The first acquaintance with the Linux kernel version 3.3 and 3.4
Next is an article translation from the IBM website. It is unlikely that you will learn something fundamentally new from it. This article is good to use as a starting point for reading about interesting or previously unknown features of Linux. Some references I cited in the text of the article in italics, some can be seen at the end of the original article. My explanations or comments are in italics.
Linux kernel releases versions 3.3 and 3.4 include an impressive amount of improvements. However, these releases are not just kernel development, but an ominous line on the path of this development.
The release of version 3.3 is the first release of the Linux kernel, the volume of which exceeded 15 million lines (even if it is based on a frankly curved measurement method). If you subtract the variable, non-permanent part of the code (various drivers, platform-specific code and various utilities), the number of lines drops slightly below 4 million — the leviathan in person.
The speed at which the core grows is ominous at this turn (a fifty percent growth since 2008), and the fact that this growth can adversely affect the core (both in terms of performance and in terms of core capabilities). Opportunities and performance usually do not measure “by the bat”, so a bug that may last for some time may well get into the kernel (for example, a problem with PCIe ASPM, which was in the kernel for almost a year, but was fixed in version 3.3. Description of www.pcworld com / businesscenter / article / 244277 / new_kernel_patch_slashes_linuxs_power_appetite.html and patch ( lkml.org/lkml/2011/11/10/467 )
In less than 21 years, Linux has grown from 10,000 lines of code to more than 15 million. In addition, most of this code is in the drivers subtree, and the complexity of the kernel increases with its size. Sooner or later, this extension should result in changes that will make the kernel more simple. Both from the point of view of the code, and from the point of view of support of this code.
')
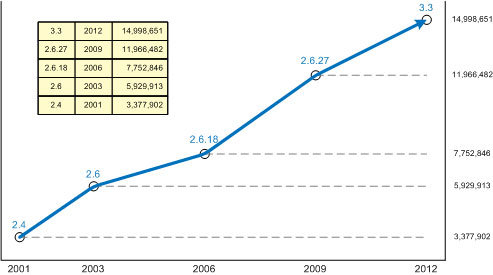
As shown in Figure 1, the kernel has grown rapidly since the release of 2.4 in 2001 (from 3,377,902 lines to 15,998,651 lines in 2012). During this period, each year about a million lines were added to the core. This is a stunning illustration and should inspire fear to every software developer.
They quote the words of Torvalds himself, about his concern for supporting the core, as it grows. With 4 million lines of code that make up the core of the kernel, the current kernel source control system may need to be improved.
The biggest news of kernel 3.3 is the inclusion of Google Android in the main branch of the kernel. This integration will continue in kernel 3.4, but already in the kernel there is enough code from the android to support the loading of the android in user-space. The core of the android is a fork of the Linux kernel, with several features. These features are introduced for the efficient operation of mobile devices, which are severely limited in available power. In addition, in Android, the main focus is on the ARM architecture, although x86 support is also present (for example, for the Google TV project).
The problems of interaction between Linux maintainers and Google led to the fact that Android was developed separately for several years. In the winter of 2011-2012, the Android Mainlining project was created, whose goal is to integrate drivers and new Android core functions into the main Linux source tree. The work done was presented to the general public in kernel 3.3 and will be continued in subsequent releases.
Android made several improvements to Linux that were needed to be competitive in a mobile environment. As an example, fast interprocess communication mechanisms (Fast IPC), improved memory management mechanisms and solving the problem of managing large continuous memory areas can be cited.
Binder is a driver that has become the answer of Android to standard IPC mechanisms. Android developers could easily use existing code, however, Binder's development provided several unique “chips” that were previously unavailable (sending messages without copying and sending “mandates.” For more information, see lwn.net/Articles/466304 ). In Android, applications never exit as usual, they work until the kernel completes them. To optimize the use of memory, there is a mechanism called Shrinker . Applications register a function that, when called, minimizes the amount of memory they use. The kernel calls these functions when it starts to run out of memory. Another mechanism that migrated from Android is Pmem . This mechanism allows you to allocate a physically continuous section of memory. This function is used, for example, when the camera is operating in phones. As part of this mechanism, there is an API in user space with which you can get a continuous chunk of memory from the system. In addition to these mechanisms, other functions specific to mobile devices were transferred from Android.
Some mechanisms have not yet hit the core. For example, wakelocks is a power management mechanism that allows individual programs to prevent the system from entering a low-power state (for example, if an update is in progress). This, of course, does not prevent Android from booting up, but it can lead to a quick devouring of the battery.
The merging of Android with the mainstream Linux kernel is another illustration of the flexibility of Linux. From embedded and mobile systems to the world's largest mainframes and supercomputers: Linux has got accustomed everywhere. And Linux continues its development as a universal system on more than 300 million mobile devices.
Linux continues to be the most popular virtualization platform. Linux is not only a world-class operating system, but also a world-class hypervisor. The introduction of Open vSwitch into the main branch of the kernel confirms this status for those users who use Linux as a virtualization platform and provide IaaS services on Linux.
A virtual switch is nothing more than a software implementation of a hardware switch. Let me remind you just in case that the virtualization platform (as done in KVM or Xen) allows you to run multiple copies of operating systems (as virtual machines) on a hypervisor that controls access to the physical resources of the machine. The introduction of a virtual switch extends this abstraction by introducing new forms of network infrastructure. A virtual switch provides efficient tools for virtual machines to communicate with each other over a virtual network. Open vSwitch extends the functions of a virtual switch, allowing you to integrate virtual networks of several hypervisors. Thus, virtual machines can communicate via a virtual network with machines that are on other hypervisors.
Inside the Open vSwitch implemented a wide range of functions for network virtualization. These features include QoS, vlans, filtering and isolating traffic, as well as a set of protocols for monitoring and control (such as OpenFlow and NetFlow). Despite the fact that Linux already had a virtual switch implementation (Linux Bridge), Open vSwitch is a much more functional solution and therefore a welcome addition.
In release 3.3, some changes have been made to a number of file systems that will be relevant for both users and developers. For users, this is an online resizing of ext4 volumes, by monitoring I / O operations (calling ioctl with the “EXT4_IOC_RESIZE_FS” flag). By "online" is meant that the system remains in working condition. In addition, now the entire resizing operation is performed in the kernel, which speeds it up.
The balancing mechanism for btrfs has been rewritten . Now it supports suspending and resuming work. This mechanism is used to change the structure of the metadata in such cases, for example, as adding a new hard disk. The btrfs enhancement continued in release 3.4, in which the utility for recovering data from damaged volumes was introduced ( btrfs-restore ). In addition, some changes were made to release 3.4, which improved speed and error handling in btrfs : instead of some error messages, now there is an elegant handling of these very errors. Before the 3.4 btrfs release, due to the COW mechanism, it was not very compatible with the Linux virtual memory manager (the latter tended to cache already unnecessary btrfs pages for too long). A revision was made to cure this deficiency. (corrected according to juick.com/thegreatz/1982110#5 )
RAID implementation has also been changed. Now the software implementation of RAID supports “hot swap”: data from one volume can be transferred to another volume, with the first one being later removed from the array without losing data. This function is controlled through the familiar mdadm.
Finally, in release 3.4, support for the QNX4 file system has been added (so far in read-only mode).
Developers were able to make errors in the network file system ( NFS ) to verify the client’s ability to recover from these errors (the mechanism works through sysfs). For brtfs developers, a file system integrity check utility has been added that can be used to detect invalid write requests, which will make it possible to fix problems faster.
Also in release 3.3 several advanced changes were made.
For low-latency environments (such as supercomputer computing), the ability to provide access to devices using the SCSI RDMA protocol was introduced ( you can read very briefly here: ru.wikipedia.org/wiki/InfiniBand ). SCSI RDMA is a protocol that allows you to use RDMA as a transport for block devices. RDMA is supported by InfiniBand and is quite common in supercomputer computing environments.
The RED (Random Early Detection ) package scheduler has been modified. The work algorithm was changed in accordance with the proposals of Sally Floyd, Ramakrishna Gummadi and Scott Shenker. The new scheduler is called ARED (Adaptive RED, it is customary to translate “adaptive”;). RED tracks the average size of the queue and dropped packets based on statistical probability. With an empty queue, all packets are accepted. When the queue is full above the threshold, almost all packets are dropped. In each case, ARED decides whether to make the RED more or less aggressive, based on observations of the average queue length. You can learn more about ARED from the materials at the link: icir.org/floyd/papers/adaptiveRed.pdf .
Also in release 3.3 a new implementation was added to replace the outdated bonding driver. Grouping several physical interfaces into one virtual interface allows you to create interfaces with more reliability and bandwidth (in accordance with, for example, the 802.1AX protocol). Currently, two modes of operation of the new mechanism are supported: simple packet distribution according to the round-robin or active-backup rule. In the first case, the packets are sent in turn from each of the physical interfaces. In the second case, the data is transmitted over one physical interface, and during its “fall” - over the backup one.
Among the large number of changes made, you can also highlight an interesting addition to the cgroups implementation: added implementation of buffer constraints for TCP. cgroups are used in various ways. Including - to limit the resources of virtual machines. After this change, the use of system memory has become more subtle, and therefore more detailed control of the system as a whole.
The release of kernel 3.3 also includes changes unrelated to file systems or the network. Support for the new architecture has been added: the project code has been added to the main branch of the kernel, to support the C6x process from Texas Instruments. C6x is a VLIW processor architecture with one or more cores. These processors do not support features such as SMP and cache coherence. In addition, they do not have a memory management unit (MMU). Despite these shortcomings, processors of the C6x series have a wide range of peripherals and additional units made directly on the chip (for example, for fast Fourier transform).
Release 3.4 includes support for the latest GPUs, such as Nvidia Kepler and the latest AMD Radeons and Trinity
In the ARM architecture, the LPAE extension is now supported (PAE for working with memory up to 1TB. For more details, for example, pdf from the page www.linux-arm.info/index.php/130-linux-support-for-arm-lpae ). In addition, support for Nvidia single-chip systems (Tegra 3) is included. These changes allow ARM processors to compete with Intel processors in the low-power server segment. A number of changes were made to the implementation of AMD IOMMU, which improved resizable memory page management and security in terms of memory access. Virtual I / O functions are expanding the KVM capabilities for providing devices to virtual machines. In addition, the S390 architecture has been enhanced to support up to 64TB of RAM (as opposed to 1 TB in previous versions)
The performance monitoring unit received a virtual interface for KVM. Thus, the guest OS can now monitor the performance on its platform. Within the framework of this monitoring, such metrics as “the number of executed instructions (retired instructions), hits and misses on the cache, as well as the success of prediction of transitions are available. Another useful innovation is the "safe reset" function. This function allows you not only to mark a sector in the query as free, but to completely delete it.
Different I / O drivers (blk, net, balloon and console) now support ACPI and S4 sleep state, which means that guest VMs on Xen can now be hibernated.
To debug complex memory corruption problems, a new configuration option CONFIG_DEBUG_PAGEALLOC has been added. When enabled, the processor access to non-alloted pages will be monitored. Enabling this option will naturally lead to a decrease in performance.
Linux continues to evolve and while release 3.4 is already out, release candidate 3.5 is almost ready for release in August 2012.
In the next release, we are also waiting for a lot of new things: btrfs has improved the writeback mechanism, added the ability to store checksums to ext4, to determine data manipulations. Linux may soon support the provision of access to its devices via SCSI over FireWire or SCSI over USB. They also promise to include support for the survey in the user-space and use SystemTap to analyze the data. In the future, many more interesting things await us, as the core develops.
Linux kernel releases versions 3.3 and 3.4 include an impressive amount of improvements. However, these releases are not just kernel development, but an ominous line on the path of this development.
The release of version 3.3 is the first release of the Linux kernel, the volume of which exceeded 15 million lines (even if it is based on a frankly curved measurement method). If you subtract the variable, non-permanent part of the code (various drivers, platform-specific code and various utilities), the number of lines drops slightly below 4 million — the leviathan in person.
The speed at which the core grows is ominous at this turn (a fifty percent growth since 2008), and the fact that this growth can adversely affect the core (both in terms of performance and in terms of core capabilities). Opportunities and performance usually do not measure “by the bat”, so a bug that may last for some time may well get into the kernel (for example, a problem with PCIe ASPM, which was in the kernel for almost a year, but was fixed in version 3.3. Description of www.pcworld com / businesscenter / article / 244277 / new_kernel_patch_slashes_linuxs_power_appetite.html and patch ( lkml.org/lkml/2011/11/10/467 )
In less than 21 years, Linux has grown from 10,000 lines of code to more than 15 million. In addition, most of this code is in the drivers subtree, and the complexity of the kernel increases with its size. Sooner or later, this extension should result in changes that will make the kernel more simple. Both from the point of view of the code, and from the point of view of support of this code.
')
As shown in Figure 1, the kernel has grown rapidly since the release of 2.4 in 2001 (from 3,377,902 lines to 15,998,651 lines in 2012). During this period, each year about a million lines were added to the core. This is a stunning illustration and should inspire fear to every software developer.
They quote the words of Torvalds himself, about his concern for supporting the core, as it grows. With 4 million lines of code that make up the core of the kernel, the current kernel source control system may need to be improved.
Android integration.
The biggest news of kernel 3.3 is the inclusion of Google Android in the main branch of the kernel. This integration will continue in kernel 3.4, but already in the kernel there is enough code from the android to support the loading of the android in user-space. The core of the android is a fork of the Linux kernel, with several features. These features are introduced for the efficient operation of mobile devices, which are severely limited in available power. In addition, in Android, the main focus is on the ARM architecture, although x86 support is also present (for example, for the Google TV project).
The problems of interaction between Linux maintainers and Google led to the fact that Android was developed separately for several years. In the winter of 2011-2012, the Android Mainlining project was created, whose goal is to integrate drivers and new Android core functions into the main Linux source tree. The work done was presented to the general public in kernel 3.3 and will be continued in subsequent releases.
Android made several improvements to Linux that were needed to be competitive in a mobile environment. As an example, fast interprocess communication mechanisms (Fast IPC), improved memory management mechanisms and solving the problem of managing large continuous memory areas can be cited.
Binder is a driver that has become the answer of Android to standard IPC mechanisms. Android developers could easily use existing code, however, Binder's development provided several unique “chips” that were previously unavailable (sending messages without copying and sending “mandates.” For more information, see lwn.net/Articles/466304 ). In Android, applications never exit as usual, they work until the kernel completes them. To optimize the use of memory, there is a mechanism called Shrinker . Applications register a function that, when called, minimizes the amount of memory they use. The kernel calls these functions when it starts to run out of memory. Another mechanism that migrated from Android is Pmem . This mechanism allows you to allocate a physically continuous section of memory. This function is used, for example, when the camera is operating in phones. As part of this mechanism, there is an API in user space with which you can get a continuous chunk of memory from the system. In addition to these mechanisms, other functions specific to mobile devices were transferred from Android.
Some mechanisms have not yet hit the core. For example, wakelocks is a power management mechanism that allows individual programs to prevent the system from entering a low-power state (for example, if an update is in progress). This, of course, does not prevent Android from booting up, but it can lead to a quick devouring of the battery.
The merging of Android with the mainstream Linux kernel is another illustration of the flexibility of Linux. From embedded and mobile systems to the world's largest mainframes and supercomputers: Linux has got accustomed everywhere. And Linux continues its development as a universal system on more than 300 million mobile devices.
Open vSwitch
Linux continues to be the most popular virtualization platform. Linux is not only a world-class operating system, but also a world-class hypervisor. The introduction of Open vSwitch into the main branch of the kernel confirms this status for those users who use Linux as a virtualization platform and provide IaaS services on Linux.
A virtual switch is nothing more than a software implementation of a hardware switch. Let me remind you just in case that the virtualization platform (as done in KVM or Xen) allows you to run multiple copies of operating systems (as virtual machines) on a hypervisor that controls access to the physical resources of the machine. The introduction of a virtual switch extends this abstraction by introducing new forms of network infrastructure. A virtual switch provides efficient tools for virtual machines to communicate with each other over a virtual network. Open vSwitch extends the functions of a virtual switch, allowing you to integrate virtual networks of several hypervisors. Thus, virtual machines can communicate via a virtual network with machines that are on other hypervisors.
Inside the Open vSwitch implemented a wide range of functions for network virtualization. These features include QoS, vlans, filtering and isolating traffic, as well as a set of protocols for monitoring and control (such as OpenFlow and NetFlow). Despite the fact that Linux already had a virtual switch implementation (Linux Bridge), Open vSwitch is a much more functional solution and therefore a welcome addition.
File system changes.
In release 3.3, some changes have been made to a number of file systems that will be relevant for both users and developers. For users, this is an online resizing of ext4 volumes, by monitoring I / O operations (calling ioctl with the “EXT4_IOC_RESIZE_FS” flag). By "online" is meant that the system remains in working condition. In addition, now the entire resizing operation is performed in the kernel, which speeds it up.
The balancing mechanism for btrfs has been rewritten . Now it supports suspending and resuming work. This mechanism is used to change the structure of the metadata in such cases, for example, as adding a new hard disk. The btrfs enhancement continued in release 3.4, in which the utility for recovering data from damaged volumes was introduced ( btrfs-restore ). In addition, some changes were made to release 3.4, which improved speed and error handling in btrfs : instead of some error messages, now there is an elegant handling of these very errors. Before the 3.4 btrfs release, due to the COW mechanism, it was not very compatible with the Linux virtual memory manager (the latter tended to cache already unnecessary btrfs pages for too long). A revision was made to cure this deficiency. (corrected according to juick.com/thegreatz/1982110#5 )
RAID implementation has also been changed. Now the software implementation of RAID supports “hot swap”: data from one volume can be transferred to another volume, with the first one being later removed from the array without losing data. This function is controlled through the familiar mdadm.
Finally, in release 3.4, support for the QNX4 file system has been added (so far in read-only mode).
Developers were able to make errors in the network file system ( NFS ) to verify the client’s ability to recover from these errors (the mechanism works through sysfs). For brtfs developers, a file system integrity check utility has been added that can be used to detect invalid write requests, which will make it possible to fix problems faster.
Network improvements.
Also in release 3.3 several advanced changes were made.
For low-latency environments (such as supercomputer computing), the ability to provide access to devices using the SCSI RDMA protocol was introduced ( you can read very briefly here: ru.wikipedia.org/wiki/InfiniBand ). SCSI RDMA is a protocol that allows you to use RDMA as a transport for block devices. RDMA is supported by InfiniBand and is quite common in supercomputer computing environments.
The RED (Random Early Detection ) package scheduler has been modified. The work algorithm was changed in accordance with the proposals of Sally Floyd, Ramakrishna Gummadi and Scott Shenker. The new scheduler is called ARED (Adaptive RED, it is customary to translate “adaptive”;). RED tracks the average size of the queue and dropped packets based on statistical probability. With an empty queue, all packets are accepted. When the queue is full above the threshold, almost all packets are dropped. In each case, ARED decides whether to make the RED more or less aggressive, based on observations of the average queue length. You can learn more about ARED from the materials at the link: icir.org/floyd/papers/adaptiveRed.pdf .
Also in release 3.3 a new implementation was added to replace the outdated bonding driver. Grouping several physical interfaces into one virtual interface allows you to create interfaces with more reliability and bandwidth (in accordance with, for example, the 802.1AX protocol). Currently, two modes of operation of the new mechanism are supported: simple packet distribution according to the round-robin or active-backup rule. In the first case, the packets are sent in turn from each of the physical interfaces. In the second case, the data is transmitted over one physical interface, and during its “fall” - over the backup one.
Among the large number of changes made, you can also highlight an interesting addition to the cgroups implementation: added implementation of buffer constraints for TCP. cgroups are used in various ways. Including - to limit the resources of virtual machines. After this change, the use of system memory has become more subtle, and therefore more detailed control of the system as a whole.
Other interesting changes
The release of kernel 3.3 also includes changes unrelated to file systems or the network. Support for the new architecture has been added: the project code has been added to the main branch of the kernel, to support the C6x process from Texas Instruments. C6x is a VLIW processor architecture with one or more cores. These processors do not support features such as SMP and cache coherence. In addition, they do not have a memory management unit (MMU). Despite these shortcomings, processors of the C6x series have a wide range of peripherals and additional units made directly on the chip (for example, for fast Fourier transform).
Release 3.4 includes support for the latest GPUs, such as Nvidia Kepler and the latest AMD Radeons and Trinity
In the ARM architecture, the LPAE extension is now supported (PAE for working with memory up to 1TB. For more details, for example, pdf from the page www.linux-arm.info/index.php/130-linux-support-for-arm-lpae ). In addition, support for Nvidia single-chip systems (Tegra 3) is included. These changes allow ARM processors to compete with Intel processors in the low-power server segment. A number of changes were made to the implementation of AMD IOMMU, which improved resizable memory page management and security in terms of memory access. Virtual I / O functions are expanding the KVM capabilities for providing devices to virtual machines. In addition, the S390 architecture has been enhanced to support up to 64TB of RAM (as opposed to 1 TB in previous versions)
The performance monitoring unit received a virtual interface for KVM. Thus, the guest OS can now monitor the performance on its platform. Within the framework of this monitoring, such metrics as “the number of executed instructions (retired instructions), hits and misses on the cache, as well as the success of prediction of transitions are available. Another useful innovation is the "safe reset" function. This function allows you not only to mark a sector in the query as free, but to completely delete it.
Different I / O drivers (blk, net, balloon and console) now support ACPI and S4 sleep state, which means that guest VMs on Xen can now be hibernated.
To debug complex memory corruption problems, a new configuration option CONFIG_DEBUG_PAGEALLOC has been added. When enabled, the processor access to non-alloted pages will be monitored. Enabling this option will naturally lead to a decrease in performance.
A look into the future.
Linux continues to evolve and while release 3.4 is already out, release candidate 3.5 is almost ready for release in August 2012.
In the next release, we are also waiting for a lot of new things: btrfs has improved the writeback mechanism, added the ability to store checksums to ext4, to determine data manipulations. Linux may soon support the provision of access to its devices via SCSI over FireWire or SCSI over USB. They also promise to include support for the survey in the user-space and use SystemTap to analyze the data. In the future, many more interesting things await us, as the core develops.
Source: https://habr.com/ru/post/147517/
All Articles