Multiple encryption using hash functions
 Recently, it is necessary to think more and more about the safety of anonymity and security regarding the rights to information property. In this note, I will propose a rather interesting solution regarding encryption, allowing you to save several different objects in one container with different master keys, and guaranteeing the absence of “traces” of other entities when receiving any one. Moreover, due to the design features of the algorithm - even the presence of a decrypted entity can always be attributed to “randomness” (that is, there are no means to check whether this data was originally encrypted or not). In addition, the algorithm is extremely resistant to “key picking” attacks. True, the method has a significant drawback - a catastrophically low speed of work, but in some special cases it can still be useful.
Recently, it is necessary to think more and more about the safety of anonymity and security regarding the rights to information property. In this note, I will propose a rather interesting solution regarding encryption, allowing you to save several different objects in one container with different master keys, and guaranteeing the absence of “traces” of other entities when receiving any one. Moreover, due to the design features of the algorithm - even the presence of a decrypted entity can always be attributed to “randomness” (that is, there are no means to check whether this data was originally encrypted or not). In addition, the algorithm is extremely resistant to “key picking” attacks. True, the method has a significant drawback - a catastrophically low speed of work, but in some special cases it can still be useful.The core of the method is a mathematical object called a hash function . As a small educational program, I recommend to study my previous article as well .
There are a number of rather amusing misconceptions about hash functions:
- The hash function is easy to reverse. Supposedly there is a certain program md5decrypt, which restores the result md5crypt;
- Hash functions like MD5 have long been broken, because getting a collision on a given string is a trifling matter;
- Hash functions are an encryption algorithm.
All this is obviously nonsense. Cryptographic hash functions are by definition difficult to handle, and no one has proven otherwise for the methods currently used (MD5, SHA). We learned to build collisions only in the most general form, generating different strings s1, s2, such that f (s1) = f (s2). And hashing is not encryption, if only because the concept of encryption keys is missing.
But sometimes “nonsense” can help to construct an interesting solution, we will try for a second to imagine that the above theses are true. Even not so, we will construct object for which they will be executed.
')
Let R (key, message) = the first N bits of md5 (key + message), where N is not very large, say equal to 40. And then the interesting begins!
First, given the key key, we can easily build a large number of different messages that give the desired value of the function. Enumerating about 2 ^ 40 different lines is a task acceptable to the usual “home” computer. If we have a given value of X, which is the result of applying the function R, we can easily find the prototype.
That is, let X = R ('test_key', 'msg') = 5B7AF38712
We forget about the message 'msg', we have only the hash value 5B7AF38712 and the original key 'test_key', run the search, and after a while we get the string 'msg' as a prototype!
But what if we don’t know the key ('test_key'), but we only know the hash value? Then we can build an infinite number of key-message pairs, giving our X value.
Some of these couples will even look meaningful, whatever that means. Moreover, one of such pairs will be the main question of the life of the universe and all of this (in some wording) and the answer to it .
Why is that? Just because the set of input values (that is, keys and messages) is infinite, and the function R has a finite number of possible values, each of which (very roughly speaking) has an equal chance of appearing.
Now, I think, the idea of the process is clear - sending a person to '5B7AF38712', he, knowing the key ('test_key'), will receive the message ('msg') the fastest (but there are no guarantees of this, it should be noted). And, without knowing, - any garbage.
Magic
Now we want to learn how to encode messages so that the addressee can decipher them correctly with certain guarantees. And also, we are pretty tricky, and we want the same package to be decrypted with another key as another given message.
That is, at the input: key1, message1 and key2, message2.
And crypt (key1, message1, key2, message2) = X,
and decrypt (X, key1) = message1, and decrypt (X, key2) = message2.
Here we will have to “modernize” the function R, we will build a whole set of functions:
R m (key, msg) = first N bits md5 (key + line (m) + msg),
where string (m) is any unique representation of m as strings (for example, decimal notation).
The m index is a special “control value”, which we will vary when encrypting messages (that is, it is selected by our algorithm).
Before telling you how it is chosen, I will suggest a decryption procedure, since it’s pretty simple:
decrypt (X, key) = msg value, such that R (key, msg) == X, with the least m.
In an iterative form, you can write (pseudocode):
string decrypt(X, key) { for (int m = 0; m < MAX_INT; m++) for (string msg in generate_all_strings(MAX_STRING_LENGTH) ) if (first_N_bytes( md5( key + m.ToString() + msg) ) == X) // R() return msg; } Here appears the new parameter MAX_STRING_LENGTH , which is responsible for the maximum string length that we can iterate. It makes sense to limit it with adequate brute force performance, for example, if the original message was 'hello, Habrahabr', then the lines for encryption will have to be broken down into shorter sequences, for example, 'hell', 'o, H', 'abra', 'habr' and try on the encrypt function for each of them, not forgetting about the key alternation .
It is easy to get a collision for the first 40 bits, and this function is guaranteed to return any value. The task of the "encryption" is to ensure the return of the desired value.
But this, too, can be done by searching:
string encrypt(key, msg) { for (int m = 0; m < MAX_INT; m++) { string X = first_N_bytes( md5( key + m.ToString() + msg) ); // R() if (decrypt(X, key) == msg) return X; } } Thus, we provide confidence in the correct decoding of its simulation with various parameters. If the decryption algorithm does not change, then this is a guarantee of correctness, and notice that there are no checksums, validators, and other things that allow to “give out” the fact of correct decoding!
Initially, I was talking about the ability to encrypt two messages at once, which in fact is now becoming a self-evident fact:
string encrypt(key, msg, key2, msg2) { for (int m = 0; m < MAX_INT; m++) { string X = first_N_bytes( md5( key + m.ToString() + msg) ); // R() if (decrypt(X, key) == msg && decrypt(X, key2) == msg2) return X; } } However, there are some pitfalls here - with a fixed range of “reference values” (m) - such a function R m may not exist, and it will be necessary to extend the range. And expanding the range reduces the speed of the algorithm. In the general case, the range for the value of m should be greater than the digit capacity of the hash function R, so we can simply reduce it (which I did in the test prototype). But with a greatly reduced range of output values of such m, it may simply not exist either.
In general, when implementing the prototype, I stopped at a two-byte truncation. In addition, to partially address the performance issue (I quickly sketched a prototype in C #, and the “local” cryptographic providers are just awfully slow! Almost 50,000 times slower than the implementation on the GPU, which I will try to accomplish later) I left the possibility to use only letters range az. In this "sad" form it already works. Enter two key-value pairs, click “Encrypt2” and get a hash code after a while. With the first key, it is quickly decoded into the first message:

With the second, respectively, in the second:
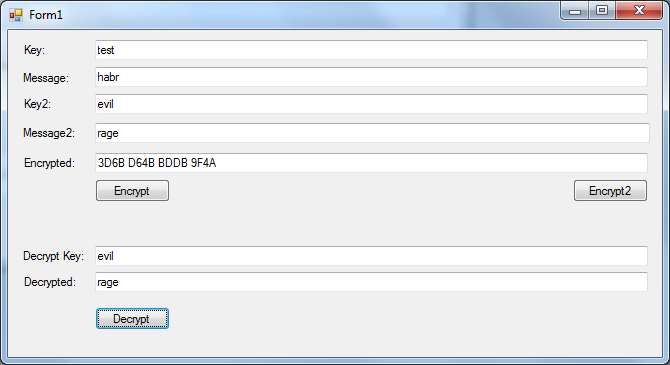
Notice, all the same encrypted text. Well, with the wrong key - in a strange message (but where is the guarantee that it was not the original?):

Download the prototype from here: dl.dropbox.com/u/243445/md5h/HashCode.7z
There are a lot of ridiculous restrictions in it, but for the outraged, I remind you that this is just an illustration of the idea. And on a good application, subject to the relevance of the idea, it will be possible to think.
Source: https://habr.com/ru/post/147857/
All Articles