Python captcha decoding
This translation and form of the narrative from the first person saved. Written by Ben Boyter, Bachelor of Information Technology at Charles Sturt University (CSU).

Most people do not know, but my dissertation was a program for reading text from an image. I thought that if I could get a high level of recognition, it could be used to improve search results. My excellent adviser, Dr. Gao Junbin, suggested that I write a dissertation on this topic. I finally found the time to write this article and here I will try to tell about everything that I learned. If only there was something like that when I was just starting ...
As I said, I tried to take ordinary images from the Internet and extract text from them to improve search results. Most of my ideas were based on captcha hacking methods. As everyone knows, captcha is the most annoying thing, like “Enter the letters you see on the image” on the registration or feedback pages.
')
Captcha is designed so that a person can read the text without difficulty, while the machine is not (hello, reCaptcha!). In practice, this never worked, since almost every captcha that was posted on the site was hacked for several months.
I did quite well - more than 60% of the images were successfully guessed from my small collection. Pretty good, given the number of different images on the Internet.
In my research, I did not find any materials that would help me. Yes, there are articles, but they contain very simple algorithms. In fact, I found some non-working examples in PHP and Perl, I took several fragments from them and got quite good results for a very simple captcha. But none of them helped me much, since it was too easy. I am one of those people who can read the theory, but can not understand anything without real examples. And in most articles it was written that they will not publish the code, because they are afraid that it will be used for bad purposes. Personally, I think that captcha is a waste of time, because it's pretty easy to get around if you know how.
Actually because of the lack of any materials showing the breaking of the captcha for beginners, I wrote this article.
Let's start. Here is a list of what I am going to cover in this article:
All examples are written in Python 2.5 using the PIL library. It should work in Python 2.6 (under Python 2.7.3 it runs fine, approx. Transl. ).
Install them in the order shown above and you are ready to run the examples.
In the examples, I will hard-code the set of values right in the code. I have no goal to create a universal captcha recognizer, but only to show how this is done.
Basically, captcha is an example of one-way conversion. You can easily take a character set and get a captcha out of it, but not vice versa. Another subtlety is that it should be simple for a person to read, but not be machine recognized. Captcha can be considered as a simple test like "Are you human?". Basically they are implemented as an image with some kind of characters or words.
They are used to prevent spam on many Internet sites. For example, captcha can be found on the registration page in Windows Live ID .
You are shown an image, and, if you are really a person, then you need to enter its text in a separate field. Seems like a good idea that can protect you from thousands of automatic registrations for the purpose of spamming or spreading Viagra on your forum? The problem is that AI, and in particular, image recognition methods have undergone significant changes and become very effective in certain areas. OCR (Optical Character Recognition) is fairly accurate today and easily recognizes printed text. It was decided to add a little color and lines to make it harder for the computer to work without inconvenience to users. This is a kind of arms race and, as usual, they come up with a stronger weapon for any defense. Defeating the enhanced captcha is more difficult, but still possible. Plus, the image should remain fairly simple, so as not to cause irritation in ordinary people.
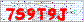
This image is an example of a captcha that we will decode. This is a real captcha, which is posted on a real site.
This is a fairly simple captcha, which consists of characters of the same color and size on a white background with some noise (pixels, colors, lines). You think that this background noise makes it difficult to recognize, but I will show how easy it is to remove it. Although it is not a very strong captcha, it is a good example for our program.
There are many methods for determining the position of text on an image and extracting it. With Google, you can find thousands of articles that explain new methods and algorithms for finding text.
For this example, I will use color extraction. This is a fairly simple technique, with which I got pretty good results. I used this technique for my dissertation.
For our examples, I will use a multi-valued image decomposition algorithm. In essence, this means that we first build a histogram of the color of the image. This is done by obtaining all the pixels in the image grouped by color, after which they are counted for each group. If you look at our test captcha, you can see three primary colors:
In Python, this will look very simple.
The following code opens the image, converts it into a GIF (makes it easier for us to work, because there are only 255 colors in it) and prints a histogram of colors.
As a result, we get the following:
Here we see the number of pixels of each of the 255 colors in the image. You can see that white (255, the most recent) occurs most often. Behind him comes the red (text). To verify this, write a small script:
And we get the following data:
This is a list of the 10 most common colors in an image. As expected, white is repeated most often. Then go gray and red.
As soon as we receive this information, we create new images based on these color groups. For each of the most common colors, we create a new binary image (of 2 colors), where the pixels of this color are filled with black, and everything else is white.
Red here is the third most common color, which means that we want to save a group of pixels with a color of 220. When I experimented, I found that the color 227 is pretty close to 220, so we will save this group of pixels. The code below opens the captcha, converts it into a GIF, creates a new image of the same size with a white background, and then walks around the original image in search of the color we need. If it finds a pixel with the color we need, then it marks the same pixel in the second image in black. Before shutting down, the second image is saved.
Running this code snippet gives us the following result.
In the picture you can see that we have successfully managed to extract text from the background. To automate this process, you can combine the first and second script.
I hear you ask: "What if the captcha text is written in different colors?". Yes, our equipment can still work. Assume that the most common color is the background color and then you can find the colors of the characters.
Thus, at the moment we have successfully extracted the text from the image. The next step is to determine if the image contains text. For the time being, I will not write code here, since this will make understanding difficult, while the algorithm itself is quite simple.
At the exit you will have a set of character boundaries. Then all you need to do is to compare them with each other and see if they are going consistently. If yes, then you fell the jackpot and you correctly identified the characters coming along. You can also check the size of the resulting areas or simply create a new image and show it (the
As a result, we did the following:
These are horizontal positions at the beginning and end of each character.
Image recognition can be considered the greatest success of modern AI, which allowed it to penetrate into all types of commercial applications. A good example of this is zip codes. In fact, in many countries they are read automatically, since it is quite simple to teach a computer to recognize numbers. This may not be obvious, but pattern recognition is considered an AI problem, albeit a very highly specialized one.
Almost the first thing that neural networks encounter when meeting with AI in pattern recognition. Personally, I have never had success with neural networks in character recognition. I usually teach him 3-4 characters, after which the accuracy drops so low that it would be an order of magnitude higher, if I guess the characters at random. At first, this caused me a slight panic, since this was the missing link in my dissertation. Fortunately, I recently read an article about vector-space search engines and considered them an alternative method of data classification. In the end, they turned out to be the best choice, since
Of course, there is no free cheese. The main drawback in speed. They can be much slower than neural networks. But I think that their advantages still outweigh this disadvantage.
If you want to understand how the vector space works, then I advise you to read Vector Space Search Engine Theory . This is the best I've found for beginners.
I built my image recognition based on the aforementioned document and this was the first thing I tried to write on my favorite PL, which I was studying at the time. Read this document and how you will understand its essence - come back here.
Have you already returned? Good. Now we have to program our vector space. Fortunately, it is not difficult at all. Let's get started
This is the implementation of Python vector space in 15 lines. Essentially, it simply takes 2 dictionaries and returns a number from 0 to 1, indicating how they are related. 0 means that they are not related, and 1 means that they are identical.
The next thing we need is a set of images with which we will compare our characters. We need a training set. This set can be used to train any kind of AI that we will use (neural networks, etc.).
The data used can be crucial for the success of recognition. The better the data, the greater the chance of success. Since we are planning to recognize a specific captcha and can already extract symbols from it, why not use them as a training set?
This is what I did. I downloaded a lot of generated captchas and my program broke them into letters. Then I collected the images in the collection (group). After several attempts, I had at least one example of each character that a captcha generated. Adding more examples will improve the recognition accuracy, but this was enough for me to confirm my theory.
At the output we get a set of images in the same directory. Each of them is assigned a unique hash in case you will process several captchas.
Here is the result of this code for our test captcha:
You decide how to store these images, but I just put them in directories with the same name as in the image (symbol or number).
Last step. We have text extraction, character extraction, recognition technique and a training set.
We get the image of a captcha, select the text, get the characters, and then comparing them with our training set. You can download the final program with a training set and a small amount of captchas from this link .
Here we simply load the training set to be able to compare with it:
And here all the magic happens. We determine where each character is and check it with our vector space. Then sort the results and print them.
Now we have everything we need and we can try to start our wonderful machine.
The input file is
Here we see the intended symbol and the degree of confidence that it really is (from 0 to 1).
It looks like we really did it!
In fact, on test captchas, this script will produce a successful result in about 22% of cases (I got 28.5, approx. Transl. ).
Most of the incorrect results are due to incorrect recognition of the number "0" and the letter "O". There is nothing unexpected, because even people often confuse them. We still have a problem with breaking into characters, but this can be solved simply by checking the result of the split and finding a middle ground.
However, even with such a not very perfect algorithm, we can solve every fifth captcha in a time where a person would not have had time to solve one.
Running this code on the Core 2 Duo E6550 gives the following results:
From the translator. I got the following results on the Dual Core T4400:
There are 48 captchas in our catalog, which means that solving one takes about 0.12 seconds. With our 22% percent of successful guessing, we can guess about 432,000 captcha per day and get 95,040 correct results. And if you use multithreading?
That's all. I hope that my experience will be used by you for good purposes. I know that you can use this code to the detriment, but to make something really dangerous you must change it quite a bit.
For those who are trying to protect themselves with captcha, I can say that it will not help you much, because you can bypass them programmatically or simply pay other people who will solve them manually. Think over other ways of protection.
Most people do not know, but my dissertation was a program for reading text from an image. I thought that if I could get a high level of recognition, it could be used to improve search results. My excellent adviser, Dr. Gao Junbin, suggested that I write a dissertation on this topic. I finally found the time to write this article and here I will try to tell about everything that I learned. If only there was something like that when I was just starting ...
As I said, I tried to take ordinary images from the Internet and extract text from them to improve search results. Most of my ideas were based on captcha hacking methods. As everyone knows, captcha is the most annoying thing, like “Enter the letters you see on the image” on the registration or feedback pages.
')
Captcha is designed so that a person can read the text without difficulty, while the machine is not (hello, reCaptcha!). In practice, this never worked, since almost every captcha that was posted on the site was hacked for several months.
I did quite well - more than 60% of the images were successfully guessed from my small collection. Pretty good, given the number of different images on the Internet.
In my research, I did not find any materials that would help me. Yes, there are articles, but they contain very simple algorithms. In fact, I found some non-working examples in PHP and Perl, I took several fragments from them and got quite good results for a very simple captcha. But none of them helped me much, since it was too easy. I am one of those people who can read the theory, but can not understand anything without real examples. And in most articles it was written that they will not publish the code, because they are afraid that it will be used for bad purposes. Personally, I think that captcha is a waste of time, because it's pretty easy to get around if you know how.
Actually because of the lack of any materials showing the breaking of the captcha for beginners, I wrote this article.
Let's start. Here is a list of what I am going to cover in this article:
- Used technologies
- What is a captcha
- How to find and extract text from images
- Image recognition using AI
- Training
- Putting it all together
- Results and conclusions
Used technologies
All examples are written in Python 2.5 using the PIL library. It should work in Python 2.6 (under Python 2.7.3 it runs fine, approx. Transl. ).
- Python: www.python.org
- PIL: www.pythonware.com/products/pil
Install them in the order shown above and you are ready to run the examples.
Retreat
In the examples, I will hard-code the set of values right in the code. I have no goal to create a universal captcha recognizer, but only to show how this is done.
Captcha, what is it in the end?
Basically, captcha is an example of one-way conversion. You can easily take a character set and get a captcha out of it, but not vice versa. Another subtlety is that it should be simple for a person to read, but not be machine recognized. Captcha can be considered as a simple test like "Are you human?". Basically they are implemented as an image with some kind of characters or words.
They are used to prevent spam on many Internet sites. For example, captcha can be found on the registration page in Windows Live ID .
You are shown an image, and, if you are really a person, then you need to enter its text in a separate field. Seems like a good idea that can protect you from thousands of automatic registrations for the purpose of spamming or spreading Viagra on your forum? The problem is that AI, and in particular, image recognition methods have undergone significant changes and become very effective in certain areas. OCR (Optical Character Recognition) is fairly accurate today and easily recognizes printed text. It was decided to add a little color and lines to make it harder for the computer to work without inconvenience to users. This is a kind of arms race and, as usual, they come up with a stronger weapon for any defense. Defeating the enhanced captcha is more difficult, but still possible. Plus, the image should remain fairly simple, so as not to cause irritation in ordinary people.
This image is an example of a captcha that we will decode. This is a real captcha, which is posted on a real site.
This is a fairly simple captcha, which consists of characters of the same color and size on a white background with some noise (pixels, colors, lines). You think that this background noise makes it difficult to recognize, but I will show how easy it is to remove it. Although it is not a very strong captcha, it is a good example for our program.
How to find and extract text from images
There are many methods for determining the position of text on an image and extracting it. With Google, you can find thousands of articles that explain new methods and algorithms for finding text.
For this example, I will use color extraction. This is a fairly simple technique, with which I got pretty good results. I used this technique for my dissertation.
For our examples, I will use a multi-valued image decomposition algorithm. In essence, this means that we first build a histogram of the color of the image. This is done by obtaining all the pixels in the image grouped by color, after which they are counted for each group. If you look at our test captcha, you can see three primary colors:
- White background)
- Gray (noise)
- Red (text)
In Python, this will look very simple.
The following code opens the image, converts it into a GIF (makes it easier for us to work, because there are only 255 colors in it) and prints a histogram of colors.
from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") print im.histogram() As a result, we get the following:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 , 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0 , 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1, 0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0, 0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0 , 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2, 365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21, 1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625] Here we see the number of pixels of each of the 255 colors in the image. You can see that white (255, the most recent) occurs most often. Behind him comes the red (text). To verify this, write a small script:
from PIL import Image from operator import itemgetter im = Image.open("captcha.gif") im = im.convert("P") his = im.histogram() values = {} for i in range(256): values[i] = his[i] for j,k in sorted(values.items(), key=itemgetter(1), reverse=True)[:10]: print j,k And we get the following data:
| Colour | Number of pixels |
|---|---|
| 255 | 625 |
| 212 | 365 |
| 220 | 186 |
| 219 | 135 |
| 169 | 132 |
| 227 | 116 |
| 213 | 115 |
| 234 | 21 |
| 205 | 18 |
| 184 | 15 |
This is a list of the 10 most common colors in an image. As expected, white is repeated most often. Then go gray and red.
As soon as we receive this information, we create new images based on these color groups. For each of the most common colors, we create a new binary image (of 2 colors), where the pixels of this color are filled with black, and everything else is white.
Red here is the third most common color, which means that we want to save a group of pixels with a color of 220. When I experimented, I found that the color 227 is pretty close to 220, so we will save this group of pixels. The code below opens the captcha, converts it into a GIF, creates a new image of the same size with a white background, and then walks around the original image in search of the color we need. If it finds a pixel with the color we need, then it marks the same pixel in the second image in black. Before shutting down, the second image is saved.
from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) im2.save("output.gif") Running this code snippet gives us the following result.
| Original | Result |
| 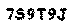 |
In the picture you can see that we have successfully managed to extract text from the background. To automate this process, you can combine the first and second script.
I hear you ask: "What if the captcha text is written in different colors?". Yes, our equipment can still work. Assume that the most common color is the background color and then you can find the colors of the characters.
Thus, at the moment we have successfully extracted the text from the image. The next step is to determine if the image contains text. For the time being, I will not write code here, since this will make understanding difficult, while the algorithm itself is quite simple.
for each binary image: for each pixel in the binary image: if the pixel is on: if any pixel we have seen before is next to it: add to the same set else: add to a new set At the exit you will have a set of character boundaries. Then all you need to do is to compare them with each other and see if they are going consistently. If yes, then you fell the jackpot and you correctly identified the characters coming along. You can also check the size of the resulting areas or simply create a new image and show it (the
show() method on the image) to make sure the algorithm is accurate. from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) # new code starts here inletter = False foundletter=False start = 0 end = 0 letters = [] for y in range(im2.size[0]): # slice across for x in range(im2.size[1]): # slice down pix = im2.getpixel((y,x)) if pix != 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append((start,end)) inletter=False print letters As a result, we did the following:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)] These are horizontal positions at the beginning and end of each character.
AI and vector space in pattern recognition
Image recognition can be considered the greatest success of modern AI, which allowed it to penetrate into all types of commercial applications. A good example of this is zip codes. In fact, in many countries they are read automatically, since it is quite simple to teach a computer to recognize numbers. This may not be obvious, but pattern recognition is considered an AI problem, albeit a very highly specialized one.
Almost the first thing that neural networks encounter when meeting with AI in pattern recognition. Personally, I have never had success with neural networks in character recognition. I usually teach him 3-4 characters, after which the accuracy drops so low that it would be an order of magnitude higher, if I guess the characters at random. At first, this caused me a slight panic, since this was the missing link in my dissertation. Fortunately, I recently read an article about vector-space search engines and considered them an alternative method of data classification. In the end, they turned out to be the best choice, since
- They do not require extensive study.
- You can add / remove incorrect data and immediately see the result.
- They are easier to understand and program.
- They provide classified results so you can see the top X matches.
- Can't recognize something? Add this and you can recognize it instantly, even if it is completely different from something seen before.
Of course, there is no free cheese. The main drawback in speed. They can be much slower than neural networks. But I think that their advantages still outweigh this disadvantage.
If you want to understand how the vector space works, then I advise you to read Vector Space Search Engine Theory . This is the best I've found for beginners.
I built my image recognition based on the aforementioned document and this was the first thing I tried to write on my favorite PL, which I was studying at the time. Read this document and how you will understand its essence - come back here.
Have you already returned? Good. Now we have to program our vector space. Fortunately, it is not difficult at all. Let's get started
import math class VectorCompare: def magnitude(self,concordance): total = 0 for word,count in concordance.iteritems(): total += count ** 2 return math.sqrt(total) def relation(self,concordance1, concordance2): relevance = 0 topvalue = 0 for word, count in concordance1.iteritems(): if concordance2.has_key(word): topvalue += count * concordance2[word] return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2)) This is the implementation of Python vector space in 15 lines. Essentially, it simply takes 2 dictionaries and returns a number from 0 to 1, indicating how they are related. 0 means that they are not related, and 1 means that they are identical.
Training
The next thing we need is a set of images with which we will compare our characters. We need a training set. This set can be used to train any kind of AI that we will use (neural networks, etc.).
The data used can be crucial for the success of recognition. The better the data, the greater the chance of success. Since we are planning to recognize a specific captcha and can already extract symbols from it, why not use them as a training set?
This is what I did. I downloaded a lot of generated captchas and my program broke them into letters. Then I collected the images in the collection (group). After several attempts, I had at least one example of each character that a captcha generated. Adding more examples will improve the recognition accuracy, but this was enough for me to confirm my theory.
from PIL import Image import hashlib import time im = Image.open("captcha.gif") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} print im.histogram() for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) inletter = False foundletter=False start = 0 end = 0 letters = [] for y in range(im2.size[0]): # slice across for x in range(im2.size[1]): # slice down pix = im2.getpixel((y,x)) if pix != 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append((start,end)) inletter=False # New code is here. We just extract each image and save it to disk with # what is hopefully a unique name count = 0 for letter in letters: m = hashlib.md5() im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] )) m.update("%s%s"%(time.time(),count)) im3.save("./%s.gif"%(m.hexdigest())) count += 1 At the output we get a set of images in the same directory. Each of them is assigned a unique hash in case you will process several captchas.
Here is the result of this code for our test captcha:
 |  |  |  |  | 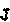 |
You decide how to store these images, but I just put them in directories with the same name as in the image (symbol or number).
Putting it all together
Last step. We have text extraction, character extraction, recognition technique and a training set.
We get the image of a captcha, select the text, get the characters, and then comparing them with our training set. You can download the final program with a training set and a small amount of captchas from this link .
Here we simply load the training set to be able to compare with it:
def buildvector(im): d1 = {} count = 0 for i in im.getdata(): d1[count] = i count += 1 return d1 v = VectorCompare() iconset = ['0','1','2','3','4','5','6','7','8','9','0','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t',' u','v','w','x','y','z'] imageset = [] for letter in iconset: for img in os.listdir('./iconset/%s/'%(letter)): temp = [] if img != "Thumbs.db": temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img)))) imageset.append({letter:temp}) And here all the magic happens. We determine where each character is and check it with our vector space. Then sort the results and print them.
count = 0 for letter in letters: m = hashlib.md5() im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] )) guess = [] for image in imageset: for x,y in image.iteritems(): if len(y) != 0: guess.append( ( v.relation(y[0],buildvector(im3)),x) ) guess.sort(reverse=True) print "",guess[0] count += 1 findings
Now we have everything we need and we can try to start our wonderful machine.
The input file is
captcha.gif . Expected Result: 7s9t9j python crack.py (0.96376811594202894, '7') (0.96234028545977002, 's') (0.9286884286888929, '9') (0.98350370609844473, 't') (0.96751165072506273, '9') (0.96989711688772628, 'j') Here we see the intended symbol and the degree of confidence that it really is (from 0 to 1).
It looks like we really did it!
In fact, on test captchas, this script will produce a successful result in about 22% of cases (I got 28.5, approx. Transl. ).
python crack_test.py Correct Guesses - 11.0 Wrong Guesses - 37.0 Percentage Correct - 22.9166666667 Percentage Wrong - 77.0833333333 Most of the incorrect results are due to incorrect recognition of the number "0" and the letter "O". There is nothing unexpected, because even people often confuse them. We still have a problem with breaking into characters, but this can be solved simply by checking the result of the split and finding a middle ground.
However, even with such a not very perfect algorithm, we can solve every fifth captcha in a time where a person would not have had time to solve one.
Running this code on the Core 2 Duo E6550 gives the following results:
real 0m5.750s user 0m0.015s sys 0m0.000s From the translator. I got the following results on the Dual Core T4400:
real 0m0.176s user 0m0.160s sys 0m0.012s There are 48 captchas in our catalog, which means that solving one takes about 0.12 seconds. With our 22% percent of successful guessing, we can guess about 432,000 captcha per day and get 95,040 correct results. And if you use multithreading?
That's all. I hope that my experience will be used by you for good purposes. I know that you can use this code to the detriment, but to make something really dangerous you must change it quite a bit.
For those who are trying to protect themselves with captcha, I can say that it will not help you much, because you can bypass them programmatically or simply pay other people who will solve them manually. Think over other ways of protection.
Source: https://habr.com/ru/post/149091/
All Articles