feature vector is the assignment of a weight to each feature. For some classifiers, this is optional, for example, for a Bayesian classifier, since he himself calculates the probability for signs. But if you use the support vector method, then weighting can significantly improve the results.
In information retrieval, TF-IDF is the most common method for assessing feature weight. For the analysis of tonality this method does not give good results. The reason for this is that words are not so important for the analysis of tonality, which are often repeated in the text (ie words with high TF), in contrast to the search task. Therefore, binary weight is usually used, i.e., features (if we use unigrams, then words) are assigned a unit weight, if they are present in the text. Otherwise, the weight is zero. For example, “I love black coffee” will be represented as the following vector (we omit words with weight = 0):
{"": 1, "": 1, "": 1, "": 1} However, there are methods for assessing the importance of words, which calculate the weights of words that give much better results in the classification of tonality, for example, delta TF-IDF .
Delta TF-IDF
The idea of the delta TF-IDF method is to give more weight to words that have a non-neutral tone, because It is these words that determine the tonality of the entire text. The formula for calculating the weight of the word w is as follows:

Where:
What is the result? Let's say we work with a collection of movie reviews. Consider three words: “excellent”, “tedious”, “script”. The most important thing in the delta TF-IDF formula is the second factor log (...) . It will be different in these three words:
As a result, the weight of words with a positive tonality will be a large positive number, the weight of words with a negative tonality will be a negative number, the weight of neutral words will be close to zero. Such a weighting of the feature vector in most cases makes it possible to improve the classification accuracy of tonality.
Where:
- V t, d - the weight of the word t in the document d
- C t, d - the number of times the word t occurs in the document d
- | P | - number of documents with positive tonality
- | N | - number of documents with a negative tone
- P t - the number of positive documents, where the word t occurs
- N t - number of negative documents where the word t occurs
What is the result? Let's say we work with a collection of movie reviews. Consider three words: “excellent”, “tedious”, “script”. The most important thing in the delta TF-IDF formula is the second factor log (...) . It will be different in these three words:
- The word “excellent” is most likely to be found in most positive (P t ) reviews and almost never occurs in negative (N t ), as a result, the weight will be a large positive number, since the ratio P t / N t will be a number far greater than 1.
- The word “tedious”, on the contrary, occurs mainly in negative reviews, so the ratio P t / N t will be less than one and as a result the logarithm will be negative. As a result, the weight of the word will be a negative number, but large in magnitude.
- The word “scenario” can occur with the same probability in both positive and negative reviews, so the ratio P t / N t will be very close to one, and as a result the logarithm will be close to zero. The weight of the word will be almost zero.
As a result, the weight of words with a positive tonality will be a large positive number, the weight of words with a negative tonality will be a negative number, the weight of neutral words will be close to zero. Such a weighting of the feature vector in most cases makes it possible to improve the classification accuracy of tonality.
Implementation of the classifier
I implemented a simple classifier for the keynote of reviews on films on python. Data was collected from Kinopoisk . 500 positive and 500 negative reviews were selected. As a classification algorithm, I used the naive Bayes classifier (NB) and the support vector machine (SVM) method . As attributes, I tested unigrams, bigrams, and their combination, and as a weighing function: a binary function for bayes and SVM, and a delta TF-IDF for SVM. To assess the performance of the classifier, I conducted a cross-check : for each set of parameters 5 tests were run in a row, each of which used 800 reviews for training and 200 for testing. Below are the results (percent accuracy) for all 9 sets of parameters.
| Signs of | NB | SVM | SVM + delta |
|---|---|---|---|
| unigrams | 85.5 | 82.5 | 86.2 |
| bigrams | 84.9 | 86.5 | 87.8 |
| combination | 86.5 | 88.4 | 90.8 |

From the results it can be seen that for this collection the best results are shown by the support vector machine with the delta TF-IDF weighting function. If we use the usual binary function, then both classifiers (NB and SVM) show approximately the same results. The combination of unigrams and bigrams gives better results in all tests.
Let's see why the delta TF-IDF gives such a gap (2.4 - 4.3%) in the results. Choose N-grams with maximum modulo delta TF-IDF values:
| awesome | 5.20 | behave | -5.02 |
| depends | 5.08 | for some reason | -4.80 |
| takes | 4.95 | failed | -4.80 |
| create | 4.80 | not about | -4.71 |
| works | 4.80 | not impressed | -4.71 |
| carefully | 4.71 | having sex | -4.71 |
| myself | 4.71 | worse than | -4.71 |
| Kim | 4.62 | but this | -4.71 |
| thrillers | 4.62 | was filmed | -4.62 |
| for her | 4.51 | do not look | -4.62 |
On the example of negative N-grams, it is especially noticeable that their weight reflects a negative tonality.
Practical use
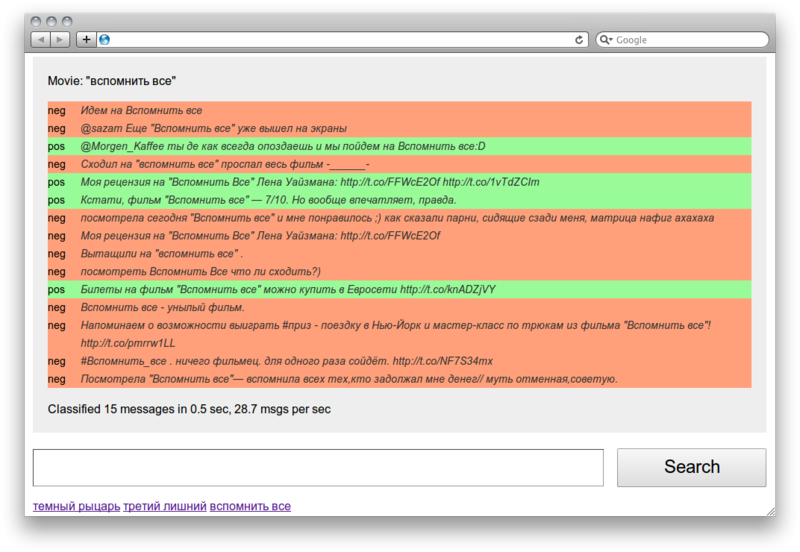
As an example of the practical application of the tonality classifier, I have quickly implemented a tweet classifier, the scheme of which is as follows:
- search Twitter for movie titles
- pass tweets through the tonality classifier
- we get positive and negative comments about movies from Twitter
An example of the analyzer:
alexpak@dard:~/projects/pyrus$ src/sentiment/test.py "" 1. pos ! / Sur la piste du Marsupilami (2012) DVDRip http://t.co/to5EuTHL 2. neg ! (2012)! 3. pos " ! " 4. pos ! . :) 5. pos ! - Sur la piste du Marsupilami (2012) HDRip http://t.co/UB1hwnHh 6. pos , . , ) 7. pos # 8. pos Went to the movies) watched the movie " ! ." http://t.co/EBlIsWMs 9. neg ) 10. neg ?! 11. pos ! / Sur la piste du Marsupilami (2012) http://t.co/OoH3chso 12. pos ! http://t.co/rb1BWurX 13. pos ! http://t.co/rHorvtvu 14. pos ! http://t.co/xNBHadIN 15. pos ! http://t.co/33t35O35 As you can see, the results are not particularly satisfactory. The categorizer makes 2 types of errors:
- Categorizes neutral tweets (movie description, news, spam) as positive / negative
- Incorrectly classifies the tonality of reviews
The first type of errors can be corrected by adding an additional classifier that will filter neutral tweets. This is not an easy task, but quite feasible. The second type of errors arises mainly due to the fact that tweets are very different from the collection of learning: there is slang, spelling errors, different manner of expression. Here you have to either look for another collection for classifier training (take the same tweets, for example), or improve the set of features (for example, add smiles). But in general, this example shows that it is quite possible to create a system for analyzing opinions on Twitter.
Conclusion
Creating a system for analyzing opinions is a difficult task, but quite feasible if there is data for training and a domain (topic) is predetermined. When using machine learning, it is important to test different parameters in order to select those that work better on test data. (NB, SVM), (, , N-), . , , (, ), (, .). .
, .
Source
FAQ:
!
— ,
, ?
—
?
— ( ?)
Source: https://habr.com/ru/post/149605/
All Articles