HP P6000 system performance and best practices for organizing data storage
 The P6000 EVA storage system is designed and optimized for working in a virtualization environment and with database applications. The technological and operational advantages of HP EVA disk arrays are ensured primarily by the fact that they implement one of three possible virtualization schemes - virtualization at the storage system level. Together with two other schemes - at the server level and at the network level, it provides the abstraction of logical and physical storage resources. Storage-level virtualization is implemented using disk array controllers that ensure server independence. This type of virtualization allows you to consider all the physical disks that are part of the drive as a single pool of storage resources available to all servers connected to it. Virtualization ensures efficient use of storage space, simplifies the management process and, as a result, reduces the cost of data storage.
The P6000 EVA storage system is designed and optimized for working in a virtualization environment and with database applications. The technological and operational advantages of HP EVA disk arrays are ensured primarily by the fact that they implement one of three possible virtualization schemes - virtualization at the storage system level. Together with two other schemes - at the server level and at the network level, it provides the abstraction of logical and physical storage resources. Storage-level virtualization is implemented using disk array controllers that ensure server independence. This type of virtualization allows you to consider all the physical disks that are part of the drive as a single pool of storage resources available to all servers connected to it. Virtualization ensures efficient use of storage space, simplifies the management process and, as a result, reduces the cost of data storage.A few simple tips described in this article will allow you to correctly optimize the work of storage systems and will allow you to quickly adapt to changes in the business in the future.
HP EVA arrays are an example of how these qualities are implemented in low-cost disk arrays, intended for both small and medium-sized businesses and corporate clients. One of the main advantages of virtualization, implemented in the HP EVA family of drives, is high performance and load balancing, allowing you to evenly distribute the access to physical disks.
As can be seen from the figure, with traditional use of RAID, the entire load is concentrated on the physical disks that are included in the corresponding RAID arrays. In this situation, the load may be more or less, depending on the operating mode of the applications, while with the support of virtualization all disks are evenly loaded, therefore, the overall performance becomes higher.
')

Let's start with a description of the internal structure of EVA systems. This description applies in almost unchanged to all generations of EVA.
In previous articles it was written about the basic concepts of storage EVA such as disk group, virtual disk (LUN).
Each disk group is divided into the Virtual Controller Software (VCS / XCS) management software on Redundant Storage Sets (RSS) to improve the fault tolerance of this disk group. It can be considered as a set of mini-RAID groups that form one large shared disk group.
If it is necessary to record information in this disk group, an equal volume is written into each RSS (for example, 30MB of information is recorded in 3 RSS at 10MB in RSS).
Consider clearly how the process of separation.
Traditional storage arrays are characterized by the fact that certain drives are used to store data of the same RAID level.

For virtualized EVA systems, all drives can be used to store data in different RAID levels.
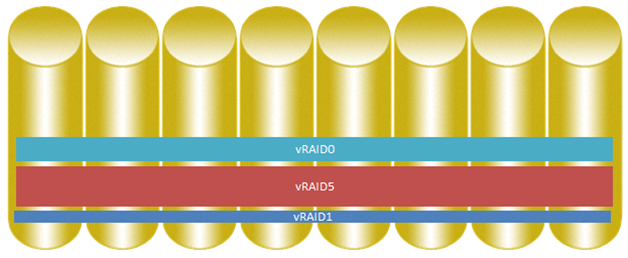
Each EVA volume thus receives IOPS from all disks that form a virtual disk, which gives an increase in performance.
1. The XCS control software divides each disk into equal blocks. The block size depends on the version of the array, the version of the control software, the segment size varies 2/8 MB.
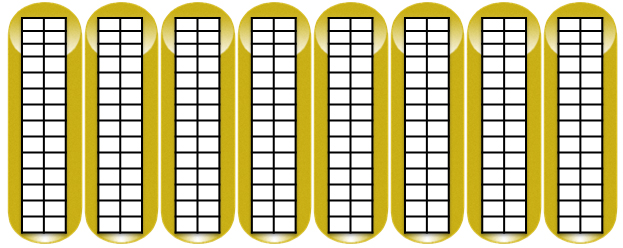
2. Next, groups of 8 disks (RSS) are formed; in each RSS, the amount needed to protect data from disk failure, depending on the preferred RAID level, is reserved.
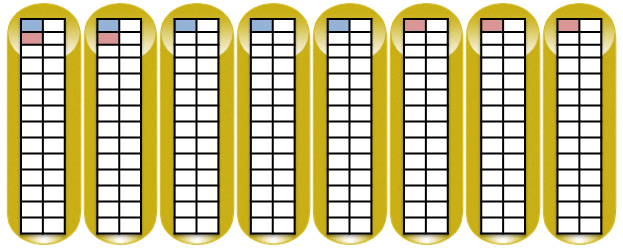
3. EVA follows certain algorithms for selecting RSS members to ensure maximum availability and better utilization of disk space:
- RSS members are selected vertically between different disk shelves
- RAID pairs are selected between different disk shelves.
For clarity, the disks from different shelves are placed in a row. An example of writing two data blocks of 8 MB each in RAID5 (4 data blocks and 1 parity block) is shown schematically using the example of EVA 4400.
When adding disks or when a disk fails, the process of moving triggers and rebuilding RSS begins only if the changes that occur can cause a loss of information (if a disk containing participants of the vRAID1 pairs fails, the restructuring process receives the highest priority when the disk consisting of from participants vRAID5 priority adjustment below). The priority of the process of restructuring RSS is selected based on an assessment of the priorities of other processes in the array. This process takes place in the background and does not affect performance.
During the operation of the storage system, it may also be necessary to install additional disks without interruptions in service — this is extremely easy to do in the conditions of virtualization.
With distributed redundancy supported by virtualization tools, data recovery after the failure of one of the physical disks is much faster than in traditional schemes, where it is necessary to keep some number of detached disks in the hot backup mode. Acceleration is achieved due to the fact that backup disks are included in the common pool on an equal basis. As a matter of fact, there are no special backup disks, but there is some reserve of capacity. If one disk fails, then a normal administration tool will change the balancing between the disks and restore the VRaid structure. This is a very quick procedure, and its consequence is only a reduction of the reserve, which can be restored without interruption in service.
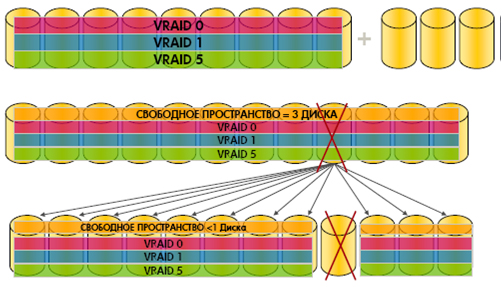
In the array to optimize the load on disks and controllers, there are processes of uniform distribution:
1. The process of uniform distribution of RSS in a disk group
2. The process of evenly distributing data within each RSS.
The process of reconstruction of disks has a higher priority than the process of uniform distribution. Fail safety data is preserved.
When a drive fails, there are best recommendations:
1. Replace a failed disk before changing the configuration of the disk group
2. Replace the failed disk with a similar volume and speed
3. A new disk must be placed in the same location as the failed one.
For example, in a configuration with 50 disks per array, up to 6 disks can fail simultaneously, so that data in VRAID5 remains available or a simultaneous failure of 25 disks for VRAID1 (but with so many failed disks there is a high probability of metadata corruption) .
Due to the fact that the data of each LUN is distributed across different RSS, which, in turn, consist of disks in different disk shelves, this ensures high performance of the entire array. Each drive adds IOPS, which can be issued by a LUN for a host application.
Based on the Best Practices document, there are several important recommendations that will improve the performance of a disk array:
1. Use the latest firmware version of controllers, disks, devices to which the array is connected.
2. Use the number of shelves, a multiple of 8 - this will optimize the distribution of disks within the RSS.
3. Add disks to a disk group by a multiple of 8.
4. Use disks of the same size and speed in the disk group. When using disks of different sizes and speeds, the cost of supporting an array increases. For example, if you place a large disk in a disk group consisting of small disks, the resulting effective volume of this disk will be equal to the volume of the smallest disk in the group.
5. Create as few disk groups as possible - this will allow the data to use the maximum number of disks, and therefore produce the best performance parameters.
6. Performance is maximum when an array distributes data across as many disks as possible.
7. For most installations, the protection level of one provides adequate data availability.
8. Separate data from database logs from other data.
9. For maximum performance parameters use Solid State Drives.
10. Allow the EVA controllers to load balance themselves.
11. All best practices for data centers are based on regular copying of data to external backup devices or to a separate disk group on large-volume MDL SAS disks.
12. Use Inside Remote Support to automatically report problems with the array in the HP Support Center.
A separate item can describe the process of moving LUNs and changing the vRAID level of a virtual disk. These operations use mirror copies to copy data into groups with new parameters. As soon as the mirror copy is synchronized, the roles of the copy and the main volume change. Host data automatically accesses the new volume. This functionality is available after purchasing a license HP Business Copy. After copying both volumes remain, the volume with the old parameters becomes a copy, if desired it can be deleted.
Materials:
1. HP P6000 Best Practices
2. HP with VMware best practices
3. HP P6000 QuickSpecs
PS This topic is only a few materials about the device arrays P6000, available for publication.
Source: https://habr.com/ru/post/148353/
All Articles