The problem of "two or more teachers." First touches
In the two previous articles, I touched upon the problem, which I called the problem “two or more teachers”:
1. Model of functional separation of consciousness and unconscious. Introduction
2. Model of the manifestation of consciousness or ANN without the effect of forgetting
Now I would like to deal with it in more detail. This is a complex and still in principle unsolved theoretical problem from the field of artificial intelligence . I cannot clearly formulate it, and not to solve it. But I constantly meet her in various tasks, and all the time I stumble about her. These previous articles could show its importance in terms of understanding what consciousness is. But it's still the lyrics. And here I would like to speak more technically.
')
Here I will show how I first encountered this problem since 2006, but now the exact same problem is clearly visible when solving the bioinformation problem of folding RNA (I also wrote a series of articles about this, the last one in which there are all links ). The external description of these tasks is essentially different, but this is the beauty of it - the problem arises regardless of the task, and it seems there is an important aspect that you just need to be able to solve when talking about intellectual methods.
There was a time when I was a fan of the game of civilization . I must say that its first versions were the most intelligent, and in the version after Civilization II: Test of Time you can not play at all - they spoiled the important intellectual stuffing. Therefore, it is not at all surprising that below I will offer a computer to play a sketch for this game.
It is important to note that they arrange tournaments with similar scenarios, for example, ICFPC 2012 with crowdsourcing and neural networks , playing the Supaplex game. This is also an interesting task, but the problem of “two or more teachers” does not arise in it. Therefore, the purpose of this article is to understand when this problem occurs.
upd. It seems that the first touches turned out to be somewhat complicated. Please read the introductory article Learning with reinforcement on neural networks for understanding . Theory
Rules of the game
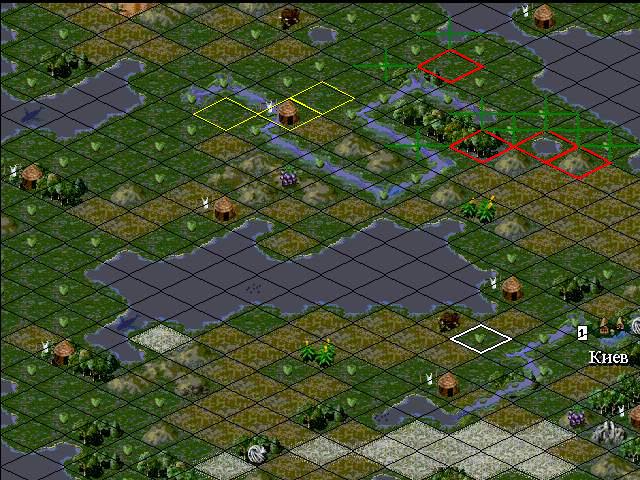
The model environment is a map of the area, divided into 276 squares (areas) of various types - meadow, plain, ocean, river, etc. (total 16 types). In Figure 50, the course in the simulation. The red square is “City Center”, the yellow square is “settler”, the green cross is “resident”
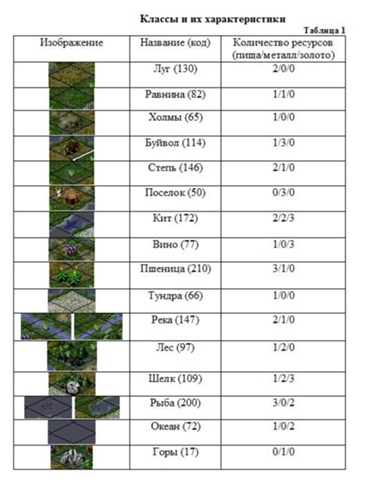
Each type of territory differs in the amount of resources that can be obtained by processing this territory. There are three types of resources - food, metal, money. The table shows all the classes and their characteristics.
The game begins with a settler who fits in a random position on the map. The task of the settler is to choose a place for the future city, necessary in order to process the terrain on the map. The visibility card for the settler is 25 squares (radius 2 squares around it).
Having made his choice, the settler builds a city, and he disappears - turns into a single resident of the city. The city covers an area of 9 squares (radius 1 square around it), potential for choosing a treatment place. The city center is always considered to be processed. Outskirts (8 squares) can be processed by residents, for one inhabitant - one square. The choice is made static at the time of the appearance of the resident. Thus, immediately after construction, a place is selected for processing. Then, when a certain amount of food is accumulated in the city’s warehouses, a resident appears (and the task of choosing a processing place is set), and when a certain amount of metal is accumulated, a new settler appears (and the task of choosing a place for a new city appears).
The amount of food needed for a new resident to emerge depends on the size of the city (the number of inhabitants of this city). With one resident you need 20 units. Meals, with two - 30 units. etc. The amount of metal needed to create a settler 40 units.
The task is to choose a strategy in which in 80 moves you can get the most money.
Teacher
Teacher training is designed to ensure that the agent can at least rationally behave in the environment. Such rational behavior can be beneficial if the resources are evenly distributed over the territory of the map, as well as with approximately the same importance of each of the resources. This is due to the fact that the teacher trains the agent to evaluate each of the 8 movements in accordance with the method of weighted evaluation of alternatives.
Namely, out of 8 alternatives for each resource is the maximum and minimum value of resources summarized over the entire area of the city. The values of all resources are reduced to the same scale.
(Value_i - min / maxmin) * 255, where maxmin - the difference between the maximum and minimum among the 8 alternatives of this resource. The values obtained are estimates.
Problem as it is
Teaching agent may change over time. But how? Based on what? Actually, it is desirable after winning in the next game from 80 moves, i.e. when a large amount of money is accumulated. But how to fix it? Here a problem arises - how to describe the whole sequence of 80 moves, with all possible states. And it turns out this is not possible, too much need to have an idea. Yes, and in fact it is very redundant. It turns out you need to have a few simple strategies to win.
Well, for example. In principle, this task is calculated ... if you know that it lasts 80 moves, if you know under what condition a new resident appears in the city and a settler, if you know what types of territories exist and how much resources there are on each of them, and most importantly, by what parameter success is estimated. Then, for all other uncertainties, the task is hard calculated and at least you can write an algorithm that calculates it.
For a degenerate case when there are only two types of territories - Ocean (1/0/2) and Steppe (1/1/0) - the strategy is as follows: it makes sense to set the goal of the city - to get a settler (steppe + steppe), only when to the middle games he can provide 2 or more settlers. After 25% of the game, you should use a mixed strategy (steppe + ocean), and after 50% of the game you have played, increase only the volume of gold (city type ocean + ocean). Degeneracy is that cities do not grow here, because food increment is only 2 units, which is equal to its consumption per inhabitant (I remind you that the city center is processed without a resident). In the end - we get 484 units. gold ... and no other strategy can improve the rate.
In essence, each of these tactical strategies is another fitness function. So it turns out that having a basic tactical strategy received from a teacher, you need to find such parameters that will allow you to form a certain tactical strategy. And already in the course of the game to change these strategies.
In general, it turns out difficult. Simplifying it is necessary to understand that any successful strategy found (heuristics) is nothing but another fitness function. Those. This is essentially another "teacher." But the problem of learning from two or more teachers is to harmonize two suitable tactical strategies into one.
I do not know how much I managed to describe the problem clearly ... but write that it is not clear, help who deign to delve into the problematic.
In the next part, I will try to describe the same problem in the task of folding RNA, which will no longer be a “toy problem”. But it will be more difficult in detail, but the type of tactical strategies will be simpler.
I have a goal to make a clear mathematical problem out of this that would not be explained through applied tasks - but somehow it is rather complicated. Waiting for help.
1. Model of functional separation of consciousness and unconscious. Introduction
2. Model of the manifestation of consciousness or ANN without the effect of forgetting
Now I would like to deal with it in more detail. This is a complex and still in principle unsolved theoretical problem from the field of artificial intelligence . I cannot clearly formulate it, and not to solve it. But I constantly meet her in various tasks, and all the time I stumble about her. These previous articles could show its importance in terms of understanding what consciousness is. But it's still the lyrics. And here I would like to speak more technically.
')
Here I will show how I first encountered this problem since 2006, but now the exact same problem is clearly visible when solving the bioinformation problem of folding RNA (I also wrote a series of articles about this, the last one in which there are all links ). The external description of these tasks is essentially different, but this is the beauty of it - the problem arises regardless of the task, and it seems there is an important aspect that you just need to be able to solve when talking about intellectual methods.
There was a time when I was a fan of the game of civilization . I must say that its first versions were the most intelligent, and in the version after Civilization II: Test of Time you can not play at all - they spoiled the important intellectual stuffing. Therefore, it is not at all surprising that below I will offer a computer to play a sketch for this game.
It is important to note that they arrange tournaments with similar scenarios, for example, ICFPC 2012 with crowdsourcing and neural networks , playing the Supaplex game. This is also an interesting task, but the problem of “two or more teachers” does not arise in it. Therefore, the purpose of this article is to understand when this problem occurs.
upd. It seems that the first touches turned out to be somewhat complicated. Please read the introductory article Learning with reinforcement on neural networks for understanding . Theory
Rules of the game
The model environment is a map of the area, divided into 276 squares (areas) of various types - meadow, plain, ocean, river, etc. (total 16 types). In Figure 50, the course in the simulation. The red square is “City Center”, the yellow square is “settler”, the green cross is “resident”
Each type of territory differs in the amount of resources that can be obtained by processing this territory. There are three types of resources - food, metal, money. The table shows all the classes and their characteristics.
The game begins with a settler who fits in a random position on the map. The task of the settler is to choose a place for the future city, necessary in order to process the terrain on the map. The visibility card for the settler is 25 squares (radius 2 squares around it).
Having made his choice, the settler builds a city, and he disappears - turns into a single resident of the city. The city covers an area of 9 squares (radius 1 square around it), potential for choosing a treatment place. The city center is always considered to be processed. Outskirts (8 squares) can be processed by residents, for one inhabitant - one square. The choice is made static at the time of the appearance of the resident. Thus, immediately after construction, a place is selected for processing. Then, when a certain amount of food is accumulated in the city’s warehouses, a resident appears (and the task of choosing a processing place is set), and when a certain amount of metal is accumulated, a new settler appears (and the task of choosing a place for a new city appears).
The amount of food needed for a new resident to emerge depends on the size of the city (the number of inhabitants of this city). With one resident you need 20 units. Meals, with two - 30 units. etc. The amount of metal needed to create a settler 40 units.
The task is to choose a strategy in which in 80 moves you can get the most money.
Teacher
Teacher training is designed to ensure that the agent can at least rationally behave in the environment. Such rational behavior can be beneficial if the resources are evenly distributed over the territory of the map, as well as with approximately the same importance of each of the resources. This is due to the fact that the teacher trains the agent to evaluate each of the 8 movements in accordance with the method of weighted evaluation of alternatives.
Namely, out of 8 alternatives for each resource is the maximum and minimum value of resources summarized over the entire area of the city. The values of all resources are reduced to the same scale.
(Value_i - min / maxmin) * 255, where maxmin - the difference between the maximum and minimum among the 8 alternatives of this resource. The values obtained are estimates.
Problem as it is
Teaching agent may change over time. But how? Based on what? Actually, it is desirable after winning in the next game from 80 moves, i.e. when a large amount of money is accumulated. But how to fix it? Here a problem arises - how to describe the whole sequence of 80 moves, with all possible states. And it turns out this is not possible, too much need to have an idea. Yes, and in fact it is very redundant. It turns out you need to have a few simple strategies to win.
Well, for example. In principle, this task is calculated ... if you know that it lasts 80 moves, if you know under what condition a new resident appears in the city and a settler, if you know what types of territories exist and how much resources there are on each of them, and most importantly, by what parameter success is estimated. Then, for all other uncertainties, the task is hard calculated and at least you can write an algorithm that calculates it.
For a degenerate case when there are only two types of territories - Ocean (1/0/2) and Steppe (1/1/0) - the strategy is as follows: it makes sense to set the goal of the city - to get a settler (steppe + steppe), only when to the middle games he can provide 2 or more settlers. After 25% of the game, you should use a mixed strategy (steppe + ocean), and after 50% of the game you have played, increase only the volume of gold (city type ocean + ocean). Degeneracy is that cities do not grow here, because food increment is only 2 units, which is equal to its consumption per inhabitant (I remind you that the city center is processed without a resident). In the end - we get 484 units. gold ... and no other strategy can improve the rate.
In essence, each of these tactical strategies is another fitness function. So it turns out that having a basic tactical strategy received from a teacher, you need to find such parameters that will allow you to form a certain tactical strategy. And already in the course of the game to change these strategies.
In general, it turns out difficult. Simplifying it is necessary to understand that any successful strategy found (heuristics) is nothing but another fitness function. Those. This is essentially another "teacher." But the problem of learning from two or more teachers is to harmonize two suitable tactical strategies into one.
I do not know how much I managed to describe the problem clearly ... but write that it is not clear, help who deign to delve into the problematic.
In the next part, I will try to describe the same problem in the task of folding RNA, which will no longer be a “toy problem”. But it will be more difficult in detail, but the type of tactical strategies will be simpler.
I have a goal to make a clear mathematical problem out of this that would not be explained through applied tasks - but somehow it is rather complicated. Waiting for help.
Source: https://habr.com/ru/post/148809/
All Articles