Informative about PGM protocol
In this article I would like to talk about the most popular protocol that provides reliable delivery of multicast messages. This protocol is called PGM (pragmatic general multicast) . Other reliable protocols over IP multicast, such as LBT-RM (from 29west) and SmartSockets (from TIBCO Software) are, in one way or another, a modification or implementation of PGM.
Like many other good innovations in network software and hardware, the PGM specification originated inside Cisco Systems. The main problem that they tried to solve in the process of standardization of a reliable multicast is control and protection from congestion in the network. Congestion can usually occur due to messages that will not be able to be processed by listeners or excess service packets that reduce the useful throughput of the protocol.
')
The principles used in TCP, thanks to which the Internet works efficiently, are not suitable for multicast. TCP allows you to dynamically change the amount of data that has been sent but not yet confirmed (transmission window) so that the sender of TCP messages can adapt to the listener. It is clear that this is not suitable in the case when there are many listeners, and the sender is one.
Types of packages
To begin with, we will define terminology. The protocol contains the following types of packets:
ODATA - payload sent via multicast (IP Multicast)
NAK is a negative acknowledgment packet sent by a unique (usually UDP) listener who found the missing ODATA to the next node in the path tree
NCF - acknowledgment of receipt of the NAK, which the tree node sends by a multicast to all listeners in the subnet in which the NAK was received
RDATA - the data packet of which is duplicated by ODATA, published by the sender on the multicast topic in response to the received NAK
SPM - message paths and hertbit, packages are published on multicast at regular intervals and in the absence of ODATA packages
The main features of the protocol
Let's consider the following example: we have a grid for 100 wheelbarrows, each of which has a very different hardware and operating system. We are developing a server application that sends messages at various small intervals (for example, the price of a stock) to applications that are running on these wheelbarrows. To use transport unique protocols in this case means to copy data for each client. The complexity of sending a package will grow linearly with an increase in the number of subscribers. Multicast is just that wonderful technology that will allow to send one packet to several listeners, having made just one entry into the socket buffer on the sender's side, and the packet will be copied to the router. Thus, an increase in the number of listeners will not affect the package delivery time.

This is great, but there is a problem: a multicast, like UDP, does not guarantee delivery and order of packets. Even to people far from trading on the stock exchange, I think it is not difficult to guess what will happen with the application that will miss the quota for some symbol. If the subscriber is a robot performing automatic purchases / sales for some strategies, then without receiving a quota, the robot does not know that the price has changed and can produce an unprofitable deal. The most natural way to guarantee delivery is to use acknowledgment messages received (positive acknowledgment) as in TCP. But here two problems arise - the first is that the server will have to process the confirmation from each subscriber, that is, the complexity will again become linear and the second is a large amount of multicast of the same data when packets are often lost.
The PGM protocol solves the first problem by the fact that, instead of confirming each received message, this protocol confirms each missing message (negative acknowledgment). Each protocol packet contains a sequence number and the listener sends a PGM acknowledgment to the sender of the package uniquely if it detects that one of the sequence numbers is missing. In order to exclude the possibility of loss of the last packet in the series (tail-loss), the PGM source in the absence of useful messages sends special packets — herbert beats (heartbeats) whose task is to maintain the current sequence number on the side of the listener.
To solve the second problem, PGM stores and keeps up to date the path tree from each sender of multicast messages to listeners. Each node of the tree knows where the packet came from, and if a leaf of the tree (the listener of multicast messages) found that the packet was not received, confirmation of the lost packet may go up from the leaf to the root of the tree (the sender of the multicast messages). A status is set at each node of the tree, meaning that a packet is lost on the subnet. When resending, a lost packet can be ignored on nodes where this state is not set and only reaches those subnets where the packet was lost. Maintaining the path tree is achieved through path messages (messages) that are sent to multicast groups at equal intervals of time by each sender.
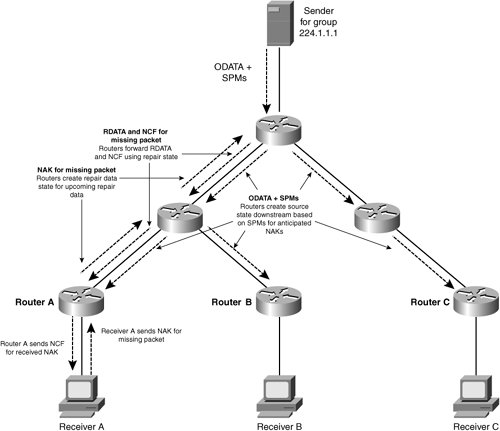
Do not confuse messages to maintain the current sequence number or hertbit and message path. Although they duplicate the information that is delivered to the listeners, they differ in that the path messages are sent at regular intervals, while the Hertbits are sent using a more complex algorithm. Hertbitas are defined by two parameters: the initial timet of the hertbit and the number of hertbitas. The first hertbit is sent after a timeout after the last packet. The second herbit is sent twice as long after the previous hertbit. And so on until the right amount of Hertbeats has been sent.
Schematically, it looks like this:
| ____ | _________ | __________________ | _________________________________ | ____
time t ->
where the first dash is the last packet with the payload, and the rest are hertbit.
Nak storm
Not everything is as smooth in PGM as it may seem at first glance. Many who try to use PGM drop out of business because of a problem known as NAK Storm. If we go back to the example of a network over which shares are sent out, then there can be a NAK storm if one of the listeners is too slow and does not have time to read the data from the socket buffer. Coming packets will be ignored because the buffer is clogged and such a client will send many NAK packets (crying baby receiver). In response, the sender will have to publish RDATA packages, which will increase the load on the sender and on all its multicast subscribers, some of which can also become slow clients. A NAK storm is dangerous in that a single source of PGM packets can have a lot of listeners. After processing one NAK and sending an RDATA packet, the source can immediately receive a NAK on the same ODATA packet from another listener. Plus, the listener who detects the loss of the ODATA packet will send a NAK until it receives the NCF. This all can lead to a significant decrease in the protocol's efficiency, since most of the network bandwidth will be spent on sending NAK, NCF and RDATA instead of ODATA.
The PGM protocol has several mechanisms for reducing the negative impact of various kinds of congestion in the network. The number of NAKs that a source receives can be reduced with the help of special listeners of multicast messages - NAK aggregators (designated receiver). These aggregators listen to NAKs on the subnet and send only one NAK to the source from the entire subnet. There are routers capable of independently aggregating NAKs from a subnet, these are PGM routers.
PGM also allows the presence of special network elements (designated local repairer or designated local retransmitter), which can independently respond with RDATA packets to the NAK. This allows you to build a topology in which slow clients do not affect the work of students from other subnets.

PGM also allows you to set different options - timeouts and counters to suppress the NAK storm. The selection of these timeouts is a separate magic, in which lies the difficulty of working with PGM. On the listeners side it
- the time that passes after detecting packet loss before the first NAK is generated
- the time that passes before re-sending the NAK if the NCF was not received
- the time that passes from receiving the NCF to sending a new NAK if RDATA was not received
- maximum number of NAKs that a listener can send
On the sender side it is
- the time that elapses between receiving the first NAK and sending the RDATA
- time for which duplicate NAKs are ignored after RDATA has been sent
- rate limit on which RDATA packets are sent (bytes per second)
In general, I think from the foregoing it is not difficult to guess why PGM and its variations have become so popular when developing systems with low response time (low-latency systems). This protocol has a shorter response time than reliable protocols using positive packet acknowledgment, and allows you to increase the number of message listeners without compromising response time.
A question for thought. Why do GFS and Hadoop use TCP instead of reliable multicast? It’s a known fact that all data is replicated in GFS and HFS to at least three different boxes. Is it really possible to copy packets from a socket to a socket more efficiently or reliably than to replicate packets on network equipment?
Source: https://habr.com/ru/post/148444/
All Articles