Mythology Data Science

Data turns products into products
Humanity has never stood still - the stern law of survival constantly forced it to move forward. In the history of human development, revolutions always took place - one society was replaced by another, and outdated technologies were replaced by more progressive ones. The latest information revolution is associated with the advent of personal computers in the 80s of the twentieth century. As a result of the emergence of new technologies that allow to accumulate information in a new form - digital, an information society has begun to emerge, replacing the industrial one. The Information Society is a society in which the majority is engaged in the production, storage, processing and sale of information. Compared with the industrial society, where all forces are focused on the production and consumption of goods, intelligence and knowledge are consumed in the information society, which leads to an increase in the share of mental labor. The development of information technologies systematically changes the structure of society, and also influences the method of decision-making. People who produce, transmit and process information come to the fore in the information society; specialists in information and communication technologies. Decisions in the information society concerning a large number of people are made by a majority, on the basis of a vote. The reaction time to an event is a matter of minutes, and the event itself becomes known almost immediately. Despite this, some governments that do not understand the evolutionary processes taking place in modern society are trying to restrict access to the most valuable commodity in the new society - information. People who grew up in a society where topics for discussion are artificially limited, and some of them are taboo, will not be complete in comparison with people who have grown up in a society with free access to any information. The necessary censorship will be carried out by the society itself - and the higher the level of development of such a society, the higher will be the level of self-censorship. It is good if the full transition to the information model of society will be smooth, without upheavals and revolutions. Very bad if we have to go through troubled times. Well, we will have the opportunity to follow the developments in the future. However, I did not want to talk about it.
The main value and object of consumption in the information society becomes information, or rather knowledge. Currently, the volume of accumulated data in companies doubles every 18 months and the doubling period is constantly decreasing. The total amount of digital data in the world for 2012 is about 2.7 zettabyte - these are 27 and 20 zeros. An increase of almost 50% compared with 2011, and twenty times more than in 2005. By 2015, predicts a total data volume of 0.8 yottabyte - this is 10 24 .
')

If you look at the growth curve of data, you can see that it takes on an exponential form. And, although most of this data is essentially digital video, photo and audio information, the amount of text data is relatively high. It is not surprising that the term Big Data, which originated quite recently, can be heard now more and more often. It is relatively easy to determine whether a particular instrument or product belongs to the Big Data area - using the rule of three V. This is Volume - volume, Velocity - speed, Variety - diversity. If the object under consideration falls under the definitions of the three V rule, then it belongs to the Big Data domain. Of the wide variety of developing information and communication technologies, three main trends can be distinguished at the current moment — virtualization, clouds, and the area related to storing and processing large amounts of data (Big Data). And before that, the data were the object of study and analysis, but at present this phenomenon is acquiring a truly global scale. No one wants to store data in the data warehouse just like that, allowing them to lay there dead weight. If we take a closer look at the hierarchical information model of DIKW, we find out that the data itself does not represent any interest. Before acquiring any value, they must go through several stages. To be more precise, the data level is at the very foundation, the next step in the DIKW model is information that adds context to the data, then comes knowledge that can already be applied and has some value, the last step is wisdom, which allows to get facts from the data and their basis to make decisions. The DIKW model underlies the concept of data management. However, if the technological base for storing and processing large-scale data already exists and is being actively introduced into the whole world, the theoretical field lags behind it. This was the reason for the emergence of the so-called Data Science - the science of data. More than ten years ago, the term Data Science was coined by Professor William Cleveland, who wrote Data Science Field. And this year, EMC conducted the first Data Science Summit 2012 in Las Vegas, where problems related to the methods of working with data, definitions and problems in this area were considered. By the way, EMC even opened a Data Scientist vacancy in Russia, which indicates that EMC is interested in the development of this area.
In this article I would like to take a closer look at what is behind the term Data Science and who such a data scientist is.
In fact, data science cannot be considered a full-fledged science at the moment, since it is a jumble of a set of methods and technologies for analyzing large amounts of data. Nevertheless, its birth occurs in front of you and me, and now there is a redistribution for the right to call specific technologies and methods related to data science, and there are also debates about the very subject of this science. In a broader sense, data science is what allows you to extract knowledge from a data set. Data science differs from conventional statistics by a more comprehensive approach - all possible sources are used for analysis, including not only tables with dry statistics, but also other data.
This significantly complicates the search for specialists in this field, since they simply do not exist. Specialists must combine a rare set of qualities: curiosity, knowledge of mathematical statistics, a broad outlook in the field of information technology, the ability and desire to discover new things, be familiar with the latest achievements in the field of Big Data, the ability to involve a variety of data and methods for their processing. He expressed the requirements for data scientists Michael Lukidis quite well in his article “What is Data Science”, published in the journal O'REILLY RADAR. Also, these requirements can be presented at the intersection of three circles in the picture below:
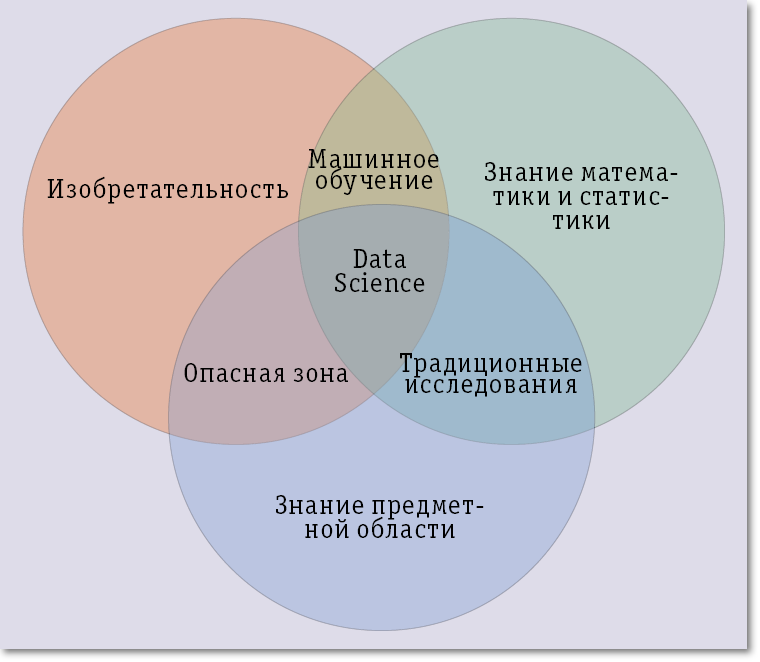
Despite this, you should not attribute the data scientist to a scientist in a white coat who invented revolutionary technologies in his laboratory. Most likely, it is better to characterize a data scientist as a person who knows the methods of mathematical statistics, is familiar with the basic tools, a person with a broad outlook in the field of information technology, especially Big Data, who has previously been engaged in theoretical research in this area.
One of the main topics for discussion at the last Data Science Summit 2012 conference was the topic of finding such specialists in the world, as well as their future prospects. If we look at the dynamics of data growth, as well as the rapid development of information and communication technologies, it is easy to conclude that in the future the need for such specialists will only increase, and the demand for them will constantly increase. Some governments have already appreciated the prospect and have taken appropriate steps - the US National Science Foundation has equated the Big Data theme to the scientific field, announcing new areas of funding for interdisciplinary research on Big Data, to which a whole series of spring announcements is timed.
In order to have a more complete idea of who the data scientist is, I will offer a list of questions that may be asked to the applicant for this vacancy. I must say that the list for review and data scientist, unfortunately, we do not need: (
Question 1:
How do you calculate the variance of the columns of the matrix in the language R without using cycles?
Question 2:
Suppose you have a CSV file with two columns: 1 - first names, 2 - last names. Write code using a scripting language to create a CSV file with last names in the 1st column and names in the 2nd column.
Question 3:
Explain Map / Reduce, and then write a simple example using it in your favorite programming language.
Question 4:
Suppose you are a Google and want to evaluate the click through rate (CTR) of your ads. You have 1000 requests, each of which was called 1000 times. Each request shows 10 ads and all ads are unique. Estimate the CTR for each ad.
Question 5:
Suppose you did a regression with 10 variables, one of which is significant at a 95% confidence interval. You will learn that 10% of the data in a random order was missing, and their Y values are deleted. How would you predict the values of the lost Y?
Question 6:
Suppose you have the opportunity to go to one of the two branches of the bank. In the first branch there are 10 cashiers, each of whom has a separate queue of 10 clients, in the second branch there are 10 cashiers, with one common queue of 100 clients. Which department would you choose?
Question 7:
Explain how the Random forest differs from the normal regression tree?
Source: https://habr.com/ru/post/148856/
All Articles