Parsim Russian language

Last time ( almost a year ago ) we defined parts of speech in the Russian text, made a morphological analysis of words. In this article, we will go one level up to parse whole sentences.
Our goal is to create a Russian parser, i.e. a program that would accept arbitrary text as input, and at the output would display its syntactic structure. For example:
" ": ( ( . ( )) (. . ( ) ( . ( ))) (. .))) ')
This is called a syntax sentence tree. In graphic form, it can be represented as follows (in simplified form):
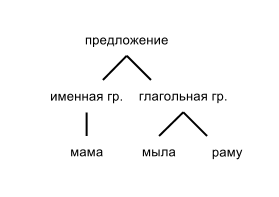
The definition of the syntactic structure of the sentence (parsing) is one of the main stages in the text analysis chain. Knowing the structure of the proposal, we can do a deeper analysis and other interesting things. For example, we can create an automatic translation system. In a simplified form, it looks like this: translate each word according to a dictionary, and then generate a sentence from the syntax tree:
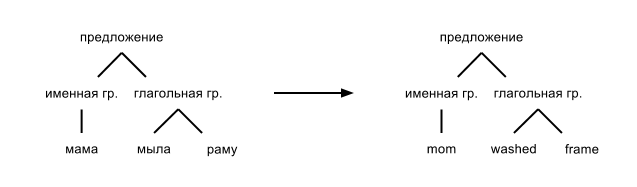
On Habré already there were several articles about parsing sentences ( 1 , 2 ), and at the Dialog conference even parser competitions are held . However, in this article I would like to talk about exactly how to parse the Russian language, instead of a dry theory.
Problems and tasks
So, why do I want to parse the Russian language and why is this an unsolved problem? First, parsing human languages (as opposed to computer languages) is difficult because of the large number of ambiguities (eg homonymy), exceptions to the rules, new words, etc. Secondly, a large number of developments and studies exist for the English language, but much less for Russian. Find an open parser for Russian is almost impossible. All existing practices (for example, STAGE, ABBYY and others) are closed to the public. However, for any serious text analysis task it is necessary to have a syntax parser.
A bit of theory
Although this is a practical article, not a theoretical one, I need to give a bit of theory in order to know what we are going to do. So, let us have a simple sentence “Mommy washed the frame.” What do we want to get as a result from the parser? There are a large number of models describing human languages, of which I would single out two of the most popular:
- Constituent grammar
- Dependency Grammar (dependency grammar)
The first of these (the grammar of the components) tries to break up the sentence into smaller structures - groups, and then each group into smaller groups, and so on until we get to individual words or phrases. The first example in this article was given using the grammar formalism of the components:
- we break the sentence into nominal and verb groups
- the nominal group is divided into a noun (mom)
- verb group on the verb (soap) and on the second noun phrase
- second verb group on the noun (frame)
To parse the sentence using the grammar of the components, you can use the parsers of formal languages (about this there were many articles on Habré: 1 , 2 ). The problem will subsequently be in the removal of ambiguities, since several syntactic trees will correspond to the same sentence. However, the biggest problem is that the grammar of the components is not very well suited for the Russian language, since In Russian, the word order in a sentence can often be interchanged without changing the meaning. For Russian, we better fit the grammar of dependencies.
In the grammar of dependencies, word order is not important, since we just want to know on which word each word in the sentence depends and the type of these connections. For example, it looks like this:
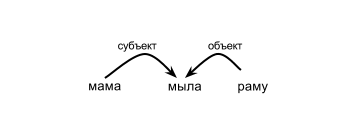
In this sentence, “mom” depends on the verb “to wash” and is the subject, “frame” also depends on the verb “to wash”, but is “object”. Even if we change the order of words in a sentence, the connections will still remain the same. So, from our parser we want to get a list of dependencies for the words in the sentence. It might look like this:
" ": (, ) (, ) On this with the theory we will finish and we will pass to practice.
Existing approaches
There are two main approaches when creating a syntax parser:
- Rule-based method
- Machine learning with a teacher (supervised machine learning)
You can also combine both methods and there are still methods of machine learning without a teacher, where the parser itself tries to create rules, trying to find patterns in unmarked texts ( Protasov, 2006 ).
The rule-based method is used in almost all commercial systems, since It gives the greatest accuracy. The basic idea is to create a set of rules that determine how to make connections in a sentence. For example, in our sentence “Mommy soap frame” we can apply the following rules (suppose that we have already removed all ambiguities and know the grammatical categories of words for sure):
- the word (“mother”) in the nominative case, feminine gender and singular should depend on the verb (“soap”) in the singular, past tense, feminine gender and type of connection should be “subject”
- the word (“frame”) in the accusative case should depend on the verb and the type of connection should be “object”
There can be many similar rules in the system, as well as anti-rules that indicate when you do NOT need to put links, for example, if a noun and a verb differ in gender or number, then there is no link between them. There are also rules of the third type, which indicate which pair of words should be preferred, if several options are possible. For example, in the sentence “mom soap window”: both “mom” and “window” can act as a subject, however, we can prefer the word to be next to the verb than the next.
This approach is very resource-intensive, because creating a parser requires a good team of linguists who should literally describe the entire Russian language. Therefore, we are more interested in the second approach - machine learning with a teacher.
The idea of parsing using machine learning, as in all other tasks of machine learning, is pretty simple: we give the computer a lot of examples with the correct answers that the system must learn on its own. To train syntactic parsers, specially labeled boxes (treebanks), collections of texts with a syntax structure, are used as learning data. Our offer in this package might look like this:
1 .... 2 2 ... 0 - 3 .... 2 In this format, we write each sentence as a line, where each line describes a single word as tab-separated records. For each word we need to store the following data:
- the number of the word in the sentence (1)
- word form (mom)
- Grammatical categories (nouns)
- main word number (2)
- communication type (subject)
In this article, unfortunately, there is not enough space to describe the detailed algorithms of different parsers. I just show you how to train an existing parser to work with the Russian language.
We learn parser
There are several open parsers that can be trained to work with the Russian language. Here are two that I tried to teach:
- MST Parser , based on the task of finding the minimum spanning tree
- MaltParser , based on machine learning (although MST Parser too, but there is a slightly different idea)
Learning an MST parser takes much more time and it also gives worse results than MaltParser, so we will focus on the second one later.
So, first you need to download MaltParser and unzip the downloaded archive .
> wget http://maltparser.org/dist/maltparser-1.7.1.tar.gz > tar xzvf maltparser-1.7.1.tar.gz > cd maltparser-1.7.1 The parser is written in Java, so you need a JVM for it to work. If you work with English, French or Swedish, then you can download ready-made models for these languages. However, we work with Russian, so we will be more fun.
To train a new language model, we need a marked body. For the Russian there is currently only one syntactically marked corpus - SynTagRus , which is part of the NCRF . I managed to get access to SynTagRus for non-proliferation and research purposes. The corpus is a set of texts marked up in XML format:
<S ID="8"> <W DOM="2" FEAT="S " ID="1" LEMMA="" LINK=""></W> <W DOM="_root" FEAT="V " ID="2" LEMMA=""></W> <W DOM="2" FEAT="S " ID="3" LEMMA="" LINK="2-"></W>, <W DOM="3" FEAT="A " ID="4" LEMMA="" LINK=""></W> <W DOM="4" FEAT="S " ID="5" LEMMA="" LINK="1-"></W> <W DOM="5" FEAT="S " ID="6" LEMMA="" LINK=""></W>. </S> To learn the parser, we need to convert the files to the malttab format. For these purposes, a small script was written that reads XML and produces the necessary format, simultaneously normalizing grammatical categories:
Smnom.sg 2 Vmreal.sg 0 ROOT Sfins.sg 2 2- Afins.sg 3 S.dat.m.sg 4 1- S.dat.m.sg 5 The documentation states that in order to learn the parser, it must be run with the following parameters:
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.conll -m learn - ( russian.mco) -i - -m , learn - However, I ran the training with additional arguments:
> java -Xmx8000m -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.tab -if appdata/dataformat/malttab.xml -m learn -l liblinear -Xmx8000m -if appdata/dataformat/malttab.xml malttab ( CoNLL, ) -l liblinear SVM LIBSVM As a result, we get the file russian.mco, which contains the trained model and the necessary configuration data. Now we have everything (or almost everything) that is needed to parse Russian texts.
Parsim Russian language
Starting the parsing is as follows:
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/input.tab -o out.tab -m parse - -i , -o , -m parse The only thing we need for parsing arbitrary text is a script that would prepare the text in the malttab format. To do this, the script should:
- Split text into sentences (segmentation into sentences)
- Break each sentence into words (tokenization)
- Define grammatical categories for each word (morphological analysis)
These three tasks are much simpler than parsing. And fortunately for Russian, there are open or free systems for morphological analysis. In the previous article, we even did a little bit of this, in the same place you can find references to other existing systems. For my purposes, I wrote a morphological analyzer based on machine learning, which I trained on the same SinTagRus. Perhaps next time I will describe him.
I made training on 1/6 part of SinTagRus and received a model for the Russian language, which you can ask for personal purposes. To use it, it is necessary that the grammatical categories coincide with those that I used when teaching the model.
This model showed accuracy (accuracy) of 78.1%, which is pretty good and is quite suitable for most purposes. A model trained on the entire body gives an accuracy of 79.6%.
Conclusion
Parsing is one of the basic steps for more complex text analysis. You can't find open parsers for the Russian language in the afternoon with fire. In this article I tried to fill this gap. If you wish (and access to SinTagRus), you can train open parsers and work with the Russian language. The accuracy of the trained parser is not perfect, although for many tasks it is quite acceptable. However, in my opinion, this is a good starting point for better results.
I do not specialize in parsers, and I am not an expert in Russian linguistics, but I will be glad to hear any criticism, suggestions and suggestions. Next time I hope to write either about the morphological analyzer, which was used together with the parser, or about my own parser on python (if by that time I’ve finished working on it).
I posted a simple online demo that, until it fell, looks like this:
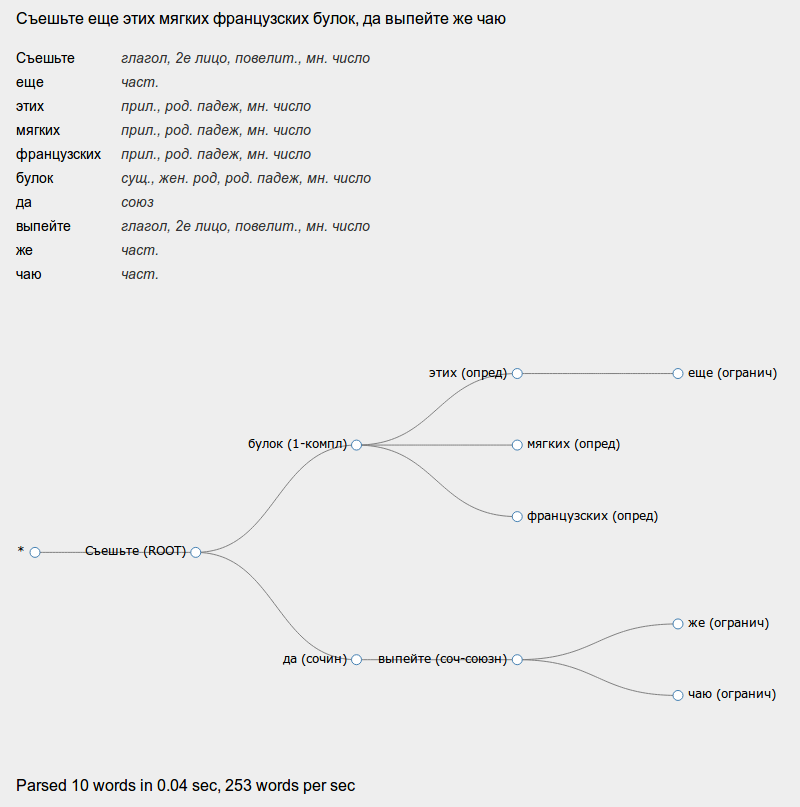
All code (except for the case) is available here: github.com/irokez/Pyrus
In conclusion, I would like to thank the NCRC, and in particular, the IITP RAS for providing access to SynTagRus.
Source: https://habr.com/ru/post/148124/
All Articles