How we connected our data center with the customer data center
Submit a task:
- You have decided to start an IT project that requires a lot of processing power.
- "Fly" or not, it will become clear in 3 months.
- Cosmically expensive hardware (several servers at the price of an apartment in Moscow each) do not want to buy, but you must immediately start so that then there are no difficulties with scaling up to a serious highload system, that is, you want an elastic “cloud”.
- In the future - the need to quickly process a lot of data and a lot of read-write operations. That is, you need heavy threshing servers that cannot scale horizontally — you can't push this into the cloud.
- At the same time, it is necessary to create a single network space, as if the “threshers” of your data center and the “cloud” server were in adjacent racks, and set everything up so that at the application level you do not have to think about the physical embodiment of iron;
- Provide adequate technical support that is able to close all questions on the project (network, servers, application systems) - and all this without searching for new administrators in the staff.
- Heap - run very quickly;
- And all this is in Moscow to ensure minimal lags.
At the beginning of this year, the customer came to us with exactly such tasks.
Let me remind you that CROC works with fairly serious customers at the level of large banks and telecom companies. For these customers, we have three of our data centers, plus we have already built dozens of data centers to various companies.
')
The first thing that is needed for stability and manageability is data center connectivity and high availability of channels. We have an optical ring between our data centers with access to MSK-IX for direct access to the “big Internet”. Physically, this ring is two optical channels in different sewers.
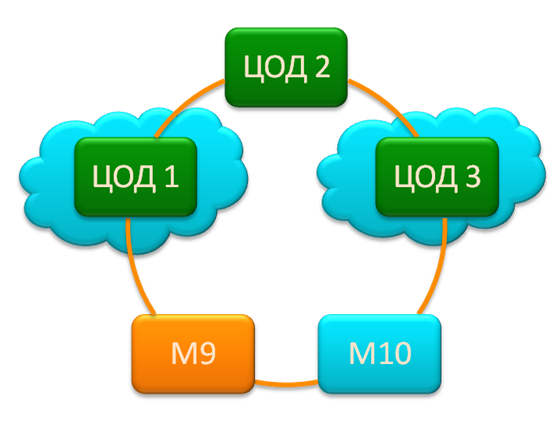
From the point of view of disaster recovery, even a meteorite hit one of the data centers does not mean a system failure: if the bank, for example, has disaster-recovery solutions, then the second data center will immediately pick up the fallen services.
In data centers, collocation services are available (placement of racks / equipment) and the provision of virtual computing resources based on the “cloud” - machines, disks and networks.
The project architecture had a standard three-level scheme:
- Web machines that accept user requests (frontend).
- Application servers that handle requests.
- Database servers: read-write, in the jargon - "threshers".
The first two points are the usual cloud with “x-ray” iron (x64). If necessary, the cloud horizontally elastically scaled and gives as much computing power as needed. At the third level, in the future, we will need a piece of hardware from the category of so-called “heavy” UNIX servers.
Suppose now the third point of the customer does not care. But when the customer needs to grow, the third level will require a RISC-server, worth many millions. These pieces work under control of special OSes (AIX, HP-UX and so on). The listed operating systems do not work on regular x64 hardware that runs Windows or Linux OS. Accordingly, for example, AIX fails to do on x64 virtual resources. The solution is this: we put a heavy piece of hardware, connect a disk array to it, and then “stick” the whole thing into the “cloud” through a special gateway so that the physical and virtual network can work together. Roughly speaking, the mid64 from x64 refers to the “threshing machine” as a resource on its network.

IBM Power 795: one of the "heavy" machines
According to the task, these costs need to be converted from capital to operational. And here the most interesting begins: the fact is that we deploy the iron for the project, simply by offering the necessary service. For the customer, this means that all expenses are rent and support.
Starting alignment
- The customer is a large financial institution. He has a promising project that requires large computational resources and work with a large base. At the same time, he is considered a “start-up” within the company, that is, there is a chance that the “take-off” will not take place, and therefore it is inappropriate to buy iron and separate a separate team.
- We need to start quickly, despite the fact that there are only 2 people on the customer’s IT team: the IT project manager and his deputy, without engineers (because there is a pilot project).
- The heaviest Oracle Siebel CRM works, which immediately raises the complexity of the project from normal to extremely high (taking into account the requirements for information security, scalability and availability).
- It is necessary to minimize costs in case the project “does not fly up”.
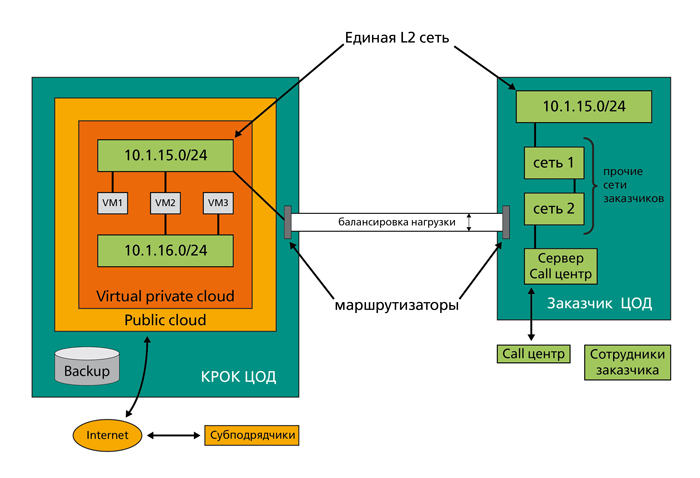
- There are two sites, our data center and customer data center, also in Moscow. We have a public cloud within which a VPC (Virtual Private Cloud) is deployed. There are virtual networks in VPC, virtual servers in networks. Customer data center connects to an isolated chunk (VPC) of the cloud.
Tasks and Solutions
1. Full control of the network environment in the KROK cloud as in its data center
In a public cloud, all networks have a predefined internal addressing. If this addressing intersects with the addressing of the customer’s data center, a natural brain explosion occurs. The problem is more complicated than it may seem at first glance: you need to make sure that there are no such intersections at the start of the project, plus that they will not be architectural in principle, no matter how the project goes on. That's why VPC was needed: this thing allows the customer to control the addressing and other cloud network settings from the self-service portal.
2. Secure access and full control
The networks inside the customer’s data center should directly connect to the networks in our cloud. Roughly speaking, you need to make sure that internal administrators do not even understand where they are located in their data center or in virtual. This is a hybrid cloud: the customer has its own resources (not a lot of physical hardware), plus there is our cloud platform, which can give as much power as necessary. In the jargon - elastic pristezhka to your data center under the full control of the administrators of the customer.
Point-to-point communication channels are used when no one except the customer participates in the exchange between data centers. On the physical level, these are two channels of independent providers. They operate in an active-active mode with load balancing and automatic switching in case one of them falls. In the data center, we and the customer have channel-forming equipment - Cisco routers - distributing data over the networks further. In general, we learned to lock direct links from customers to the “cloud”, so far no one knows how. Tell any cloud provider: “Is it possible, we will drill our hole in the cloud, otherwise your Internet channel is not really liked by us?” And two holes? And is your equipment in your cloud possible? ”The answer is predictable. And the solution, if it exists at all, will not be flexible.
3. I needed a server to record call-center conversations
The use of the cloud platform is not entirely suitable here, since the specifics imply the recording of a large amount of data that would have to be driven over the network from the data center to the data center. This is not entirely correct: there is a risk to “score” channels. The best option is iron on the customer side. Considering the requirements of minimizing capital costs, we provided the equipment for rent to the customer and put it on his side.
4. Full support
Naturally, the customer needed full technical support for the cloud platform, network equipment, application software, information security, backups (EMC AVamar). Provided, set up. The tasks are standard for large projects, yet these are the specifics of integrators.
It works like this: when an IT specialist on the customer’s side calls us, he gets into a “one window” that works until the problem is completely solved. For example, the appeal “we have something with the network” does not end with “everything is in order with the network”, but “everything is in order with the network, but there was a problem in the settings on your side, everything was decided, the service was started”.
Total
Data center - in the lease. The cloud is in the lease, the server for the call-center and all network equipment are also in the lease. Technical support is paid monthly. The customer did not need a new IT team. If you need to add more computing power, this is done by two clicks in the self-service portal of the cloud.
If the project "does not work" - the lease is terminated, the risks are minimal.
If “takes off” - comfortable work continues. As the demand for resources increases, the customer simply launches them, the system scales easily: you do not need to move anywhere, and the architecture does not change. For security, scaling, support, accessibility, and other issues, a very strong team responds. From the point of view of the customer's IT department, there is one contact manager who decides everything.
PS Specifically, this project "took off."
Source: https://habr.com/ru/post/148359/
All Articles