The concept of structural adaptation and an introduction to "pure generalization"
We continue the series of articles "AI for dummies." If in the last article we tried to delimit the people solving the tasks of the “oracles of a strong AI” from the tasks of the “weak AI”, and to show the solution of what kind of tasks gives more than lyrical “revelations”. We called one of these tasks “the task of two teachers”.
So now we look at it from a different angle. As I said this task is found in various aspects. And at the same time we will see how deeply the engineers of the “weak AI” are mistaken in the current trend of understanding the tasks of AI. Unfortunately, now education in this area encourages the creation of wretched formalisms and a narrowing look at the problems of AI. With one of the "miscarriages" of this kind of education, we discussed in the last article. But there are many such people who are straining the tendency to “stamp” such “educated students”.
')
Here I will try to retell the basics. They are taken from the monograph by L. A. Rastrigin “Adaptation of complex systems”.
The explanation of the concept of adaptation as an adaptation to new conditions, which completely satisfies biologists and sociologists, is completely unsatisfactory from the point of view of an engineer.
The concept of adaptation can be divided into two types (in fact, both types of adaptation occur simultaneously and interact with each other):
Passive adaptation is an adaptation to a fixed environment. The adapting system functions in such a way that it performs its functions in this environment in the best possible way, that is, it maximizes its performance criterion in this environment. An example of passive adaptation can be observed in plants.
Active adaptation - the search for an environment that is adequate to this system. This implies either a change in the environment in order to maximize the efficiency criterion, or an active search for an environment in which the desired comfort is achievable. An example of active adaptation can be observed in animals.
What is remarkable about Rastrigin's work, the fact that he mathematically introduced the concept of a subject , while everyone else speaks only about objective tasks, so to speak. And accordingly, since they do not have a mathematical concept of a subject, respectively, all these theories are far from AI. More precisely, the absence of a mathematical concept of a subject allows speaking only within the framework of a weak AI. Having a philosophical, psychological concept of the subject in AI - even worse - the problem of "oracles of a strong AI."
For our purposes, there is no need to understand what a subject is mathematically. The main thing is that such a concept exists, and it allows us to distinguish different levels of adaptation that are applicable to: (1) the formulation of control objectives, (2) the definition of the control object, (3) the structural synthesis of the model (4) the parametric synthesis of the model.
The current state of AI science is that automatically we are able to carry out only parametric synthesis of the model, and accordingly, only parametric adaptation occurs automatically.
We will not speak about the first two levels (the goals of management and the definition of the object of management), since There is not even a close understanding of how to do this. It is enough for us to consider at least the difference between structural and parametric adaptation.
Parametric adaptation is associated with correction, adjustment of model parameters. The need for this kind of adaptation arises in view of the drift of the characteristics of the controlled object. Adaptation allows to adjust the model at each management step, and the initial information for it is the mismatch of the object and model responses, the elimination of which implements the adaptation process.
Adaptive control, in the process of which not only the goals are achieved, but also the model is refined, is called dual. Here, by means of a special organization of management, two goals are immediately achieved - the management and adaptation of the model.
We talked about this kind of adaptation in the article Summary of the problem of “two or more teachers” and the subjective opinion about the AI community when we figured out how and why to set the fitness function using an artificial neural network .
What is the difference in structural adaptation?
Any model F consists of a structure and parameters: F = ‹St, C›, where St is the structure of the model F, C = (C_1, ..., C_k) is its parameters.
Not always adapting the model by correcting its parameters allows to obtain an adequate model of the object. Inadequacy occurs when there is a mismatch between the structures of the model and the object. If in the process of evolution of an object its structure changes, then this situation develops constantly.
Modern AI engineers are taught to make structural adaptations themselves - i.e. do the work for the car. And this happens with such self-sacrifice and self-love that they do not even understand what they are doing. Here are the characteristic phrases (lulz) that you can catch here:
1. To solve your problem you do not need anything but him.
2. Why do you need a hidden layer if one neuron handles this task?
3. I can solve problems and choose the appropriate tool for them instead of the “universal solver”.
We have a classic beginning - a person does not understand the task of the need for structural adaptation. With the help of his knowledge he tries to solve the problem of “synthesis of the structure of the model” himself. At the same time rejects the need to teach this machine. And everything ends up absolutely enchanting - he declares himself “smart”, and the others are “fools” only because he allegedly knows how to choose the “right tool”.
No, this is not a “choice of instrument”, alas, it is the current credo of modern AI-engineers, who stopped in their development and do not see the intellectual task in what they do for the car. These are such AI engineers who with pride will only do what to push on the steps of our pyramid and prevent others from walking towards the gazebo on the top of the pyramid.
My personal attitude to such AI-engineers is exactly the same as the oracles of a strong AI, and sometimes I am glad when the oracles of a strong AI criticize this kind of AI-engineers for the cause. For they do not know what they are doing, and what their task is as specialists in the field of AI.
Rosenblatt formulated the concept of pure generalization :
Why now these problems are not solved by representatives of a strong AI, or representatives of a weak AI? I have only one answer: the former do not understand the essence of such experiments, the latter do not understand the significance of such experiments. And in the end we are marking time.
In this section, we will look at how we solved the addition problem in the article Summary of the problem of “two or more teachers” and the subjective opinion about the AI community .
When we have indicated that we have 256 outputs, and the training sample is only half of the possible variations, it turns out:
* The following situation is violated: training is conducted during which the model is presented with a certain sequence of images, which includes representatives of each of the classes to be distinguished
* We showed the perceptron only how odd numbers are obtained. He had no idea that even numbers exist in nature. The weights after training to even numbers were zeros. That is why there is such a bad forecast. But still, the perceptron made some prediction, despite the fact that he could not know about the existence of even numbers. He tried without any classification, only on the basis of the type of the items in the binary representation - in the place where there should have been an even number to give at least some odd number known to him, but such that it is close to even. In essence, he performed “naive” clustering.
* Therefore, comparing the results of the forecast as ererer did it with the MLP + BackProp algorithm is not relevant here
* Ie The perceptron solved the problem as a problem with elements of “generalization”, and MLP + BackProp knew too much about the problem — it solved the approximation problem. Perceptron was not given such structural knowledge (remember about structural adaptation ?) Of what kind this task. And as a matter of fact, the perceptron simply physically could not generalize here.
Let's change a bit the problem conditions
Let's try the next step to slightly change the conditions of the problem so that the perceptron would have grounds for generalization. First, we will reduce the dimension of the problem from 64x64 to 32x32, this will not affect the conclusions, but it is calculated quickly.
Now our function will not be c = a + b, in which there exists the above described feature, that having learned on odd numbers, it is not possible to deduce the presence of even numbers.
Now we take the function c = (int) (a + b) / 4, rounded to the nearest whole number. Visually, it looks like this (in order to distinguish tasks we take this time in the gradation of green):

(on the left is the full function, on the right are training points for the perceptron)
Now let's analyze how the c = (int) (a + b) / 4 function we are studying contributes to the prediction. It is clear that the more examples of images per class (values of c), the better the forecast. This can be displayed by the following square:

Blue squares are points about which the perceptron knows nothing and needs to be predicted by it. But green are known to him, the green is brighter, the more examples he knows. In the extreme corners, only one point is known, and 62 examples in the central diagonal. Accordingly, it is not necessary to expect that the perceptron will uniformly generalize this function. Its forecast quality will depend on the type of predicted function.
And it will be like this:
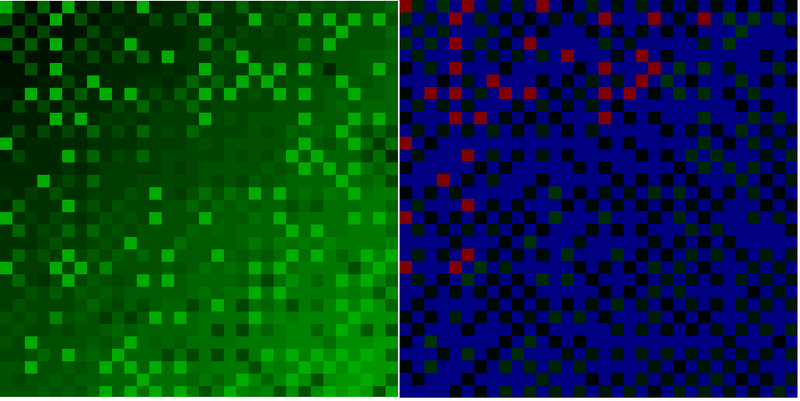
The complete forecast map is on the left, the error distribution is on the right (blue dots - no error, gradation from black to green - error up to 10 units, red error above 10 units). Or the distribution of errors in numbers:
Error value = Number of corresponding points
0 = 631
1 = 114
2 = 63
3 = 23
4 = 45
5 = 25
6 = 28
7 = 19
8 = 19
9 = 10
10 = 14
11 = 9
12 = 4
13 = 8
14 = 6
15 = 3
16 = 2
17 = 1
This is slightly worse than with MLP + BackProp, but the difference is that the perceptron comes only from the statistics of the appearance of images, and when the MLP + BackProp is used, the experimenter performs the additional task of structural adaptation.
Now, if we learned how to implement structural adaptation, then the perceptron would be able to predict not only on the basis of the statistics of the training sample, but also taking into account the structure / type of function.
So now we look at it from a different angle. As I said this task is found in various aspects. And at the same time we will see how deeply the engineers of the “weak AI” are mistaken in the current trend of understanding the tasks of AI. Unfortunately, now education in this area encourages the creation of wretched formalisms and a narrowing look at the problems of AI. With one of the "miscarriages" of this kind of education, we discussed in the last article. But there are many such people who are straining the tendency to “stamp” such “educated students”.
')
The essence of the task of adaptation
Here I will try to retell the basics. They are taken from the monograph by L. A. Rastrigin “Adaptation of complex systems”.
The explanation of the concept of adaptation as an adaptation to new conditions, which completely satisfies biologists and sociologists, is completely unsatisfactory from the point of view of an engineer.
The concept of adaptation can be divided into two types (in fact, both types of adaptation occur simultaneously and interact with each other):
Passive adaptation is an adaptation to a fixed environment. The adapting system functions in such a way that it performs its functions in this environment in the best possible way, that is, it maximizes its performance criterion in this environment. An example of passive adaptation can be observed in plants.
Active adaptation - the search for an environment that is adequate to this system. This implies either a change in the environment in order to maximize the efficiency criterion, or an active search for an environment in which the desired comfort is achievable. An example of active adaptation can be observed in animals.
What is remarkable about Rastrigin's work, the fact that he mathematically introduced the concept of a subject , while everyone else speaks only about objective tasks, so to speak. And accordingly, since they do not have a mathematical concept of a subject, respectively, all these theories are far from AI. More precisely, the absence of a mathematical concept of a subject allows speaking only within the framework of a weak AI. Having a philosophical, psychological concept of the subject in AI - even worse - the problem of "oracles of a strong AI."
For our purposes, there is no need to understand what a subject is mathematically. The main thing is that such a concept exists, and it allows us to distinguish different levels of adaptation that are applicable to: (1) the formulation of control objectives, (2) the definition of the control object, (3) the structural synthesis of the model (4) the parametric synthesis of the model.
The current state of AI science is that automatically we are able to carry out only parametric synthesis of the model, and accordingly, only parametric adaptation occurs automatically.
We will not speak about the first two levels (the goals of management and the definition of the object of management), since There is not even a close understanding of how to do this. It is enough for us to consider at least the difference between structural and parametric adaptation.
Parametric and structural adaptation
Parametric adaptation is associated with correction, adjustment of model parameters. The need for this kind of adaptation arises in view of the drift of the characteristics of the controlled object. Adaptation allows to adjust the model at each management step, and the initial information for it is the mismatch of the object and model responses, the elimination of which implements the adaptation process.
Adaptive control, in the process of which not only the goals are achieved, but also the model is refined, is called dual. Here, by means of a special organization of management, two goals are immediately achieved - the management and adaptation of the model.
We talked about this kind of adaptation in the article Summary of the problem of “two or more teachers” and the subjective opinion about the AI community when we figured out how and why to set the fitness function using an artificial neural network .
What is the difference in structural adaptation?
Any model F consists of a structure and parameters: F = ‹St, C›, where St is the structure of the model F, C = (C_1, ..., C_k) is its parameters.
Not always adapting the model by correcting its parameters allows to obtain an adequate model of the object. Inadequacy occurs when there is a mismatch between the structures of the model and the object. If in the process of evolution of an object its structure changes, then this situation develops constantly.
A bitter pill on a subjective example
Modern AI engineers are taught to make structural adaptations themselves - i.e. do the work for the car. And this happens with such self-sacrifice and self-love that they do not even understand what they are doing. Here are the characteristic phrases (lulz) that you can catch here:
1. To solve your problem you do not need anything but him.
2. Why do you need a hidden layer if one neuron handles this task?
3. I can solve problems and choose the appropriate tool for them instead of the “universal solver”.
We have a classic beginning - a person does not understand the task of the need for structural adaptation. With the help of his knowledge he tries to solve the problem of “synthesis of the structure of the model” himself. At the same time rejects the need to teach this machine. And everything ends up absolutely enchanting - he declares himself “smart”, and the others are “fools” only because he allegedly knows how to choose the “right tool”.
No, this is not a “choice of instrument”, alas, it is the current credo of modern AI-engineers, who stopped in their development and do not see the intellectual task in what they do for the car. These are such AI engineers who with pride will only do what to push on the steps of our pyramid and prevent others from walking towards the gazebo on the top of the pyramid.
My personal attitude to such AI-engineers is exactly the same as the oracles of a strong AI, and sometimes I am glad when the oracles of a strong AI criticize this kind of AI-engineers for the cause. For they do not know what they are doing, and what their task is as specialists in the field of AI.
A little bit about “pure generalization”
Rosenblatt formulated the concept of pure generalization :
Models present N different stimuli and require it to respond to them in different ways. Initially, training is conducted during which the model presents a certain sequence of images, which includes representatives of each of the classes to be distinguished. Then a control stimulus is presented and the probability of obtaining the correct response for the stimuli of a given class is determined.
If the control stimulus does not coincide with any of the training stimuli, then the experiment is associated not only with “pure discrimination”, but includes elements of “generalization”. If the control stimulus excites a certain set of sensory elements that are completely different from those elements that were activated by the action of previously presented stimuli of the same class, then the experiment is a study of “pure generalization”.
Why now these problems are not solved by representatives of a strong AI, or representatives of a weak AI? I have only one answer: the former do not understand the essence of such experiments, the latter do not understand the significance of such experiments. And in the end we are marking time.
In this section, we will look at how we solved the addition problem in the article Summary of the problem of “two or more teachers” and the subjective opinion about the AI community .
When we have indicated that we have 256 outputs, and the training sample is only half of the possible variations, it turns out:
* The following situation is violated: training is conducted during which the model is presented with a certain sequence of images, which includes representatives of each of the classes to be distinguished
* We showed the perceptron only how odd numbers are obtained. He had no idea that even numbers exist in nature. The weights after training to even numbers were zeros. That is why there is such a bad forecast. But still, the perceptron made some prediction, despite the fact that he could not know about the existence of even numbers. He tried without any classification, only on the basis of the type of the items in the binary representation - in the place where there should have been an even number to give at least some odd number known to him, but such that it is close to even. In essence, he performed “naive” clustering.
* Therefore, comparing the results of the forecast as ererer did it with the MLP + BackProp algorithm is not relevant here
* Ie The perceptron solved the problem as a problem with elements of “generalization”, and MLP + BackProp knew too much about the problem — it solved the approximation problem. Perceptron was not given such structural knowledge (remember about structural adaptation ?) Of what kind this task. And as a matter of fact, the perceptron simply physically could not generalize here.
Let's change a bit the problem conditions
Let's try the next step to slightly change the conditions of the problem so that the perceptron would have grounds for generalization. First, we will reduce the dimension of the problem from 64x64 to 32x32, this will not affect the conclusions, but it is calculated quickly.
Now our function will not be c = a + b, in which there exists the above described feature, that having learned on odd numbers, it is not possible to deduce the presence of even numbers.
Now we take the function c = (int) (a + b) / 4, rounded to the nearest whole number. Visually, it looks like this (in order to distinguish tasks we take this time in the gradation of green):
(on the left is the full function, on the right are training points for the perceptron)
Now let's analyze how the c = (int) (a + b) / 4 function we are studying contributes to the prediction. It is clear that the more examples of images per class (values of c), the better the forecast. This can be displayed by the following square:
Blue squares are points about which the perceptron knows nothing and needs to be predicted by it. But green are known to him, the green is brighter, the more examples he knows. In the extreme corners, only one point is known, and 62 examples in the central diagonal. Accordingly, it is not necessary to expect that the perceptron will uniformly generalize this function. Its forecast quality will depend on the type of predicted function.
And it will be like this:
The complete forecast map is on the left, the error distribution is on the right (blue dots - no error, gradation from black to green - error up to 10 units, red error above 10 units). Or the distribution of errors in numbers:
Error value = Number of corresponding points
0 = 631
1 = 114
2 = 63
3 = 23
4 = 45
5 = 25
6 = 28
7 = 19
8 = 19
9 = 10
10 = 14
11 = 9
12 = 4
13 = 8
14 = 6
15 = 3
16 = 2
17 = 1
This is slightly worse than with MLP + BackProp, but the difference is that the perceptron comes only from the statistics of the appearance of images, and when the MLP + BackProp is used, the experimenter performs the additional task of structural adaptation.
Now, if we learned how to implement structural adaptation, then the perceptron would be able to predict not only on the basis of the statistics of the training sample, but also taking into account the structure / type of function.
Source: https://habr.com/ru/post/149153/
All Articles