The seven deadly sins of a T-SQL programmer
It is not enough to write code well readable: it must also be quickly executed.
There are three basic rules for writing such T-SQL code that will work well. They are cumulative - the implementation of all these rules will have a positive impact on the code. Skipping or changing any of them will most likely lead to a negative impact on the performance of your code.
There are some common mistakes that people make in their T-SQL code — do not commit them.
In theory, to avoid this error is very simple, but in practice it is quite common. For example, you use some type of data in your database. Use it in your own parameters and variables! Yes, I know that SQL Server can implicitly convert one data type to another. But, when an implicit type conversion occurs, or you yourself cast the data type of a column to a different type, you perform the conversion for the entire column. When you do this conversion for a column in a WHERE clause or in a join condition, you will always see a table scan. An excellent index can be built on this column, but since you make a CAST for the values stored in this column to compare, for example, the date stored in this column, with the type of char you used in the condition, the index will not be used.
')
Do not believe? Let's look at this query:
Well written and very simple. It should be covered by the index created on this table. But here is the execution plan:

This query is executed fairly quickly and the table is small, so only four reads are required to scan the index. Notice the small exclamation point on the SELECT statement. If we refer to its properties, we will see:

Right. This is a warning (new in SQL Server 2012) that type conversion occurs that affects the execution plan. In short, this is because the query uses the wrong data type:
And we get the following query execution plan:

And here only two read operations are used, instead of four. And yes, I understand that I made a query that was running so fast a little bit faster. But what would happen if millions of rows were stored in the table? Yeah, then I would be a hero.
Use the correct data types.
Speaking of functions, most of the functions used in join conditions or WHERE clauses, to which you, as an argument, pass a column, interfere with the proper use of indexes. You will see how much slower queries are executed, in which functions are used that take columns as arguments. For example:
This function, LEFT, takes a column as an argument, which translates into this execution plan:

As a result, 316 read operations are performed to find the necessary data, and it takes 9 milliseconds (I have very fast disks). All because '4444' should match every line returned by this function. SQL Server cannot even simply scan the table, it needs to perform a LEFT for each row. However, you can do something like this:
And here we see a completely different implementation plan:

To perform the request requires 3 reads and 0 milliseconds. Well, or let it be 1 millisecond, for objectivity. This is a huge performance boost. And all because I used such a function that can be used to search by index (previously it was called sargeable - the word untranslatable, in general, the word: SARG - Search Arguments –able if the SARGeable function - you can pass a column into it argument and it will still be used Index Seek, if not SARGeable - alas, Index Scan will always be used - translator’s comment ). In any case, do not use functions in WHERE expressions or search conditions, or use only those that can be used in search conditions by index.
The multi-statement UDF in the Russian edition of msdn translates roughly as “User-defined functions consisting of several instructions, but this sounds, in my opinion, somehow strange, so I tried to avoid translating this term further into the heading - text . translator
In fact, they are driving you into a trap. At first glance, this wonderful mechanism allows us to use T-SQL as a real programming language. You can create these functions and call them one from another and the code can be reused, not like these old stored procedures. This is amazing. Until you try to run this code on a large amount of data.
The problem with these functions is that they are built on table variables. Table variables are a very cool thing if you use them for their intended purpose. They have one obvious difference from temporary tables - no statistics are built on them. This difference can be very useful, and maybe ... kill you. If you do not have statistics, the optimizer assumes that any query running on a table variable or UDF will return just one row. One (1) line. This is good if they do return multiple rows. But one day they will return hundreds or thousands of lines and you decide to connect one UDF to another ... Productivity will fall very, very quickly and very, very much.
An example is quite large. Here are a few UDFs:
Excellent structure. It allows you to make very simple requests. Well, for example, here:
One very simple request. Here is his execution plan, also very simple:
Here it is only executed 2.17 seconds, returns 148 lines and uses 1456 read operations. Please note that our function has a zero cost and only scanning a table, a table variable, affects the cost of the query. Hmm, is that right? Let's try to see what lies behind the zero-cost UDF execution operator. This query will get the execution plan for the function from the cache:
And that's what's really going on there:

Wow, it looks like there are a few more of these small functions and scans of tables that almost, but still not quite, cost nothing. Plus, the Hash Match connection operator, which writes to tempdb and is quite expensive when executed. Let's see another UDF execution plan:

Here! And now we see a Clustered Index Scan, which scans a large number of rows. This is not great. In general, in this whole situation, UDFs seem less and less attractive. What if we, well, I don’t directly know, just try to directly access the tables. So, for example:
Now, by running this query, we get exactly the same data, but in just 310 milliseconds, not 2170. Plus, SQL Server will perform only 911 read operations, not 1456. To be honest, it’s very easy to get performance problems using UDF
Returning to the past, to old computers with 286 processors on board, we can recall that for a number of reasons, they had a Turbo button on the front panel. If you accidentally "squeezed" it, then the computer immediately began to slow down insanely. Thus, you realized that some things should always be included to ensure maximum throughput. In the same way, many people look at the READ_UNCOMMITTED isolation level and the NO_LOCK hint as a turbo button for SQL Server. When using them, be sure that virtually any request and the entire system will become faster. This is due to the fact that during the reading no locks will be imposed and checked. Less locks - faster result. But…
When you use READ_UNCOMMITTED or NO_LOCK in your queries, you encounter dirty reads. Everyone understands that this means that you can read the "dog" and not the "cat" if at this moment the update operation is completed but not yet completed. But, besides this, you can get more or less rows than you actually have, as well as duplicate rows, since data pages can be moved during the execution of your query, and you do not impose any locks to avoid this. I do not know about you, but in most of the companies in which I worked, we expected that the majority of requests on most systems would return complete data. The same query with the same parameters, performed on the same data set, should give the same result. Only not if you use NO_LOCK. In order to verify this, I advise you to read this post .
People too quickly decide to use hints. The most common situation is when hint helps to solve one very rare problem on one of the queries. But when people see significant performance gains on this request ... they immediately start poking it generally everywhere.
For example, a lot of people think that a LOOP JOIN is the best way to join tables. They come to this conclusion because it is most often found in small and fast queries. Therefore, they decide to force SQL Server to use LOOP JOIN. It is not difficult at all:
This request takes 101 milliseconds and performs 4115 read operations. Not bad in general, but if we remove this hint, the same query will execute in 90 milliseconds and produce only 2370 readings. The more loaded the system is, the more obvious will be the effectiveness of the query without using hint.
Here is another example. People often create an index on a table, expecting it to solve the problem. So, we have a request:
The problem again is that when you perform a column transformation, no index will be adequately used. Performance drops as a clustered index scan is performed. And so, when people see that their index is not used, they do this:
And now they get a scan of their chosen index, not a clustered index, so the index is “used”, right? But the query performance changes - now, instead of 11 read operations, 44 are executed (the execution time for both is about 0 milliseconds, since I have really fast disks). “Used” is used, but not at all as intended. The solution to this problem is to rewrite the query in this way:
Now the number of read operations has fallen to two, since an index search is used - the index is used correctly.
Hints in requests should always be applied last, after all other possible options have been tested and have not given a positive result.
Line by line processing is performed using cursors or operations in the WHILE loop, instead of operations on sets. When using them, the performance is very, very low. Cursors are usually used for two reasons. The first is the developers who are used to using line-by-line processing in their code, and the second is the developers who came from Oracle, who think that cursors are a good thing. Whatever the reason, cursors - kill the performance on the vine.
Here is a typical example of unsuccessful use of the cursor. We need to update the color of products selected by a specific criterion. It is not invented - it is based on a code that I once had to optimize.
In each iteration, we perform two read operations, and the number of products that meet our criteria is in the hundreds. On my machine, without load, the execution time is more than a second. This is completely unacceptable, especially since rewriting this query is very simple:
Now, only 15 read operations are performed and the execution time is only 1 millisecond. Do not laugh. People often write such code and even worse. Cursors are such a thing that should be avoided and used only where you cannot do without them - for example, in maintenance tasks where you need to run through different tables or databases.
Views that refer to views, connect to views, link to other views, connect to views ... A view is just a query. But since they can be treated as tables, people can start thinking of them as tables. And in vain. What happens when you connect one view to another, referring to a third view, and so on? You just create a damn complicated query execution plan. The optimizer will try to simplify it. He will try plans that do not use all the tables, but the time to work on the choice of the plan is limited and the more complex the plan he gets, the less likely he is to have a fairly simple execution plan. And performance problems will be almost inevitable.
Here, for example, is a sequence of simple queries defining views:
And here the author of the text forgot to specify the request, but he quotes it in the comments (approx. Translator):
As a result, our request executes 155 milliseconds and uses 965 read operations. Here is his execution plan:

It looks good, especially since we get 7,000 lines, so everything seems to be in order. But what if we try to execute the following query:
And now the request is executed in 3 milliseconds and uses 685 read operations - quite different. And here is his execution plan:

As you can see, the optimizer cannot throw out all unnecessary tables as part of the query simplification process. Therefore, in the first execution plan there are two unnecessary operations - Index Scan and Hash Match, which collects data together. You could save SQL Server from unnecessary work by writing this query without using views. And remember - this example is very simple, most requests in real life are much more complicated and lead to much bigger performance problems.
In the comments to this article there is a small dispute, the essence of which is that Grant (the author of the article) did seem to fulfill his requests not on the standard AdventureWorks database, but on a similar database, but with a slightly different structure, which is why the execution plan is “not optimal” “The query in the last section is different from what you can see by conducting the experiment yourself. Note translator.
If somewhere I was too stupid (and I can) and the text is difficult to understand, or you can offer me the best wording for anything, I’ll be happy to hear all the comments.
There are three basic rules for writing such T-SQL code that will work well. They are cumulative - the implementation of all these rules will have a positive impact on the code. Skipping or changing any of them will most likely lead to a negative impact on the performance of your code.
- Write on the basis of the data storage structure: if you are storing datetime data, use datetime, not varchar or anything else.
- Write based on the presence of indices: if there are indexes on the table, and they should be there, write the code so that it can use all the advantages provided by these indices. Make sure that the clustered index, and for each table it can be only one, is used in the most efficient way.
- Write to help the query optimizer: the query optimizer is a delightful part of the DBMS. Unfortunately, you can make it very difficult for him to write a request that will be “hard” for him to parse, for example, containing nested views — when one view receives data from another, and then from the third — and so on. Spend your time to understand how the optimizer works and write queries so that it can help you, and not harm.
There are some common mistakes that people make in their T-SQL code — do not commit them.
Using wrong data types
In theory, to avoid this error is very simple, but in practice it is quite common. For example, you use some type of data in your database. Use it in your own parameters and variables! Yes, I know that SQL Server can implicitly convert one data type to another. But, when an implicit type conversion occurs, or you yourself cast the data type of a column to a different type, you perform the conversion for the entire column. When you do this conversion for a column in a WHERE clause or in a join condition, you will always see a table scan. An excellent index can be built on this column, but since you make a CAST for the values stored in this column to compare, for example, the date stored in this column, with the type of char you used in the condition, the index will not be used.
')
Do not believe? Let's look at this query:
SELECT e.BusinessEntityID, e.NationalIDNumber FROM HumanResources.Employee AS e WHERE e.NationalIDNumber = 112457891; Well written and very simple. It should be covered by the index created on this table. But here is the execution plan:
This query is executed fairly quickly and the table is small, so only four reads are required to scan the index. Notice the small exclamation point on the SELECT statement. If we refer to its properties, we will see:
Right. This is a warning (new in SQL Server 2012) that type conversion occurs that affects the execution plan. In short, this is because the query uses the wrong data type:
SELECT e.BusinessEntityID, e.NationalIDNumber FROM HumanResources.Employee AS e WHERE e.NationalIDNumber = '112457891'; And we get the following query execution plan:
And here only two read operations are used, instead of four. And yes, I understand that I made a query that was running so fast a little bit faster. But what would happen if millions of rows were stored in the table? Yeah, then I would be a hero.
Use the correct data types.
Using Functions in Compounding Conditions and in WHERE Clauses
Speaking of functions, most of the functions used in join conditions or WHERE clauses, to which you, as an argument, pass a column, interfere with the proper use of indexes. You will see how much slower queries are executed, in which functions are used that take columns as arguments. For example:
SELECT a.AddressLine1, a.AddressLine2, a.City, a.StateProvinceID FROM Person.Address AS a WHERE '4444' = LEFT(a.AddressLine1, 4) ; This function, LEFT, takes a column as an argument, which translates into this execution plan:
As a result, 316 read operations are performed to find the necessary data, and it takes 9 milliseconds (I have very fast disks). All because '4444' should match every line returned by this function. SQL Server cannot even simply scan the table, it needs to perform a LEFT for each row. However, you can do something like this:
SELECT a.AddressLine1, a.AddressLine2, a.City, a.StateProvinceID FROM Person.Address AS a WHERE a.AddressLine1 LIKE '4444%' ; And here we see a completely different implementation plan:
To perform the request requires 3 reads and 0 milliseconds. Well, or let it be 1 millisecond, for objectivity. This is a huge performance boost. And all because I used such a function that can be used to search by index (previously it was called sargeable - the word untranslatable, in general, the word: SARG - Search Arguments –able if the SARGeable function - you can pass a column into it argument and it will still be used Index Seek, if not SARGeable - alas, Index Scan will always be used - translator’s comment ). In any case, do not use functions in WHERE expressions or search conditions, or use only those that can be used in search conditions by index.
Using Multi-statement UDF
The multi-statement UDF in the Russian edition of msdn translates roughly as “User-defined functions consisting of several instructions, but this sounds, in my opinion, somehow strange, so I tried to avoid translating this term further into the heading - text . translator
In fact, they are driving you into a trap. At first glance, this wonderful mechanism allows us to use T-SQL as a real programming language. You can create these functions and call them one from another and the code can be reused, not like these old stored procedures. This is amazing. Until you try to run this code on a large amount of data.
The problem with these functions is that they are built on table variables. Table variables are a very cool thing if you use them for their intended purpose. They have one obvious difference from temporary tables - no statistics are built on them. This difference can be very useful, and maybe ... kill you. If you do not have statistics, the optimizer assumes that any query running on a table variable or UDF will return just one row. One (1) line. This is good if they do return multiple rows. But one day they will return hundreds or thousands of lines and you decide to connect one UDF to another ... Productivity will fall very, very quickly and very, very much.
An example is quite large. Here are a few UDFs:
CREATE FUNCTION dbo.SalesInfo () RETURNS @return_variable TABLE ( SalesOrderID INT, OrderDate DATETIME, SalesPersonID INT, PurchaseOrderNumber dbo.OrderNumber, AccountNumber dbo.AccountNumber, ShippingCity NVARCHAR(30) ) AS BEGIN; INSERT INTO @return_variable (SalesOrderID, OrderDate, SalesPersonID, PurchaseOrderNumber, AccountNumber, ShippingCity ) SELECT soh.SalesOrderID, soh.OrderDate, soh.SalesPersonID, soh.PurchaseOrderNumber, soh.AccountNumber, a.City FROM Sales.SalesOrderHeader AS soh JOIN Person.Address AS a ON soh.ShipToAddressID = a.AddressID ; RETURN ; END ; GO CREATE FUNCTION dbo.SalesDetails () RETURNS @return_variable TABLE ( SalesOrderID INT, SalesOrderDetailID INT, OrderQty SMALLINT, UnitPrice MONEY ) AS BEGIN; INSERT INTO @return_variable (SalesOrderID, SalesOrderDetailId, OrderQty, UnitPrice ) SELECT sod.SalesOrderID, sod.SalesOrderDetailID, sod.OrderQty, sod.UnitPrice FROM Sales.SalesOrderDetail AS sod ; RETURN ; END ; GO CREATE FUNCTION dbo.CombinedSalesInfo () RETURNS @return_variable TABLE ( SalesPersonID INT, ShippingCity NVARCHAR(30), OrderDate DATETIME, PurchaseOrderNumber dbo.OrderNumber, AccountNumber dbo.AccountNumber, OrderQty SMALLINT, UnitPrice MONEY ) AS BEGIN; INSERT INTO @return_variable (SalesPersonId, ShippingCity, OrderDate, PurchaseOrderNumber, AccountNumber, OrderQty, UnitPrice ) SELECT si.SalesPersonID, si.ShippingCity, si.OrderDate, si.PurchaseOrderNumber, si.AccountNumber, sd.OrderQty, sd.UnitPrice FROM dbo.SalesInfo() AS si JOIN dbo.SalesDetails() AS sd ON si.SalesOrderID = sd.SalesOrderID ; RETURN ; END ; GO Excellent structure. It allows you to make very simple requests. Well, for example, here:
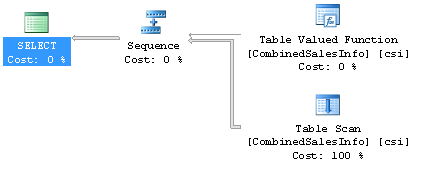
SELECT csi.OrderDate, csi.PurchaseOrderNumber, csi.AccountNumber, csi.OrderQty, csi.UnitPrice FROM dbo.CombinedSalesInfo() AS csi WHERE csi.SalesPersonID = 277 AND csi.ShippingCity = 'Odessa' ; One very simple request. Here is his execution plan, also very simple:
Here it is only executed 2.17 seconds, returns 148 lines and uses 1456 read operations. Please note that our function has a zero cost and only scanning a table, a table variable, affects the cost of the query. Hmm, is that right? Let's try to see what lies behind the zero-cost UDF execution operator. This query will get the execution plan for the function from the cache:
SELECT deqp.query_plan, dest.text, SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1, (deqs.statement_end_offset - deqs.statement_start_offset) / 2 + 1) AS actualstatement FROM sys.dm_exec_query_stats AS deqs CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest WHERE deqp.objectid = OBJECT_ID('dbo.CombinedSalesInfo'); And that's what's really going on there:
Wow, it looks like there are a few more of these small functions and scans of tables that almost, but still not quite, cost nothing. Plus, the Hash Match connection operator, which writes to tempdb and is quite expensive when executed. Let's see another UDF execution plan:
Here! And now we see a Clustered Index Scan, which scans a large number of rows. This is not great. In general, in this whole situation, UDFs seem less and less attractive. What if we, well, I don’t directly know, just try to directly access the tables. So, for example:
SELECT soh.OrderDate, soh.PurchaseOrderNumber, soh.AccountNumber, sod.OrderQty, sod.UnitPrice FROM Sales.SalesOrderHeader AS soh JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID = sod.SalesOrderID JOIN Person.Address AS ba ON soh.BillToAddressID = ba.AddressID JOIN Person.Address AS sa ON soh.ShipToAddressID = sa.AddressID WHERE soh.SalesPersonID = 277 AND sa.City = 'Odessa' ; Now, by running this query, we get exactly the same data, but in just 310 milliseconds, not 2170. Plus, SQL Server will perform only 911 read operations, not 1456. To be honest, it’s very easy to get performance problems using UDF
Turning on the “Work faster!” Setting: using “Dirty reads”
Returning to the past, to old computers with 286 processors on board, we can recall that for a number of reasons, they had a Turbo button on the front panel. If you accidentally "squeezed" it, then the computer immediately began to slow down insanely. Thus, you realized that some things should always be included to ensure maximum throughput. In the same way, many people look at the READ_UNCOMMITTED isolation level and the NO_LOCK hint as a turbo button for SQL Server. When using them, be sure that virtually any request and the entire system will become faster. This is due to the fact that during the reading no locks will be imposed and checked. Less locks - faster result. But…
When you use READ_UNCOMMITTED or NO_LOCK in your queries, you encounter dirty reads. Everyone understands that this means that you can read the "dog" and not the "cat" if at this moment the update operation is completed but not yet completed. But, besides this, you can get more or less rows than you actually have, as well as duplicate rows, since data pages can be moved during the execution of your query, and you do not impose any locks to avoid this. I do not know about you, but in most of the companies in which I worked, we expected that the majority of requests on most systems would return complete data. The same query with the same parameters, performed on the same data set, should give the same result. Only not if you use NO_LOCK. In order to verify this, I advise you to read this post .
Unreasonable use of hints in queries
People too quickly decide to use hints. The most common situation is when hint helps to solve one very rare problem on one of the queries. But when people see significant performance gains on this request ... they immediately start poking it generally everywhere.
For example, a lot of people think that a LOOP JOIN is the best way to join tables. They come to this conclusion because it is most often found in small and fast queries. Therefore, they decide to force SQL Server to use LOOP JOIN. It is not difficult at all:
SELECT s.[Name] AS StoreName, p.LastName + ', ' + p.FirstName FROM Sales.Store AS s JOIN sales.SalesPerson AS sp ON s.SalesPersonID = sp.BusinessEntityID JOIN HumanResources.Employee AS e ON sp.BusinessEntityID = e.BusinessEntityID JOIN Person.Person AS p ON e.BusinessEntityID = p.BusinessEntityID OPTION (LOOP JOIN); This request takes 101 milliseconds and performs 4115 read operations. Not bad in general, but if we remove this hint, the same query will execute in 90 milliseconds and produce only 2370 readings. The more loaded the system is, the more obvious will be the effectiveness of the query without using hint.
Here is another example. People often create an index on a table, expecting it to solve the problem. So, we have a request:
SELECT * FROM Purchasing.PurchaseOrderHeader AS poh WHERE poh.PurchaseOrderID * 2 = 3400; The problem again is that when you perform a column transformation, no index will be adequately used. Performance drops as a clustered index scan is performed. And so, when people see that their index is not used, they do this:
SELECT * FROM Purchasing.PurchaseOrderHeader AS poh WITH (INDEX (PK_PurchaseOrderHeader_PurchaseOrderID)) WHERE poh.PurchaseOrderID * 2 = 3400; And now they get a scan of their chosen index, not a clustered index, so the index is “used”, right? But the query performance changes - now, instead of 11 read operations, 44 are executed (the execution time for both is about 0 milliseconds, since I have really fast disks). “Used” is used, but not at all as intended. The solution to this problem is to rewrite the query in this way:
SELECT * FROM Purchasing.PurchaseOrderHeader poh WHERE PurchaseOrderID = 3400 / 2; Now the number of read operations has fallen to two, since an index search is used - the index is used correctly.
Hints in requests should always be applied last, after all other possible options have been tested and have not given a positive result.
Using line-by-line processing of the query result ('Row by Agonizing Row' processing)
Line by line processing is performed using cursors or operations in the WHILE loop, instead of operations on sets. When using them, the performance is very, very low. Cursors are usually used for two reasons. The first is the developers who are used to using line-by-line processing in their code, and the second is the developers who came from Oracle, who think that cursors are a good thing. Whatever the reason, cursors - kill the performance on the vine.
Here is a typical example of unsuccessful use of the cursor. We need to update the color of products selected by a specific criterion. It is not invented - it is based on a code that I once had to optimize.
BEGIN TRANSACTION DECLARE @Name NVARCHAR(50) , @Color NVARCHAR(15) , @Weight DECIMAL(8, 2) DECLARE BigUpdate CURSOR FOR SELECT p.[Name] ,p.Color ,p.[Weight] FROM Production.Product AS p ; OPEN BigUpdate ; FETCH NEXT FROM BigUpdate INTO @Name, @Color, @Weight ; WHILE @@FETCH_STATUS = 0 BEGIN IF @Weight < 3 BEGIN UPDATE Production.Product SET Color = 'Blue' WHERE CURRENT OF BigUpdate END FETCH NEXT FROM BigUpdate INTO @Name, @Color, @Weight ; END CLOSE BigUpdate ; DEALLOCATE BigUpdate ; SELECT * FROM Production.Product AS p WHERE Color = 'Blue' ; ROLLBACK TRANSACTION In each iteration, we perform two read operations, and the number of products that meet our criteria is in the hundreds. On my machine, without load, the execution time is more than a second. This is completely unacceptable, especially since rewriting this query is very simple:
BEGIN TRANSACTION UPDATE Production.Product SET Color = 'BLUE' WHERE [Weight] < 3 ; ROLLBACK TRANSACTION Now, only 15 read operations are performed and the execution time is only 1 millisecond. Do not laugh. People often write such code and even worse. Cursors are such a thing that should be avoided and used only where you cannot do without them - for example, in maintenance tasks where you need to run through different tables or databases.
Unreasonable use of nested views
Views that refer to views, connect to views, link to other views, connect to views ... A view is just a query. But since they can be treated as tables, people can start thinking of them as tables. And in vain. What happens when you connect one view to another, referring to a third view, and so on? You just create a damn complicated query execution plan. The optimizer will try to simplify it. He will try plans that do not use all the tables, but the time to work on the choice of the plan is limited and the more complex the plan he gets, the less likely he is to have a fairly simple execution plan. And performance problems will be almost inevitable.
Here, for example, is a sequence of simple queries defining views:
CREATE VIEW dbo.SalesInfoView AS SELECT soh.SalesOrderID, soh.OrderDate, soh.SalesPersonID, soh.PurchaseOrderNumber, soh.AccountNumber, a.City AS ShippingCity FROM Sales.SalesOrderHeader AS soh JOIN Person.Address AS a ON soh.ShipToAddressID = a.AddressID ; CREATE VIEW dbo.SalesDetailsView AS SELECT sod.SalesOrderID, sod.SalesOrderDetailID, sod.OrderQty, sod.UnitPrice FROM Sales.SalesOrderDetail AS sod ; CREATE VIEW dbo.CombinedSalesInfoView AS SELECT si.SalesPersonID, si.ShippingCity, si.OrderDate, si.PurchaseOrderNumber, si.AccountNumber, sd.OrderQty, sd.UnitPrice FROM dbo.SalesInfoView AS si JOIN dbo.SalesDetailsView AS sd ON si.SalesOrderID = sd.SalesOrderID ; And here the author of the text forgot to specify the request, but he quotes it in the comments (approx. Translator):
SELECT csi.OrderDate FROM dbo. CominedSalesInfoView csi WHERE csi.SalesPersonID = 277 As a result, our request executes 155 milliseconds and uses 965 read operations. Here is his execution plan:
It looks good, especially since we get 7,000 lines, so everything seems to be in order. But what if we try to execute the following query:
SELECT soh.OrderDate FROM Sales.SalesOrderHeader AS soh WHERE soh.SalesPersonID = 277 ; And now the request is executed in 3 milliseconds and uses 685 read operations - quite different. And here is his execution plan:
As you can see, the optimizer cannot throw out all unnecessary tables as part of the query simplification process. Therefore, in the first execution plan there are two unnecessary operations - Index Scan and Hash Match, which collects data together. You could save SQL Server from unnecessary work by writing this query without using views. And remember - this example is very simple, most requests in real life are much more complicated and lead to much bigger performance problems.
In the comments to this article there is a small dispute, the essence of which is that Grant (the author of the article) did seem to fulfill his requests not on the standard AdventureWorks database, but on a similar database, but with a slightly different structure, which is why the execution plan is “not optimal” “The query in the last section is different from what you can see by conducting the experiment yourself. Note translator.
If somewhere I was too stupid (and I can) and the text is difficult to understand, or you can offer me the best wording for anything, I’ll be happy to hear all the comments.
Source: https://habr.com/ru/post/149235/
All Articles