Available methods to combat DDoS attacks for owners of vds / dedicated servers with Linux
We decided to begin our presence at Habré with the material prepared for the Ural Web Developers Conference , which describes tried and tested methods of dealing with DDoS attacks that turned out to be quite successful. The target audience for this article is programmers who have vds or dedicated. The article does not claim to be a full-fledged guide and many sysadminian nuances in it are intentionally omitted. We consider only http flood DDoS as the most common type of DDoS and the cheapest for the customer.
The target audience for this article is programmers who have VDS or Dedicated at their disposal.
A bunch of nginx - apache - fastcgi / wsgi. Narrow places
A typical scheme for organizing the work of a web application consists of 3 levels: this is a reverse proxy server (for example, nginx), apache (web server) and some kind of fastcgi / wsgi / ... application. In practice, there are degenerate cases when there is no apache or when using mod_php / mod_python, when there is no dedicated application (it is embedded in the web server), but the essence of the scheme does not change, only the number of levels in it changes.
')
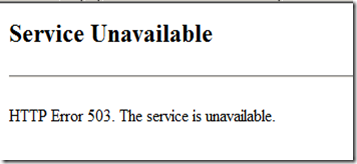
Fcgi server can run several dozen processes that process incoming requests in parallel. This value can be increased only up to a certain limit, while the processes are located in memory. A further increase will result in swapping. During a DDoS attack or high attendance, when all current fcgi processes are already busy processing incoming requests, apache queues new incoming requests until either one of the fcgi processes is released or the queue timeout occurs (in this case an error occurs 503).
Apache also has a limit on the number of connections, usually a few hundred (an order of magnitude more than fcgi). After all connections to apache are exhausted, requests are already placed in the queue by nginx.
Nginx, due to its asynchronous architecture, can easily keep several thousand connections with very modest memory consumption, so typical DDoS attacks do not reach the level when nginx is unable to accept new connections if nginx is configured accordingly.
Filtering traffic to nginx. Parsing nginx logs
The method proposed by us is reduced to limiting the total number of requests to the site by a certain value (for example, 1500 per minute, depending on how many hits the site engine can withstand the current server capacity). All that will exceed this value, we will initially filter using nginx (limit_req_zone $ host zone = hostreqlimit: 20m rate = 1500r / m;).
Then we will look into the nginx logs and calculate those IP addresses there that were filtered more than a certain number of times in a certain period of time (for example, more than 100 times in 5 minutes) and deny access to these IP addresses using a firewall.
Why we do not use the traditional and often recommended limit on connections from the same ip address (limit_req_zone $ binary_remote_addr ...)? Firstly, customers of providers sitting at nat will get under this limit. Secondly, it is impossible to establish a universal threshold value, because there are sites with ajax and a large number of js / css / pictures, which in principle can take several dozen hits to download one page, and such a threshold can be used only individually for each site. Thirdly, for the so-called “sluggish” DDoS attacks, bots will not fall under this threshold at all - there will be a lot of bots, but each of them alone will make few requests in a short period of time, as a result we will not be able to filter anything, and the site will not work.
In order to use our method, the nginx configuration file, when nginx acts as a reverse proxy for apache, should look something like this:
http { limit_req_zone $host zone=hostreqlimit:20m rate=1500r/m; ... server { listen 1.2.3.4; server_name domain.ru www.domain.ru; limit_req zone=hostreqlimit burst=2500 nodelay; location / { proxy_pass http://127.0.0.1:80; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $host; } } } This config also means that we have apache on the loopback interface at 127.0.0.1:80, and nginx on the 80th port on our external ip address (1.2.3.4) and on port 8080 on 127.0.0.1.
Hits filtered by nginx will be accompanied by the following entry in nginx's error.log:
2012/01/30 17:11:48 [error] 16862#0: *247484 limiting requests, excess: 2500.200 by zone "hostreqlimit", client: 92.255.185.237, server: domain.ru, request: "GET / HTTP/1.1", host: "domain.ru", referrer: "http://www.yahoo.com/" To get from error.log a list of all blocked ip-addresses, we can do the following:
cat error.log | awk '/hostreqlimit/ { gsub(", ", " "); print $14}' | sort | uniq -c | sort -n But we remember that in this case, we block all those who accessed the site after the count of hits counted 1500 times per minute, so not all blocked ones are bots. Bots, on the other hand, can be distinguished by drawing a conditional line on the number of locks. As a rule, a value is selected for the trait several hundred times in 5-15 minutes. For example, we update the list of bots once every 5 minutes and consider that everyone whom nginx has blocked more than 200 times is bots.
Now we face two problems:
- How to select the “last 5 minutes” period from the log?
- How to sort only those who have been blocked more than N times?
We solve the first problem with tail -c + OFFSET. The idea comes down to the fact that after parsing error.log we write its current size in bytes to the auxiliary file (stat -c '% s' error.log> offset), and at the next parsing we rewind error.log to the last viewed position (tail -c + $ (cat offset)). Thus, starting the analysis of logs every 5 minutes, we will view only the part of the log that belongs to the last 5 minutes.
We solve the second problem with the awk script. As a result, we get (THRESHOLD - this is the same limit for the number of locks, after which the corresponding IP address is considered to belong to the bot attacking us):
touch offset; (test $(stat -c '%s' error.log) -lt $(cat offset) 2>/dev/null && echo 0 > offset) || echo 0 > offset; \ tail -c +$(cat offset) error.log | awk -v THRESHOLD=200 '/hostreqlimit/ { gsub(", ", " "); a[$14]++; } \ END { for (i in a) if (a[i]>THRESHOLD) printf "%s\n", i; }' ; stat -c '%s' error.log > offset It is assumed that this set of commands is executed in the directory where error.log is from nginx, that is, as a rule, this is / var / log / nginx. The resulting list, we can send to the firewall to block (more on that below).
How easy it is to build a list of networks for a ban
Another task facing us with DDoS is to limit access to our site to those who are not its potential visitors as much as possible, because botnets can contain tens of thousands of computers and often cut off excess ip-addresses with whole subnets is much easier than catching each bot separately.
The first thing that can help us is the list of Runet networks on the NOC masterhost website. Currently, there are almost 5,000 networks on this list. Most Russian sites are focused on visitors from Russia, so cutting off all foreign visitors, and with it all foreign bots, looks like a logical decision. However, lately, more and more independent botnets have arisen within Russian networks, so this solution, although justified, very often does not protect against an attack.
If the site has an established community (core), then we can select the list of IP addresses of regular visitors from the web server logs for the last 3-4 weeks. Although new visitors will not be able to enter the site at the time of the attack, but old active users will most likely not even notice any attack. In addition, among the regular visitors are unlikely to be bots, so this method can, in principle, by itself, stop the attack for a while.
If the site is of local importance, then you can ban everything on the firewall except the networks of local providers and search engine networks (Yandex).
Introduction to iptables, an example of a simple firewall
On Linux, the firewall runs on iptables. In fact, the essence of the work of iptables is to ensure that for each packet of traffic received outside or sent from the server, a certain set of rules are applied that can affect the fate of this packet. In the simplest case, the rules simply say that the packet must either be accepted (ACCEPT) or discarded (DROP). The rules are divided into chains. For example, packets received by the server from the Internet fall into the INPUT chain, where for each packet from the very beginning of the rules in the chain it is checked whether the packet fits the conditions described in the rule and if so, this rule applies to the packet, and if not, the packet passed to the next rule. If none of the rules for the package has been applied, then the default policy (policy) is applied to the package.
As a simple example, let's write the firewall rules that allow connecting to the server via ssh only from our office (from the IP address 1.2.3.4), and for all others ssh access is blocked:
*filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -s 1.2.3.4/32 -m comment --comment "our office" -j ACCEPT -A INPUT -p tcp -m tcp --dport 22 -j DROP COMMIT These lines can be written to a text file and loaded into the firewall using: iptables-restore <firewall.txt, and save the current state of the firewall to the file: iptables-save> firewall.txt.
These rules work as follows. The first line - allow all traffic for all connections that are already open (the handshake procedure is passed). The second line - allow any traffic from ip-address 1.2.3.4 and mark it with a comment that this is our office. In fact, only packages that establish a connection can reach here, that is, packages of the syn and ack type, all other packages pass only the first line. The third line - we prohibit all connections via tcp to port 22. These are attempts to connect (syn, ack) via ssh from everyone except our office.
Interestingly, the first line can be safely removed. The advantage of having such a line is that for already open connections, the firewall will work out just one rule, and packages within already opened connections are the vast majority of the packets we receive, that is, the firewall with such a line will hardly introduce any additional delays at the very beginning into the server's network stack. Minus - this line leads to the activation of the conntrack module, which keeps in memory a copy of the table of all established connections. What is more expensive - to keep a copy of the connection table or the need to process several firewall rules for each packet? This is an individual nuance of each server. If the firewall contains only a few rules, in our opinion it is more correct to build its rules so that the conntrack module is not activated.
In iptables, you can create additional user-defined chains. In a sense, it looks like an analogue of a function call in programming languages. New chains are created simply: iptables -N chain_name. The chains thus created are used to separate the firewall into different logical blocks.
Recommended firewall structure for countering DDoS
The structure we recommend for countering DDoS consists of the following logical blocks:
- Allow traffic on already established connections.
- We register permissions for "our" ip-addresses.
- The whitelist table is an exception.
- The DDoS table is the bots we identified.
- The friends table is the networks of RuNet that we allow access to if the packet has reached this level.
- All the rest - -j DROP.
In iptables terms, it looks like this:
*filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] :ddos - [0:0] :friends - [0:0] :whitelist - [0:0] -A INPUT -i lo -j ACCEPT -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -s 1.2.3.4/32 -m comment --comment "our office" -j ACCEPT -A INPUT -p tcp -m tcp --dport 22 -j DROP -A INPUT -j whitelist -A INPUT -j ddos -A INPUT -j friends -A INPUT -j DROP -A whitelist -s 222.222.222.222 -j ACCEPT -A whitelist -s 111.111.111.111 -j ACCEPT -A ddos -s 4.3.2.0/24 -j DROP -A friends -s 91.201.52.0/22 -j ACCEPT COMMIT Again, the expediency of having the second row is questionable, and depending on the full size of the firewall, it can both speed up and slow down.
Fill in the friends table:
for net in $(curl -s http://noc.masterhost.ru/allrunet/runet); do iptables -A friends -s $net -j ACCEPT; done The problem of such a firewall in its monstrousness: the friends table in the case of the Runet will contain about 5000 rules. The DDoS table in the case of more or less average DDoS will contain 1-2 thousand more records. Total firewall will consist of 5-7 thousand lines. In this case, all packets arriving from overseas senders, which should be simply discarded, will actually go through all 5-7 thousand rules until they reach the last: -A INPUT -j DROP. By itself, such a firewall will eat off a huge amount of resources.
Ipset - solution for monstrous firewalls
Ipset completely solves the problem with a monstrous firewall, in which there are thousands of lines describing what to do with packets with different addresses of senders or recipients. Ipset is a utility for managing special set'ami (sets of the same type of data), where for several predefined data types special hash-tables are made, allowing you to very quickly determine whether a particular key is in or out of this table. In a sense, this is an analogue of memcached, but only much faster and allowing you to store only a few specific data types. Let's create a new data set to store information about the ip-addresses of DDoS bots:
ipset -N ddos iphash Here, the last parameter indicates the type of table being created: nethash is set for the list of networks, iphash is for individual ip addresses. There are different versions of the tables, details in the man ipset. Accordingly, whitelist and friends are tables like nethash, and DDoS is iphash.
To use the created ipset table in the firewall, one rule (firewall lines) is enough, for example:
-A INPUT -m set --match-set whitelist src -j ACCEPT -A INPUT -m set --match-set ddos src -j DROP You can add some ip-address to the newly created table like this:
ipset -A ddos 1.2.3.4 Thus, our entire firewall when using ipset comes down to:
*filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] -A INPUT -i lo -j ACCEPT -A INPUT -s 1.2.3.4/32 -m comment --comment "our office" -j ACCEPT -A INPUT -p tcp -m tcp --dport 22 -j DROP -A INPUT -m set --match-set whitelist src -j ACCEPT -A INPUT -m set --match-set ddos src -j DROP -A INPUT -m set --match-set friends src -j ACCEPT -A INPUT -j DROP COMMIT Fill in set friends (nethash type):
for net in $(curl -s http://noc.masterhost.ru/allrunet/runet); do ipset -A friends $net; done Fill in the set ddos from the command shown earlier:
touch offset; (test $(stat -c '%s' error.log) -lt $(cat offset) 2>/dev/null && echo 0 > offset) || echo 0 > offset; \ for ip in $(tail -c +$(cat offset) error.log | awk -v THRESHOLD=300 \ '/hostreqlimit/ { gsub(", ", " "); a[$14]++; } END { for (i in a) if (a[i]>THRESHOLD) printf "%s\n", i; }' ; \ stat -c '%s' error.log > offset); do ipset -A ddos $ip; done We use the TARPIT module
The iptables module called tarpit is a so-called “trap”. The principle of operation of tarpit is as follows: the client sends a syn-package to attempt to install handshake (the beginning of the installation of a tcp connection). Tarpit responds with a syn / ack package, which is immediately forgotten. However, no connection is actually opened and no resources are allocated. When the final ACK packet arrives from the bot, the tarpit module sends a packet back, setting the window size for transmitting data to the server to zero. After that, any attempts to close this connection from the side of the tarpit bot are ignored. The client (bot) thinks that the connection is open, but “stuck” (window size is 0 bytes) and tries to close this connection, but he cannot do anything until the timeout expires, and the timeout, depending on the settings, is about 12-24 minutes
You can use tarpit in a firewall as follows:
-A INPUT -p tcp -m set --match-set ddos src -j TARPIT --tarpit -A INPUT -m set --match-set ddos src -j DROP We collect xtables-addons
Unfortunately, the ipset and tarpit modules are absent in the standard set of modern distributions. They need to be installed additionally. For more or less recent distributions of Debian and Ubuntu, this is done simply:
apt-get install module-assistant xtables-addons-source ma ai xtables-addons After that, the system itself will download everything needed to build software, it will collect everything and install everything itself. For other Linux distributions, you need to take similar actions, but for specificity, we suggest referring to the reference guide.
Core tuning
As a rule, talk about combating DDoS attacks begins with recommendations on tuning the OS kernel. However, in our opinion, if in principle there are not enough resources (for example, if there is less than one GB of memory), then the kernel tune-up does not make sense, since it will give almost nothing. The maximum useful in this case will be - include the so-called. syncookies The inclusion of syncookies allows you to effectively deal with attacks of syn flood when the server is bombarded with a large number of syn-packets. When receiving a syn-package, the server must allocate resources to open a new connection. If the sync package is not followed by the continuation of the connection setup procedure, the server will allocate resources and wait until a timeout occurs (a few minutes). Ultimately, without syncookies, with a sufficient number of syn packets sent to the server, it can no longer accept connections, because the system will spend all its resources on storing information about half-open connections.
Kernel parameters, which will be discussed, are corrected using the sysctl command:
sysctl [-w] option The option -w means that you want to write a new value to some parameter, and its absence means that you want to read the current value of this parameter. It is recommended to correct the following parameters:
net.ipv4.tcp_syncookies=1 net.ipv4.ip_local_port_range = 1024 65535 net.core.netdev_max_backlog = 30000 net.ipv4.tcp_max_syn_backlog = 4096 net.core.somaxconn = 4096 net.core.rmem_default = 124928 net.core.rmem_max = 124928 net.core.wmem_max = 124928 - The net.ipv4.tcp_syncookies parameter is responsible for enabling the syncookies mechanism; net.core.netdev_max_backlog determines the maximum number of packets in the processing queue if an interface receives packets faster than the kernel can process them.
- net.ipv4.tcp_max_syn_backlog determines the maximum number of remembered connection requests for which no confirmation has been received from the connecting client.
- net.core.somaxconn maximum number of open sockets waiting for connections.
- The last lines are different buffers for tcp connections.
We hope that this article will be useful for owners of VDS or Dedicated servers. Please leave your comments and comments.
Source: https://habr.com/ru/post/149302/
All Articles