Java shared memory and off-heap caching
Last week, a successful experiment was launched to launch a new solution for download service. One fairly modest server (2 x Intel Xeon E5620, 64 GB RAM) running a proprietary Java application took over eight Tomcat loads, serving more than 70,000 HTTP requests per second with a total bandwidth of 3000 Mb / s. Thus, all Odnoklassniki traffic associated with user emoticons was processed by one server.
It is quite natural that high loads required non-standard solutions. In a series of articles on the development of high-load Java server, I will talk about the problems we had to face and how we overcame them. Today we will talk about caching images outside the Java Heap and using Shared Memory in Java.
Since drawing images for each request from the storage is not an option, and there is no question of storing pictures on the disk (the disk queue will become a server bottleneck much earlier), you must have a fast cache in the application's memory.
')
The cache requirements were as follows:
The fastest way to access memory outside of Heap from Java is through thememory-mapped files . However, it was extremely undesirable to associate the cache with a real file on the disk (performance would be badly affected by disk access), so the application’s address space displays not a real file, but a shared memory object. In this case, of course, the cache will no longer be non-volatile, but, most importantly, will allow you to restart the application without losing data.
In Linux, Shared Memory objects are implemented using a special file system mounted to
Now the created file object should be mapped into the address space of the process and get the address of this memory location.
Let's use the Java NIO API:
The main disadvantage of this method is that it is impossible to display files larger than 2 GB, as described in the Javadoc to the map: must be non-negative and no greater than Integer.MAX_VALUE.
You can work with the received memory section either using standard ByteBuffer methods or directly through Unsafe, by pulling out the memory address using Reflection:
Such a MappedByteBuffer does not have a publicly available unmap method, however there is a semi-legal way to free memory without calling GC:
In Oracle JDK, there is a class
Such a mechanism will work both in Linux and under Windows. Its only drawback is the lack of a possibility to select a specific address where the file will be “zamaplen”. This may be necessary if there are absolute references to memory addresses inside the same cache in the cache: such links will become invalid if you display the file at a different address. There are two ways out: either keep relative references as an offset from the beginning of the file, or resort to calling the native code via JNI or JNA. The mmap system calls in Linux and MapViewOfFileEx in Windows allow you to specify a preferred address where to file a file.
The key to cache performance, and the download server as a whole, is the cache search algorithm, i.e.
All memory is divided into segments of the same size - a basket of hash tables, over which keys are evenly distributed. In its simplest form
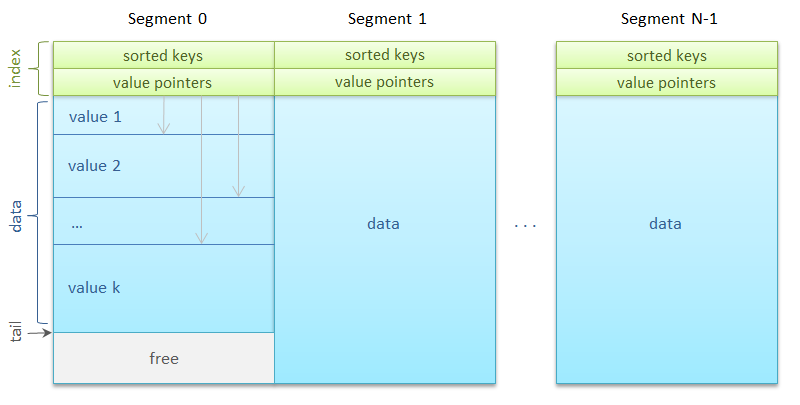
Segments may be many - a few thousand. Each of them is mapped to
An interesting detail: the use of standard
How to implement ReadWriteLock with Semaphore?
So the segment. It consists of an index area and a data area. An index is an ordered array of 256 keys, immediately followed by an array of 256 references to values. The link sets the offset inside the segment to the beginning of the data block and the length of this block in bytes.

The data blocks, that is, the actual images themselves, are aligned along an eight-byte boundary for optimal copying. The segment also stores the number of keys in it and the address of the next data block for the
The getter algorithm is extremely fast and simple:
The keys are written for a reason in a row in one selected area: this contributes to placing the index in the processor cache, ensuring the maximum speed of the binary key search.
The put method is also simple:
Of course, besides ours, there are a number of other solutions for caching data outside of the Java Heap, both free and paid. Of the most famous areTerracota Ehcache (with in-memory off-heap storage) and Apache Java Caching System . It is with them that we compared our own algorithm. The experiments were conducted on Linux JDK 7u4 64-bit and consisted of three scenarios:
The results of measurements are shown in the table. As you can see, both Ehcache and JCS are several times inferior in performance to the described algorithm.

However, it is worth noting that the described algorithm, being designed to solve the problem of image caching, does not cover many other scenarios. For example, the
Sources of the caching algorithm using Shared Memory on github:
https://github.com/odnoklassniki/shared-memory-cache
At the JUG.RU meeting in St. Petersburg, which will take place on July 25, 2012, apangin will share the experience of developing a high-load Java server, will talk about typical problems and unconventional techniques.
In the following articles, I will tell you how to write an RPC server that processes tens of thousands of requests per second, and I will also talk about an alternative serialization method that is several times higher than the standard Java mechanisms in performance and traffic volume. Stay with us!
It is quite natural that high loads required non-standard solutions. In a series of articles on the development of high-load Java server, I will talk about the problems we had to face and how we overcame them. Today we will talk about caching images outside the Java Heap and using Shared Memory in Java.
Caching
Since drawing images for each request from the storage is not an option, and there is no question of storing pictures on the disk (the disk queue will become a server bottleneck much earlier), you must have a fast cache in the application's memory.
')
The cache requirements were as follows:
- 64-bit keys, byte array values: image identifier - an integer of type long, and data - a picture in PNG, GIF or JPG format with an average size of 4 KB;
- In-process, in-memory: for maximum access speed, all data is in the process memory;
- RAM utilization: all available RAM is allocated to the cache;
- Off-heap: 50 GB of data placed in the Java Heap would be problematic;
- LRU or FIFO: obsolete keys may be supplanted by newer ones;
- Concurrency: simultaneous use of cache in a hundred threads;
- Persistence: the application can be restarted while preserving already cached data.
The fastest way to access memory outside of Heap from Java is through the
sun.misc.Unsafe class, since its getLong/putLong methods are JVM intrinsics, that is, their calls are replaced by the JIT compiler into just one machine instruction. Cache persistence between application launches is achieved using Shared memory
In Linux, Shared Memory objects are implemented using a special file system mounted to
/dev/shm . So, for example, the POSIX function shm_open("name", ...) equivalent to the open("/dev/shm/name", ...) system call. Thus, in Java we can work with Linux shared memory as with ordinary files. The following code snippet will open a shared memory object named image-cache with a size of 1 GB. If an object with the same name does not exist, a new one will be created. It is important that after the completion of the application the object will remain in memory and will be available the next time it is launched. RandomAccessFile f = new RandomAccessFile("/dev/shm/image-cache", "rw"); f.setLength(1024*1024*1024L); Now the created file object should be mapped into the address space of the process and get the address of this memory location.
Method 1. Legal, but defective
Let's use the Java NIO API:
RandomAccessFile f = ... MappedByteBuffer buffer = f.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, f.length()); The main disadvantage of this method is that it is impossible to display files larger than 2 GB, as described in the Javadoc to the map: must be non-negative and no greater than Integer.MAX_VALUE.
You can work with the received memory section either using standard ByteBuffer methods or directly through Unsafe, by pulling out the memory address using Reflection:
public static long getByteBufferAddress(ByteBuffer buffer) throws Exception { Field f = Buffer.class.getDeclaredField("address"); f.setAccessible(true); return f.getLong(buffer); } Such a MappedByteBuffer does not have a publicly available unmap method, however there is a semi-legal way to free memory without calling GC:
((sun.nio.ch.DirectBuffer) buffer).cleaner().clean(); Method 2. Completely in Java, but using "secret knowledge"
In Oracle JDK, there is a class
sun.nio.ch.FileChannelImpl with private methods map0 and unmap0 , which are not limited to 2 GB. map0 directly returns the address of the “jammed” section, which is even more convenient for us if we use Unsafe. Method map0 = FileChannelImpl.class.getDeclaredMethod( "map0", int.class, long.class, long.class); map0.setAccessible(true); long addr = (Long) map0.invoke(f.getChannel(), 1, 0L, f.length()); Method unmap0 = FileChannelImpl.class.getDeclaredMethod( "unmap0", long.class, long.class); unmap0.setAccessible(true); unmap0.invoke(null, addr, length); Such a mechanism will work both in Linux and under Windows. Its only drawback is the lack of a possibility to select a specific address where the file will be “zamaplen”. This may be necessary if there are absolute references to memory addresses inside the same cache in the cache: such links will become invalid if you display the file at a different address. There are two ways out: either keep relative references as an offset from the beginning of the file, or resort to calling the native code via JNI or JNA. The mmap system calls in Linux and MapViewOfFileEx in Windows allow you to specify a preferred address where to file a file.
Caching algorithm
The key to cache performance, and the download server as a whole, is the cache search algorithm, i.e.
get method The put method in our script is called much less often, but it should not be too slow either. I want to present our solution for fast thread-safe FIFO cache in a continuous fixed-size memory area.All memory is divided into segments of the same size - a basket of hash tables, over which keys are evenly distributed. In its simplest form
Segment s = segments[key % segments.length]; Segments may be many - a few thousand. Each of them is mapped to
ReadWriteLock . Simultaneously with the segment can work either an unlimited number of readers, or only one writer.An interesting detail: the use of standard
ReentrantReadWriteLock' led to a loss of 2 GB in the Java Heap. As it turned out, there is an error in JDK 6 that leads to excessive memory consumption by the ThreadLocal tables in the implementation of ReentrantReadWriteLock . Although the JDK 7 bug has already been fixed, in our case we replaced the voracious Lock with Semaphore . By the way, here's a little exercise for you:How to implement ReadWriteLock with Semaphore?
So the segment. It consists of an index area and a data area. An index is an ordered array of 256 keys, immediately followed by an array of 256 references to values. The link sets the offset inside the segment to the beginning of the data block and the length of this block in bytes.
The data blocks, that is, the actual images themselves, are aligned along an eight-byte boundary for optimal copying. The segment also stores the number of keys in it and the address of the next data block for the
put method. New blocks are written one after another according to the circular buffer principle. As soon as the place in the segment ends, the recording starts from the beginning of the segment over the earlier data.The getter algorithm is extremely fast and simple:
- the key hash calculates the segment in which the search will be performed;
- in the index area, a key is searched for by a binary search;
- if the key is found, from the array of links the offset is obtained, along which the data are located.
The keys are written for a reason in a row in one selected area: this contributes to placing the index in the processor cache, ensuring the maximum speed of the binary key search.
The put method is also simple:
- the key hash calculates the segment;
- reads the address of the next block of data and calculates the address of the next block by adding the size of the object being written, taking into account the alignment;
- if the segment is full, a linear search on the array of links will find and delete from the index the keys whose data will be overwritten by the next block;
- the value represented by the byte array is copied to the data area;
- binary search is a place in the index where the new key is inserted.
Work speed
Of course, besides ours, there are a number of other solutions for caching data outside of the Java Heap, both free and paid. Of the most famous are
- put: write 1 million values in size from 0 to 8 KB each;
- get: search by key 1 million values;
- 90% get + 10% put: combining get / put in a ratio that is close to the practical cache usage scenario.
The results of measurements are shown in the table. As you can see, both Ehcache and JCS are several times inferior in performance to the described algorithm.
However, it is worth noting that the described algorithm, being designed to solve the problem of image caching, does not cover many other scenarios. For example, the
remove and replace operations, although they can be easily implemented, will not free memory occupied by the same values.Where to look?
Sources of the caching algorithm using Shared Memory on github:
https://github.com/odnoklassniki/shared-memory-cache
Where to listen?
At the JUG.RU meeting in St. Petersburg, which will take place on July 25, 2012, apangin will share the experience of developing a high-load Java server, will talk about typical problems and unconventional techniques.
What's next?
In the following articles, I will tell you how to write an RPC server that processes tens of thousands of requests per second, and I will also talk about an alternative serialization method that is several times higher than the standard Java mechanisms in performance and traffic volume. Stay with us!
Source: https://habr.com/ru/post/148139/
All Articles