Place Lucene index in RAM using Azul Zing JVM
The entire Google search index has been located in RAM memory for at least 5 years. Why not try the same search index for Lucene?
Recently, RAM has become very inexpensive, so for high-loaded resources, it is quite reasonable to expect a serious performance improvement due to the placement of the search index entirely in RAM.
The obvious question is - can we try to load the entire index into the
Unfortunately, this class is known for creating a very serious load on the garbage collector (GC): each file is presented as a list of fragments of the type
')
Despite these problems with the
I recently learned about the Java Zing virtual machine developed by Azul , which provides a pause-free garbage collector, even for very large heap volumes. Those. theoretically, a large load on the memory generated by the
By default, the utilities in the luceneutil suite measure the average response time, discarding extremely interesting extreme values. This is done due to the fact that these utilities are designed to test the algorithms and the efficiency of the changes made to them, specifically ignoring random deviations made by extraneous delays at the level of the operating system, disk subsystem, garbage collector, etc.
But for real-world search applications, what really matters is the total response time for all search queries. Search is inherently an interactive process: the user sits and waits for the search result to return to him, and then clicks on the links. If even 1% of requests take a lot of time, then this is already a serious problem! Users are impatient, and very quickly move to competitors.
Therefore, I modified lucenutil to separate the load client ( sendTasks.py ) into a separate module, which saves the response time for all requests; as well as scripts ( loadGraph.py and responseTimeGraph.py ) for plotting response time. Also, the responseTimeTests.py directly launching script was developed for executing a series of tests, with increasing load (requests / sec), automatically stopping the testing when the load begins to exceed the server's performance. As a nice addition, this approach allows you to measure the actual performance of the server, and not to extrapolate it from the averages.
For the most accurate simulation of the time of sending real requests, the client sends them in accordance with the Poisson distribution. The testing script works in one stream, and if we send requests at a speed of 200 requests per second, and the server for some reason died for 5 seconds, the request queue will grow to 1000. Unfortunately, a lot of load tests behave differently, and Get a separate client thread for each client being emulated.
The client works (via ssh) on a separate machine, which is an important point, because the Lucene server (and not only the JVM) periodically sags in performance (for example, a swap occurs), which can slow down the load client and thus distort the results . Ideally, the client runs on a dedicated machine, and does not experience any pauses. Additionally, the Python garbage collector is disabled on the client to eliminate its negative impact.
To test Zing, I indexed the full base of English-language Wikipedia as of 2.05.2012, having a volume of 28.78 GB of plain text, representing 33.3 million documents, about 1Kb in size, including built-in fields and term vectors. Because of this, I can highlight results using the
Each test was performed within an hour, the first 5 minutes required for warming up were excluded from the register. The maximum heap capacity was 140 GB (
I tested various load levels (queries / sec), starting at 50 (minimal) and up to 275 (very large), and then built graphs illustrating the perceptions of response time for various configurations. The default parallel Oracle GC behaved terribly slow (Tens of seconds to clear the memory) so I didn’t even include it in the resulting report. The new G1 collector turned out to be even slower at launch speed (it took 6 hours to load the index into
On the minimum load (50 requests / sec), Zing showed good performance, providing minimal response time, even for the worst cases, while the CMS showed quite a long response time for a sufficiently large number of cases, even when using

To estimate the saturation limit of each of the configurations, I plotted the response time for 99% of cases and for different levels of load:
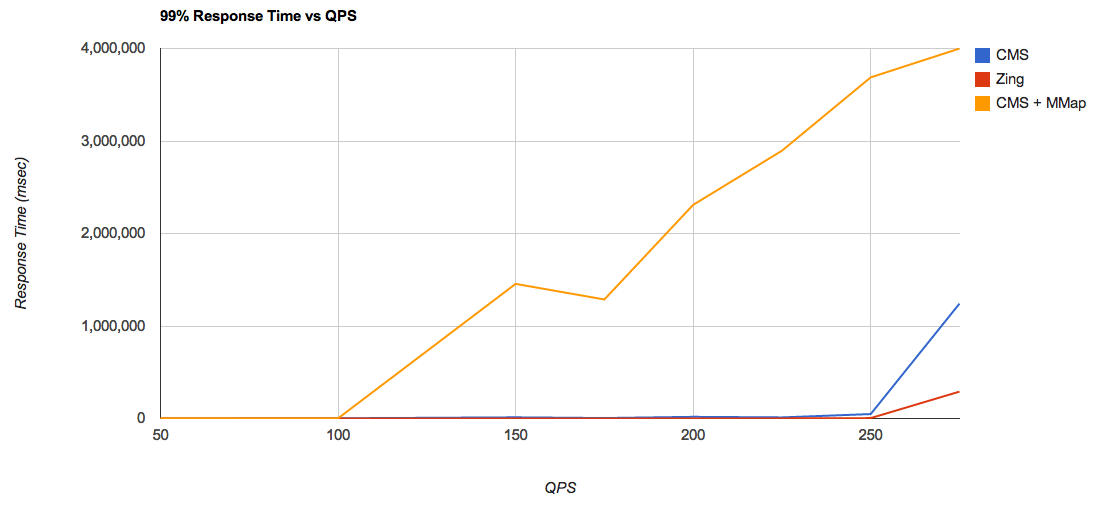
From this graph it can be concluded that for a bunch of
Let's build the same graph, but without the results for

For the 99% percentile, the Zing performance remains stable, while the CMS begins to show a long response time, starting at a load of 100 requests / sec. Let's look at the figures with a load of 225 requests / sec, which is closest to the saturation limit and when using

The time spent on pauses is already significantly longer here than with a load of 50 requests / sec: Already starting with a percentile of 95%, the response time becomes too long: 4479 ms or more.
These tests demonstrate that when using the Zing garbage collector, a very short response time is achieved, even at extreme loads, when the application has a heap of 140 GB in size, and the Lucene index is 78 GB in
Most interestingly, Azul recently announced the availability of JVM Zing for open-source developers to use for development and testing purposes.
Recently, RAM has become very inexpensive, so for high-loaded resources, it is quite reasonable to expect a serious performance improvement due to the placement of the search index entirely in RAM.
The obvious question is - can we try to load the entire index into the
RAMDirectory class provided by Lucene?Unfortunately, this class is known for creating a very serious load on the garbage collector (GC): each file is presented as a list of fragments of the type
byte[1024] . Also, it contains unnecessary synchronization mechanisms: if the application updates the index (that is, not only searches), the problem of how to save the changes made in the RAMDirectory back to the disk is a problem. Start time is also significantly slowed down, due to the need for the initial loading of the index into memory. Faced with this list of problems, Lucene developers often recommend using RAMDirectory only for small indexes or for testing purposes, and in other cases rely on the memory management mechanisms of the operating system, and access it using the MMapDirectory class.')
Despite these problems with the
RAMDirectory class, developers are working to improve it, and many users are already using it in their projects.I recently learned about the Java Zing virtual machine developed by Azul , which provides a pause-free garbage collector, even for very large heap volumes. Those. theoretically, a large load on the memory generated by the
RAMDirectory class RAMDirectory not be a problem for Zing. Let's check it out! But first, let's make a brief explanation about how important it is to test the response time for all requests, and not to measure the average temperature in the hospital.Percentiles for search query response time
By default, the utilities in the luceneutil suite measure the average response time, discarding extremely interesting extreme values. This is done due to the fact that these utilities are designed to test the algorithms and the efficiency of the changes made to them, specifically ignoring random deviations made by extraneous delays at the level of the operating system, disk subsystem, garbage collector, etc.
But for real-world search applications, what really matters is the total response time for all search queries. Search is inherently an interactive process: the user sits and waits for the search result to return to him, and then clicks on the links. If even 1% of requests take a lot of time, then this is already a serious problem! Users are impatient, and very quickly move to competitors.
Therefore, I modified lucenutil to separate the load client ( sendTasks.py ) into a separate module, which saves the response time for all requests; as well as scripts ( loadGraph.py and responseTimeGraph.py ) for plotting response time. Also, the responseTimeTests.py directly launching script was developed for executing a series of tests, with increasing load (requests / sec), automatically stopping the testing when the load begins to exceed the server's performance. As a nice addition, this approach allows you to measure the actual performance of the server, and not to extrapolate it from the averages.
For the most accurate simulation of the time of sending real requests, the client sends them in accordance with the Poisson distribution. The testing script works in one stream, and if we send requests at a speed of 200 requests per second, and the server for some reason died for 5 seconds, the request queue will grow to 1000. Unfortunately, a lot of load tests behave differently, and Get a separate client thread for each client being emulated.
The client works (via ssh) on a separate machine, which is an important point, because the Lucene server (and not only the JVM) periodically sags in performance (for example, a swap occurs), which can slow down the load client and thus distort the results . Ideally, the client runs on a dedicated machine, and does not experience any pauses. Additionally, the Python garbage collector is disabled on the client to eliminate its negative impact.
Testing on Wikipedia
To test Zing, I indexed the full base of English-language Wikipedia as of 2.05.2012, having a volume of 28.78 GB of plain text, representing 33.3 million documents, about 1Kb in size, including built-in fields and term vectors. Because of this, I can highlight results using the
FastVectorHighlighter class. As a result, the index turned out to be 78 GB. For each test, the server loads the full index into RAMDirectory , after which the client sends requests from the list of the 500th most severe (the most common terms in the documents). At the same time, the server re- updateDocument documents ( updateDocument ) at a speed of about 100 documents per second (~ 100 Kb / s).Each test was performed within an hour, the first 5 minutes required for warming up were excluded from the register. The maximum heap capacity was 140 GB (
-Xmx 140G ). To get a basic level of performance, I also tested MMapDirectory , with a maximum heap capacity of 4 GB. The machine has 32 processor cores (64 with hyper-threading enabled) and 512 GB of RAM, the server is configured to work in 40 threads.I tested various load levels (queries / sec), starting at 50 (minimal) and up to 275 (very large), and then built graphs illustrating the perceptions of response time for various configurations. The default parallel Oracle GC behaved terribly slow (Tens of seconds to clear the memory) so I didn’t even include it in the resulting report. The new G1 collector turned out to be even slower at launch speed (it took 6 hours to load the index into
RAMDirectory , as opposed to 900 seconds when using a competitive CMS collector), and during operation, requests experienced delays of more than 100 seconds, therefore I also did not include the results in the report (This was a surprise as G1 is positioned to work with large heap). Thus, I tested three configurations: CMS, with its default settings and using the MMapDirectory class as the base level, as well as CMS and Zing, using the RAMDirectory class.On the minimum load (50 requests / sec), Zing showed good performance, providing minimal response time, even for the worst cases, while the CMS showed quite a long response time for a sufficiently large number of cases, even when using
MMapDirectory :To estimate the saturation limit of each of the configurations, I plotted the response time for 99% of cases and for different levels of load:
From this graph it can be concluded that for a bunch of
CMS + MMa p, peak performance falls on a level somewhere between 100 and 150 requests / sec. Whereas, when using RAMDirectory , this peak falls on a level somewhere between 225 and 250 requests / sec. This is a terrific performance boost! This result is all the more interesting because if you measure the average response time, then the difference in performance between RAMDirectory and MMapDirectory not so noticeable.Let's build the same graph, but without the results for
CMS + MMapDirectory and also remove the results for a load of 275 queries / s (as it clearly goes beyond the capabilities of our equipment):For the 99% percentile, the Zing performance remains stable, while the CMS begins to show a long response time, starting at a load of 100 requests / sec. Let's look at the figures with a load of 225 requests / sec, which is closest to the saturation limit and when using
RAMDirectory together with CMS and Zing:The time spent on pauses is already significantly longer here than with a load of 50 requests / sec: Already starting with a percentile of 95%, the response time becomes too long: 4479 ms or more.
Zing works!
These tests demonstrate that when using the Zing garbage collector, a very short response time is achieved, even at extreme loads, when the application has a heap of 140 GB in size, and the Lucene index is 78 GB in
RAMDirectory and is fully loaded into RAMDirectory . Moreover, the application performance, measured in the number of requests per second, also significantly increases (approximately twice in the example), and also allows you to safely use RAMDirectory even for large indices, if they are running Zing.Most interestingly, Azul recently announced the availability of JVM Zing for open-source developers to use for development and testing purposes.
Source: https://habr.com/ru/post/148892/
All Articles