Search@Mail.Ru. Part one
“We have our own search!”
Two years in a row I began all my presentations at conferences with this phrase, because not even all search specialists knew that their queries specified in the Mail.Ru search box were most likely processed not by a licensed third-party engine, but by the internal development of the company.
Now I see that the situation has changed: many people know and accept our search engine. However, questions or doubts still remain - well, how is it that Mail.Ru Group writes its search? Mail.Ru Group is mail, social networks, entertainment ... What search engine can they write? In order to dispel these doubts, I want to tell you about our search, about how we are doing it, what technologies we use, what we want to get in the end. I hope that the proposed article will be informative and interesting; Moreover, we are going to continue the story about our technologies in more detail, and in the following posts we will talk about machine learning, spider, antispam, etc.
GoGo.Ru
')
The Mail.Ru search engine began to be developed in 2004 by Mikhail Kostin, the former head of the aport.ru search engine. In 2007, the search engine was submitted under the name GoGo on the domain gogo.ru.

Even then, GoGo had quite interesting properties: it could limit the search to commercial and informational sites, as well as forums and blogs. After some time, it appeared in the search for pictures and the first in runet search for video.
Much attention in it was paid to the ranking and optimization of the execution time of search queries. For example, the GoGo text ranking formula participated in the ROMIP contest (Russian seminar on the evaluation of information retrieval methods), where it showed the best results among all participants (see www.romip.ru/romip2005/09_mail.ru.pdf ).
From GoGo - to Go.Mail.Ru
All this time, requests that are entered on the main page of the Mail.Ru portal have been performed by a licensed search engine; at first it was a Google engine, then Yandex. But in 2009, the contract with Yandex ended, and it was decided to try its own search engine on January 1, 2010.
Later we entered into a partnership with the search engine Google on the following conditions: some of the requests are processed by Google, another - by us. But this happened only in August 2010, and for eight months, Search worked completely on its own engine.
From the point of view of developers, this meant completely different search requirements: if before gogo.ru served hundreds of thousands of queries per day, now it needed to serve tens of millions. The anticipated increase in load by two orders required new architectural solutions. The most significant change was the rise of the reverse index into RAM: before it lay on the hard disk, which made it impossible to meet the required response time up to 300 milliseconds per request. And for all the changes, the development team had only a few months; on January 1, 2010, a new search engine was supposed to work and serve the requests of Mail.Ru users.
Such a task belongs to the “mission impossible” class, but the developers performed a labor feat and successfully coped with it: switching to a new search engine occurred at 0:00 on January 1, 2010. The first commit to the Search repository, correcting one of the newly discovered problems, occurred already at three o'clock on New Year's Eve. And after that, while most of the country was on New Year's holidays, the Search team, as they say, “kept the sky”, constantly finding and fixing a variety of bugs.
Problems with the stability of the Search arose and were solved throughout the year, but the first three months were the most intense and demanded the maximum return from all search engine developers. At the same time, they could finally put out the fire, probably, only by August 2010. After this, the search finally began to live a normal life, and the developers were able to switch to more long-term tasks than correcting another critical problem. In particular, it was possible to think about how much the current search architecture corresponds to the tasks before us.
What we had: a historical background for 2010
In 2010, an internal presentation about the search architecture schematically showed it in the following way:
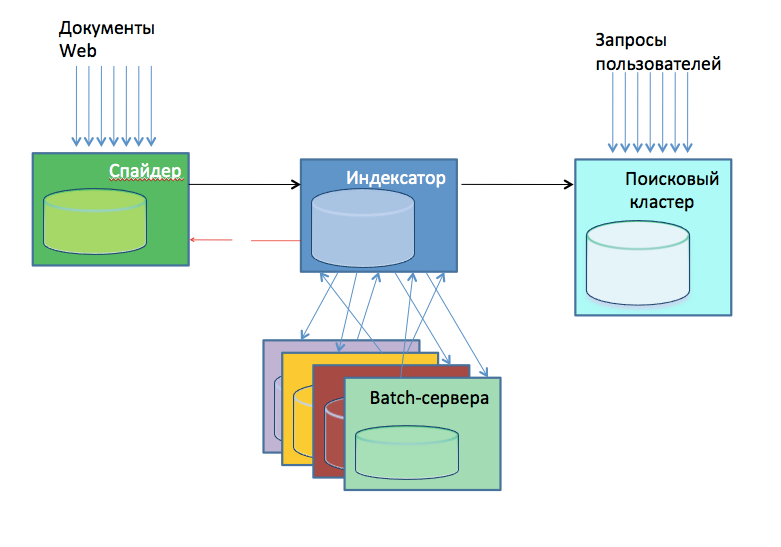
- Spider, shakes the web. These are 24 servers, each pumping each part of the web. What part to obkachivat, was determined by the hash on behalf of the domain. The spiders contained the base of the downloaded pages, and they themselves determined what to download and what not.
- Indexers, create ready-made database indexes. There were also about 30 of them at the end of 2010. In addition to directly indexing, they performed the analysis of incoming pages for spam, pornography, etc., selected the data of interest for the calculation, for example, links for the subsequent construction of the citation index.
- Batch-servers (about 20 pieces) that perform external data calculations, the same IC. The calculations were very diverse: some were fast, some were slow.
- Search cluster, one hundred and fifty servers. Took databases from indexers and directly performed user search queries.
In 2010, it became clear that there are quite a few architectural flaws in the organization of data storage and processing: The search quickly evolved from the state of “several dozen servers” to “several hundred servers”, the amount of data being processed and the requirements for their processing speed began to increase, and the old ones methods no longer satisfy the urgent requirements for the quality of work. For example, the calculation of the citation index was made on one server and now it worked for a month. If the server rebooted during this time or the process did not have enough memory, then you had to start all over again; thus, the citation index at some point in time simply ceased to be updated.
The set of source data placed in the index was calculated on different servers, under different users and delivered to the index in some unique ways for this type of data. As a result, the developers were confused about where it comes from: several times we found out that certain factors “fell off” from the index a month ago for some reason, and no one has noticed it so far.
Developers often solved the same tasks: how to "cut" the input data in such a way that it would be possible to parallelize their computation on several disks, and then on several servers. All solutions were somewhat similar, but somewhat different from each other, and besides, developers often repeated the same thorny path of building a distributed computing system from scratch, which clearly did not contribute to effective development.
The big problem was the presence of two databases of documents: one for the spider, the other for the indexer. This led to a blurring of the decision regarding the fate of the same document - for example, the analysis of spam on the indexer could decide to throw the document out of the index, and the spider would continue to download it. Or, on the contrary, the spider could throw the document out of its base for some reason, but the command to remove the document from the index could not reach the indexer due to a technical failure, so the document remained in the index for a long time, before the next garbage collection.
It became clear that in order to continue the development of the search, a different, new approach was needed: we lacked a unified platform for distributed task execution, a high-performance database. It was necessary to make a choice between self-development and a ready-made solution, and, in the second case, to find an option that would suit us in terms of stability and would quickly work on our workloads.
In the next posts I will talk about how we developed and implemented this approach, as well as how other search engines work.
Andrey Kalinin,
Head of Mail.ru Search Developers
Source: https://habr.com/ru/post/149498/
All Articles