Overview of High Availability Architecture and SQL Database (SQL Azure)
Windows Azure offers both NoSQL repositories and SQL relational repositories. NoSQL storage is, for example, Windows Azure Tables (key \ value) or blobs (binary data such as photos, videos, documents, etc.). Relational repositories include SQL Database (formerly SQL Azure ).
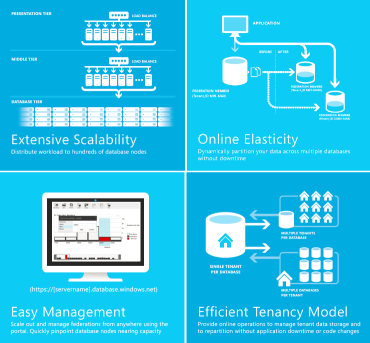
The post was prepared on the basis of the article Inside Windows Azure SQL Database , which it decided to split into two parts. In the first part, I will provide information about the SQL Database architecture and how high availability is ensured (fault detection, reconfiguration). In the second part I will talk about scalability (performance regulation, load balancing), as well as give recommendations for developers.
SQL Database is a shared cloud database, it can be said that it is Database as Service (DaaS). Microsoft Data Centers have large - capacity SQL Server installed based on standard hardware. Each SQL Server in the data center contains several different client databases (logical databases), i.e. It turns out the shared mode. Data access uses automatic load balancing and network connection routing.
')
It is worth noting that, physically or in fact, data are not stored in one database, but are replicated . Data is replicated in three SQL Server databases distributed across three physical servers of the same data center: one primary and two additional replicas. All read and write operations are performed in the main replica, and any changes are replicated asynchronously to additional replicas. These replicas provide high availability of SQL Database databases. Most Microsoft data centers contain hundreds of computers with hundreds of instances of SQL Server that host SQL Database replicas. It is extremely unlikely that the main and additional replicas of the SQL Database will be stored on the same computers.
A logical server is a SQL Database server that you see on the Windows Azure Management Web Portal. The SQL Database Gateway service acts as a proxy server, redirecting tabular data stream (TDS) requests to a logical server. SQL Database Gateway is a security boundary that provides credential verification, firewall compliance, and protection of SQL Server instances located behind the gateway against denial of service attacks. The gateway consists of many computers, each of which accepts requests for network connections from clients, checks the connection information and sends a request for the tabular data stream to the corresponding physical server, depending on the database name specified in the connection.

The physical distribution of databases that are part of the same logical instance of SQL Server means that each network connection is tied to one database, and not to one instance of SQL Server. If the USE command were used to connect, the tabular data stream would have to be redirected to a completely different physical computer in the data center. For this reason, the USE command is not supported for SQL Database connections.
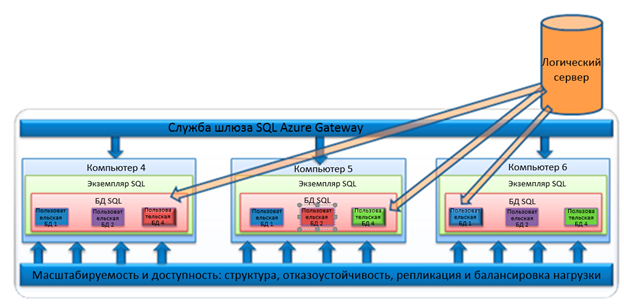
The application uses a client tier for direct data exchange with SQL Database. The client tier can be located in the local data center or hosted in Windows Azure. All protocols that generate tabular data streams for transmission over the network are supported. You can use familiar tools and libraries to create client applications that use data in the cloud.
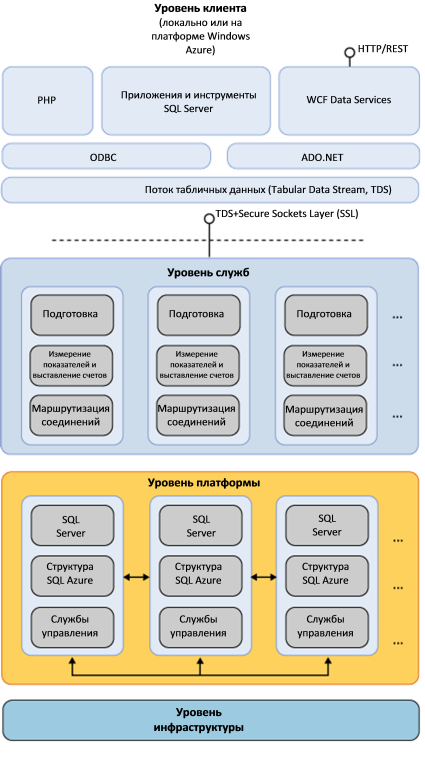
The service layer consists of computers that host gateway services that provide routing, resource allocation, metering, and billing. These services are supported by four groups of computers.
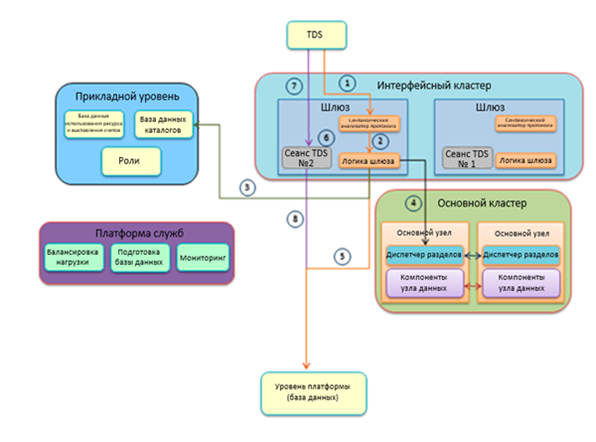
The interface cluster contains the physical computers of the gateway. Application-level computers authorize requests to the server and to the database, as well as manage billing. Service platform computers monitor and manage the health of SQL Server instances in the data center. The primary cluster computers keep track of which replicas of which particular databases physically exist in each instance of SQL Server in the data center.
The numbered lines of workflows in the figure reflect the procedure for checking and creating a client connection:
The platform tier consists of computers that host SQL Server physical databases in the data center. These computers are called data nodes. The figure shows the internal organization of data nodes. Each data node consists of one instance of SQL Server. Each of these instances has one user database, divided into sections. Each section contains one SQL Database client database, represented as a primary or secondary replica.
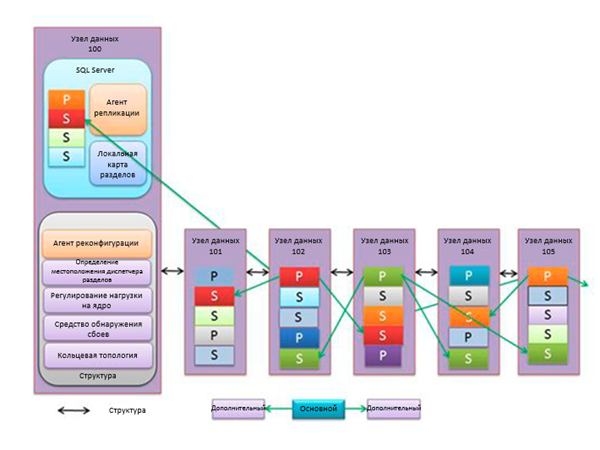
A SQL Server database of a typical data node can contain up to 650 partitions. These databases located in the data center are managed in the same way as local SQL Server databases. The only difference is that regular maintenance and backups are performed by data center specialists. All databases hosted on a data node use the same log file . This improves logging performance with sequential group I / O. Unlike local databases, SQL Database logs are stored in previously allocated and zeroed disk space. This avoids recording pauses while automatically increasing the size of the log files.
Another difference in managing logs in a SQL Database data center is the need for quorum commit . This means that the primary replica and at least one of the additional replicas must confirm that the log files have been written before the transaction is considered committed.
The figure shows that each of the data node computers contains a set of processes, also called a structure. The structure processes serve to solve the following tasks:
The Microsoft SQL Database platform ensures the availability of subscriber databases at the level of 99.9%. This is achieved through the use of consumer equipment, which allows simple and fast replacement in the event of a computer or drive failure, as well as by managing replicas of each of the SQL Database databases (one main and two additional replicas are supported).
It is necessary to identify not only cases of complete failure of computers, but also trends for slow degradation of computer performance and disruption of data exchange with them. The above concept of quorum fixation allows us to solve these problems. First, a transaction is not considered committed if the primary replica and at least one additional replica do not confirm the transaction entry in the log. Secondly, if the primary and secondary replicas confirm a successful recording, small failures can be detected that do not prevent the transaction from committing but can lead to serious problems.
The procedure for replacing corrupted replicas is called reconfiguration . Reconfiguration may be required when hardware failures or operating system crashes, as well as in the event of a problem with an instance of SQL Server. Reconfiguration is also used when upgrading the operating system, SQL Server or SQL Database platform.
The performance monitoring of each node is performed by six similar nodes located in different racks. These nodes are called neighbors. The failure is fixed by one of the neighbors of the failed node. For each database that stored a replica on the failed node, a reconfiguration procedure is performed. Each computer contains replicas of hundreds of SQL Database databases, some of which are primary and some additional. Therefore, in the event of a node failure, hundreds of reconfiguration operations are performed. When processing hundreds of errors caused by a node failure, prioritization is not used. The partition manager randomly selects a replica for processing, after completing operations on it, selects the next one, and so on until all replicas from the failed node are processed.
If a node shuts down due to a reboot, this is considered a pure failure, since the neighbors of the node receive an exception message.
Another possible option is to stop communicating with the computer for an unknown reason, when an unspecified error is fixed. In this case, the procedure of arbitration is applied, which allows to reliably determine the fact of node failure.
In addition to determining the failure of an individual replica, the system identifies and eliminates the consequences of failures of entire nodes. A node consists of a whole instance of SQL Server with several partitions containing replicas of up to 650 different databases. Some replicas are essential, others are optional. In the event of a site failure, the procedure described earlier is performed on each of the affected databases. For some databases with failed primary replicas, the arbitration process selects a new primary replica from the existing additional replicas, and for other databases with failed additional replicas, a new additional replica is created.
Most SQL Database replicas should commit. Currently, user databases support three replicas. Therefore, the quorum fixation of a replica requires confirmation of the transaction with two other replicas. The metadata repository included in the data center gateway components supports five replicas. He needs three confirmations for quorum fixation. The main cluster, which supports seven replicas, needs confirmation of four of them to commit the transaction. Information of the main cluster can be restored even in case of failure of all seven replicas. There are mechanisms for automated recovery of the main cluster with such large-scale failures.
Main replica failure
All read and write operations are first performed in the main replica. Therefore, the failure of the main replica is detected immediately and prevents further work. When reconfiguring in the event of a primary replica failure, the partition manager selects one of the additional replicas and assigns it to the primary one. As a rule, an additional replica on the node with the lowest workload is selected as the new primary replica. The procedure of assigning an additional replica of the main status does not cause database downtime and is not noticeable for most users. The gateway will send a disconnect message to the client application, after which the application should immediately attempt to reconnect. It may take up to 30 seconds for the new main replica to spread across all gateway servers. Therefore, it is recommended to try to re-connect several times, making small pauses after each unsuccessful attempt.
Additional replica failure
If the additional replica fails, the database will have only two replicas for quorum commit. The reconfiguration procedure is similar to the procedure that is performed after the failure of the primary replica, when the status of one of the additional replicas rises to the primary. In both cases, only one additional replica remains. After a short wait, the partition manager attempts to determine if this failure is permanent in order to create a new additional replica.
In some cases, such as when a failure or update of the operating system, the failure of an additional replica may be seemingly inherent. The inoperability of an additional replica on a failed node can only be temporary. Therefore, instant creation of a new replica does not occur. If the additional replica returns to a working state, data verification commands (checkdisk, etc.) are executed to confirm the replica's health.
If the replica remains inoperative for more than two hours, the partition manager proceeds to create a new replica to replace it. In some cases, such a fixed wait time is not the optimal solution, for example, if a computer fails due to an unrecoverable hardware failure. New editions of the SQL Database platform may contain functions for determining various types of replica failures, as well as be able to more quickly eliminate the consequences of unrecoverable failures.
If a non-recoverable node failure occurs, then to create a new additional replica, one of the cluster computers is selected with sufficient disk space and processor performance margin. This computer is used to host a new additional replica. The database is copied from the primary replica, then this copy is connected to the existing configuration. The time required to copy the entire contents of the database is the limiting factor for the maximum size of the managed SQL Database databases.
All computers in the data center are consumer computing systems with an average level of performance and quality components. At the time of this writing - 32 GB of RAM, an eight-core processor and 12 disks. The cost of such a system was about $ 3,500. Cost-effective and affordable configuration simplifies the quick replacement of computers in case of fatal failures. Windows Azure uses the same consumer equipment. This makes all the computers in the data center interchangeable, regardless of whether they are used to support SQL Database or Windows Azure.
In total, the distribution of database replicas across different servers and efficient algorithms for assigning additional replicas of the status of the main ones guarantee accessibility even with a simultaneous failure of 15% of all data center computers. That is, in case of failure of up to 15% of all computers, the level of supported workload will not decrease.
The story about SQL Database does not end there, there will be a continuation (there is a continuation ).
Ps. If someone liked the title picture, then here is a link to a large poster .
The post was prepared on the basis of the article Inside Windows Azure SQL Database , which it decided to split into two parts. In the first part, I will provide information about the SQL Database architecture and how high availability is ensured (fault detection, reconfiguration). In the second part I will talk about scalability (performance regulation, load balancing), as well as give recommendations for developers.
SQL Database Architecture Overview
SQL Database is a shared cloud database, it can be said that it is Database as Service (DaaS). Microsoft Data Centers have large - capacity SQL Server installed based on standard hardware. Each SQL Server in the data center contains several different client databases (logical databases), i.e. It turns out the shared mode. Data access uses automatic load balancing and network connection routing.
')
It is worth noting that, physically or in fact, data are not stored in one database, but are replicated . Data is replicated in three SQL Server databases distributed across three physical servers of the same data center: one primary and two additional replicas. All read and write operations are performed in the main replica, and any changes are replicated asynchronously to additional replicas. These replicas provide high availability of SQL Database databases. Most Microsoft data centers contain hundreds of computers with hundreds of instances of SQL Server that host SQL Database replicas. It is extremely unlikely that the main and additional replicas of the SQL Database will be stored on the same computers.
A logical server is a SQL Database server that you see on the Windows Azure Management Web Portal. The SQL Database Gateway service acts as a proxy server, redirecting tabular data stream (TDS) requests to a logical server. SQL Database Gateway is a security boundary that provides credential verification, firewall compliance, and protection of SQL Server instances located behind the gateway against denial of service attacks. The gateway consists of many computers, each of which accepts requests for network connections from clients, checks the connection information and sends a request for the tabular data stream to the corresponding physical server, depending on the database name specified in the connection.
The physical distribution of databases that are part of the same logical instance of SQL Server means that each network connection is tied to one database, and not to one instance of SQL Server. If the USE command were used to connect, the tabular data stream would have to be redirected to a completely different physical computer in the data center. For this reason, the USE command is not supported for SQL Database connections.
Network topology
The application uses a client tier for direct data exchange with SQL Database. The client tier can be located in the local data center or hosted in Windows Azure. All protocols that generate tabular data streams for transmission over the network are supported. You can use familiar tools and libraries to create client applications that use data in the cloud.
Service level
The service layer consists of computers that host gateway services that provide routing, resource allocation, metering, and billing. These services are supported by four groups of computers.
The interface cluster contains the physical computers of the gateway. Application-level computers authorize requests to the server and to the database, as well as manage billing. Service platform computers monitor and manage the health of SQL Server instances in the data center. The primary cluster computers keep track of which replicas of which particular databases physically exist in each instance of SQL Server in the data center.
The numbered lines of workflows in the figure reflect the procedure for checking and creating a client connection:
- A gateway in the front-end cluster that received a request for a new incoming connection to transmit a tabular data stream (TDS) can establish a connection with the client. A parser with a minimum set of supported functions checks the validity of the received command to transfer to the database. Commands like CREATE DATABASE are not allowed, as they must be processed by the application layer.
- The gateway performs the SSL handshake for the client. If the client refuses to use SSL, the gateway disconnects. It is necessary to provide full encryption of traffic. The protocol parser also contains a Denial of Service attack protection tool that monitors requests from IP addresses. If an excessive number of requests comes from an IP address or a range of addresses, then subsequent attempts to connect from these addresses will be rejected.
- The user-specified server name and login credentials should be verified. Check at the firewall level ensures connection only with IP addresses from specified ranges.
- After checking the server, the primary cluster matches the database name used by the client with the internal database name. A primary cluster is a collection of computers that process mapping information. When working in SQL Database, the concept of a section has a completely different meaning than when working with local SQL Server instances. In a SQL Database environment, a partition is part of a SQL Server database in a data center that maps to a single SQL Database database. For example, in the figure, each database contains three sections, since each of them contains three SQL Database databases.
- Once the database is discovered, the username is authenticated; if the check fails, the connection is broken. The gateway checks for the database to which the user wants to connect.
- A new connection can be made after checking all the connection parameters.
- A new connection is established directly between the user's computer and the internal server node.
- After the connection is established, the gateway acts as a proxy server for packets transmitted between the client and the data processing platform.
Platform level
The platform tier consists of computers that host SQL Server physical databases in the data center. These computers are called data nodes. The figure shows the internal organization of data nodes. Each data node consists of one instance of SQL Server. Each of these instances has one user database, divided into sections. Each section contains one SQL Database client database, represented as a primary or secondary replica.
A SQL Server database of a typical data node can contain up to 650 partitions. These databases located in the data center are managed in the same way as local SQL Server databases. The only difference is that regular maintenance and backups are performed by data center specialists. All databases hosted on a data node use the same log file . This improves logging performance with sequential group I / O. Unlike local databases, SQL Database logs are stored in previously allocated and zeroed disk space. This avoids recording pauses while automatically increasing the size of the log files.
Another difference in managing logs in a SQL Database data center is the need for quorum commit . This means that the primary replica and at least one of the additional replicas must confirm that the log files have been written before the transaction is considered committed.
The figure shows that each of the data node computers contains a set of processes, also called a structure. The structure processes serve to solve the following tasks:
- Failure detection: monitoring the availability of primary or secondary replicas; if they become unavailable, a reconfiguration agent may be started.
- Reconfiguration Agent: Manages the re-creation of primary or secondary replicas after a node failure.
- Determining the location of a partition manager: provides the sending of messages to the partition manager.
- Kernel load control: prevents the logical server from using the node's resources or exceeding its physical limits.
- Ring Topology: manages cluster computers in a logical ring; Each computer has two neighbors that can detect its emergency shutdown.
Ensuring high availability in SQL Database
The Microsoft SQL Database platform ensures the availability of subscriber databases at the level of 99.9%. This is achieved through the use of consumer equipment, which allows simple and fast replacement in the event of a computer or drive failure, as well as by managing replicas of each of the SQL Database databases (one main and two additional replicas are supported).
Crash Detection
It is necessary to identify not only cases of complete failure of computers, but also trends for slow degradation of computer performance and disruption of data exchange with them. The above concept of quorum fixation allows us to solve these problems. First, a transaction is not considered committed if the primary replica and at least one additional replica do not confirm the transaction entry in the log. Secondly, if the primary and secondary replicas confirm a successful recording, small failures can be detected that do not prevent the transaction from committing but can lead to serious problems.
Reconfiguration
The procedure for replacing corrupted replicas is called reconfiguration . Reconfiguration may be required when hardware failures or operating system crashes, as well as in the event of a problem with an instance of SQL Server. Reconfiguration is also used when upgrading the operating system, SQL Server or SQL Database platform.
The performance monitoring of each node is performed by six similar nodes located in different racks. These nodes are called neighbors. The failure is fixed by one of the neighbors of the failed node. For each database that stored a replica on the failed node, a reconfiguration procedure is performed. Each computer contains replicas of hundreds of SQL Database databases, some of which are primary and some additional. Therefore, in the event of a node failure, hundreds of reconfiguration operations are performed. When processing hundreds of errors caused by a node failure, prioritization is not used. The partition manager randomly selects a replica for processing, after completing operations on it, selects the next one, and so on until all replicas from the failed node are processed.
If a node shuts down due to a reboot, this is considered a pure failure, since the neighbors of the node receive an exception message.
Another possible option is to stop communicating with the computer for an unknown reason, when an unspecified error is fixed. In this case, the procedure of arbitration is applied, which allows to reliably determine the fact of node failure.
In addition to determining the failure of an individual replica, the system identifies and eliminates the consequences of failures of entire nodes. A node consists of a whole instance of SQL Server with several partitions containing replicas of up to 650 different databases. Some replicas are essential, others are optional. In the event of a site failure, the procedure described earlier is performed on each of the affected databases. For some databases with failed primary replicas, the arbitration process selects a new primary replica from the existing additional replicas, and for other databases with failed additional replicas, a new additional replica is created.
Most SQL Database replicas should commit. Currently, user databases support three replicas. Therefore, the quorum fixation of a replica requires confirmation of the transaction with two other replicas. The metadata repository included in the data center gateway components supports five replicas. He needs three confirmations for quorum fixation. The main cluster, which supports seven replicas, needs confirmation of four of them to commit the transaction. Information of the main cluster can be restored even in case of failure of all seven replicas. There are mechanisms for automated recovery of the main cluster with such large-scale failures.
Main replica failure
All read and write operations are first performed in the main replica. Therefore, the failure of the main replica is detected immediately and prevents further work. When reconfiguring in the event of a primary replica failure, the partition manager selects one of the additional replicas and assigns it to the primary one. As a rule, an additional replica on the node with the lowest workload is selected as the new primary replica. The procedure of assigning an additional replica of the main status does not cause database downtime and is not noticeable for most users. The gateway will send a disconnect message to the client application, after which the application should immediately attempt to reconnect. It may take up to 30 seconds for the new main replica to spread across all gateway servers. Therefore, it is recommended to try to re-connect several times, making small pauses after each unsuccessful attempt.
Additional replica failure
If the additional replica fails, the database will have only two replicas for quorum commit. The reconfiguration procedure is similar to the procedure that is performed after the failure of the primary replica, when the status of one of the additional replicas rises to the primary. In both cases, only one additional replica remains. After a short wait, the partition manager attempts to determine if this failure is permanent in order to create a new additional replica.
In some cases, such as when a failure or update of the operating system, the failure of an additional replica may be seemingly inherent. The inoperability of an additional replica on a failed node can only be temporary. Therefore, instant creation of a new replica does not occur. If the additional replica returns to a working state, data verification commands (checkdisk, etc.) are executed to confirm the replica's health.
If the replica remains inoperative for more than two hours, the partition manager proceeds to create a new replica to replace it. In some cases, such a fixed wait time is not the optimal solution, for example, if a computer fails due to an unrecoverable hardware failure. New editions of the SQL Database platform may contain functions for determining various types of replica failures, as well as be able to more quickly eliminate the consequences of unrecoverable failures.
If a non-recoverable node failure occurs, then to create a new additional replica, one of the cluster computers is selected with sufficient disk space and processor performance margin. This computer is used to host a new additional replica. The database is copied from the primary replica, then this copy is connected to the existing configuration. The time required to copy the entire contents of the database is the limiting factor for the maximum size of the managed SQL Database databases.
All computers in the data center are consumer computing systems with an average level of performance and quality components. At the time of this writing - 32 GB of RAM, an eight-core processor and 12 disks. The cost of such a system was about $ 3,500. Cost-effective and affordable configuration simplifies the quick replacement of computers in case of fatal failures. Windows Azure uses the same consumer equipment. This makes all the computers in the data center interchangeable, regardless of whether they are used to support SQL Database or Windows Azure.
In total, the distribution of database replicas across different servers and efficient algorithms for assigning additional replicas of the status of the main ones guarantee accessibility even with a simultaneous failure of 15% of all data center computers. That is, in case of failure of up to 15% of all computers, the level of supported workload will not decrease.
The story about SQL Database does not end there, there will be a continuation (there is a continuation ).
Ps. If someone liked the title picture, then here is a link to a large poster .
Source: https://habr.com/ru/post/149505/
All Articles