Options for building highly available systems in AWS. Overcoming interruptions. Part 1
Even monsters from the cloud industry like Amazon have hardware problems. In connection with recent interruptions in the work of the US East-1 data center, this article may be useful.
Options for building highly available systems in AWS. Overcoming outages
Fault tolerance is one of the main characteristics for all cloud systems. Every day, many applications are designed and deployed on AWS without this characteristic. The reasons for this behavior can range from technical ignorance in how to properly design a fault-tolerant system to the high cost of creating a complete, highly available system within AWS services. This article highlights several solutions that will help overcome the interruptions in the work of equipment providers and create a more suitable solution within the AWS infrastructure.
The structure of a typical Internet application consists of the following levels: DNS, Load Balancer, web server, application server, database, cache. Let's take this stack and consider in detail the main points that need to be considered when building a highly available system:
Part 2
High availability at the web server / application server level
')
In order to exclude a component from having a single point of failure (SPOF - Single Point of Failure), it is common practice to run a web application on two or more copies of EC2 virtual servers. This solution allows for higher fault tolerance compared to using a single server. Application servers and web servers can be configured with or without state check. The following are the most common architectural solutions for high-availability systems using state checking:
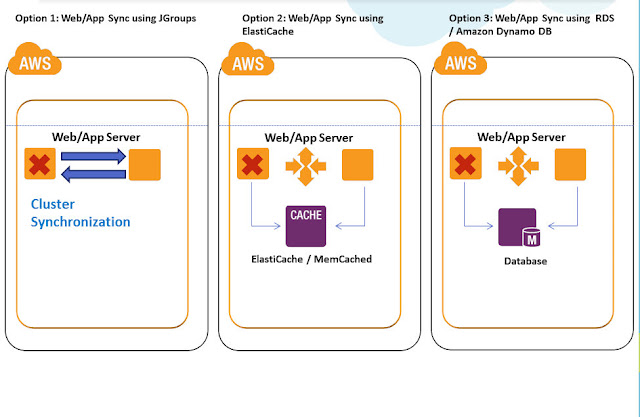
Key points that need attention when building such a system:
High availability at load balancing / DNS level
The DNS / Load Balancing level is the main entry point for the web application. There is no point in building complex clusters, heavy replicable web farms at the application level and database without building a highly available system at the DNS / LB level. If the load balancer is a single point of failure, its failure will render the entire system inaccessible. The following are the most common solutions for high availability at the load balancer level:
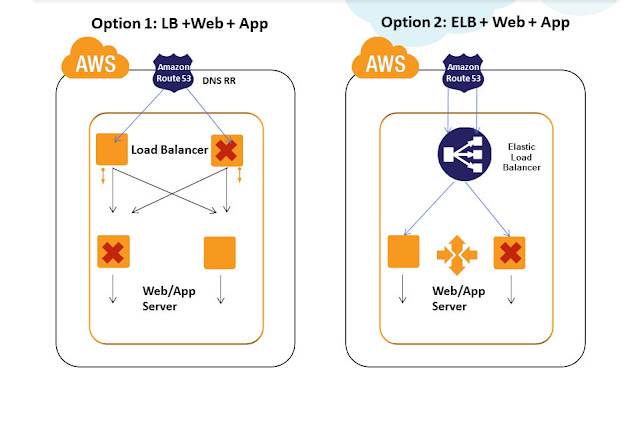
1) Use Amazon Elastic Load Balancer as a load balancer for high availability. Amazon ELB automatically distributes application load across multiple EC2 servers. This service gives you the opportunity to achieve more than the usual fault tolerance of the application, it allows you to smoothly increase the resources between which the load is distributed depending on the intensity of incoming traffic. This allows the maintenance of several thousand simultaneous connections and at the same time can flexibly expand as the load increases. ELB is essentially a fault-tolerant unit that can self-correct failures in its work. As the load increases, additional ELB EC2 virtual machines are automatically added at the ELB level. This automatically eliminates a single point of failure and the entire load distribution mechanism continues to work, even if some ELB EC2 virtual machines fail. Amazon ELB also automatically determines the availability of services between which it is necessary to distribute the load and in case of problems automatically sends requests to available servers. Amazon ELB can be configured to distribute the load using a random distribution of Round Robin, without checking the status of services, or using the mechanism of securing sessions and checking the state. If session synchronization is not implemented, even the use of session assignment cannot ensure the absence of application errors if one of the servers fails and users are redirected to an available server.
2) Sometimes applications require:
- Sophisticated load balancing with caching capability (Varnish)
- Using load sharing algorithms:
- at least connections - servers with fewer active connections receive more requests
- Minimum connections with weighting factors (Weighted Least-Connections) server with fewer active connections and more power receive more requests
- Distribution by source (Destination Hash Scheduling)
- Distribution by recipient (Source Hash Scheduling)
- Distribution based on the location and minimum of connections (Locality-Based Least-Connection Scheduling) - More requests will receive servers with a smaller number of active connections, taking into account the IP addresses of recipients
- Provide work with large short-term surges
- Presence of a fixed IP address with a load balancer
In all of the above cases, the use of Amazom ELB is not suitable. It is better to use third-party balancers or reverse proxies, such as: Nginx, Zeus, HAproxy, Varnish. But at the same time it is necessary to ensure the absence of a single point of failure, the simplest solution to this problem is to use several balancers. Zeus reverse proxy already has built-in functionality for working in a cluster, for other services it is necessary to use a round-robin DNS round robin distribution. Let's take a closer look at this mechanism, but first, let's define a few key points that need to be taken into account when building a reliable load sharing system within AWS:
Now let's discuss the level that stands above the balancer - DNS. Amazon Route 53 is a highly affordable, reliable and scalable DNS service. This service can effectively distribute user requests to all Amazon services, such as EC2, S3, ELB, as well as outside the AWS infrastructure. Route 53 is essentially a DNS-managed DNS server and can be configured either via the command line interface or through the web console. The service supports both cyclic and weight load balancing and can distribute requests between individual EC2 servers included in the balancer and for Amazon ELB. When using cyclic distribution, the availability check of the service and switching requests to available servers does not work and should be moved to the application level.
High availability at the database level
Data is the most valuable part of any application and designing high availability at the database level is top priority in any highly accessible system. To eliminate a single point of failure at the database level, it is common practice to use multiple database servers with data replication between them. This can be either a use, a cluster, or the use of a Master-Slave scheme. Let's look at the most popular solutions to this problem within AWS:

1) Using Master-Slave replication.
We can use one EC2 server as the main (master) and one or more as the secondary servers (slave). If these servers are in a public cloud, you must use ElastcIP, but if you use a private cloud (VPC), access between servers can be done via private IP addresses. In this mode, the server databases can use asynchronous replication. When the primary database server goes down, we can switch the secondary server to Master mode using our own scripts, thereby ensuring high availability. We can start replication between servers in Active-to-Active mode or Active-to-Passive mode. In the first case, write operations, intermediate write and read operations must be performed on the primary server, and read operations must be performed on the secondary server. In the second case, all read and write operations should be performed only on the primary server, and on a secondary server only if the primary server is unavailable after the secondary server switches to Master mode. It is recommended to use EBS images for EC2 database servers to ensure reliability and stability at the disk level. For additional performance and data integrity, you can configure the EC2 database server with various RAID array options within AWS.
2) MySQL NDBCluster
We can configure two or more MySQL EC2 servers as SQLD and data nodes for data storage and one MySQL server managing to create a cluster. All data nodes in a cluster can use asynchronous replication to synchronize data between themselves. Read and write operations can be simultaneously distributed across all storage nodes. When one of the storage nodes in the cluster fails, the other becomes active and processes all incoming requests. If you use a public cloud, you need ElasticIP addresses for each server in the cluster, if you use a private cloud, you can use internal IP addresses. It is recommended to use EBS images for EC2 database servers to ensure reliability and stability at the disk level. For additional performance and data integrity, you can configure the EC2 database server with various RAID array options within AWS.
3) Use of availability zones with RDS
If we use Amazon RDS MySQL at the database level, we can create one Master server in one availability zone and one Hot Standby server in another availability zone. Additionally, we have a modem to have several minor Read Replica servers in several availability zones. The primary and secondary RDS nodes can use synchronous data replication between themselves; Read Replica server uses asynchronous replication. When the Master RDS server is unavailable, Hot Standby becomes automatically available at the same address within a few minutes. All write, intermediate read and write operations must be performed on the Master server, read operations can be performed on the Read Replica servers. All RDS services use EBS images. Also, the RDS service provides automatic backup creation and with its help you can restore data from a specific point, RDS can also work within a private cloud.
The remaining points will be discussed in the second part:
Original article: harish11g.blogspot.in/2012/06/aws-high-availability-outage.html
Posted by: Harish Ganesan
Options for building highly available systems in AWS. Overcoming outages
Fault tolerance is one of the main characteristics for all cloud systems. Every day, many applications are designed and deployed on AWS without this characteristic. The reasons for this behavior can range from technical ignorance in how to properly design a fault-tolerant system to the high cost of creating a complete, highly available system within AWS services. This article highlights several solutions that will help overcome the interruptions in the work of equipment providers and create a more suitable solution within the AWS infrastructure.
The structure of a typical Internet application consists of the following levels: DNS, Load Balancer, web server, application server, database, cache. Let's take this stack and consider in detail the main points that need to be considered when building a highly available system:
- Build a High Availability System in AWS
- High availability at the web server / application server level
- High availability at load balancing / DNS level
- High availability at the database level
- Build a highly available system between AWS availability zones
- Build a highly available system between AWS regions
- Building a highly available system between different cloud and hosting providers
Part 2
High availability at the web server / application server level
')
In order to exclude a component from having a single point of failure (SPOF - Single Point of Failure), it is common practice to run a web application on two or more copies of EC2 virtual servers. This solution allows for higher fault tolerance compared to using a single server. Application servers and web servers can be configured with or without state check. The following are the most common architectural solutions for high-availability systems using state checking:
Key points that need attention when building such a system:
- Since the current AWS infrastructure does not support the Multicast protocol at the application level, data must be synchronized using regular Unicast TCP. For example, for Java applications you can use JGroups, Terracotta NAM, or similar software to synchronize data between servers. In the simplest case, you can use one-way synchronization using rsync, a more versatile and reliable solution is to use network-based distributed file systems such as GlusterFS.
- Memcached EC2, ElastiCache, or Amazon DynamoDB can be used to store user data and session information. For greater reliability, you can deploy the ElastiCache cluster in various AWS availability zones.
- Using ElasticIP to switch between servers is not recommended for highly critical systems, as this process can take up to two minutes.
- User data and sessions can be stored in a database. It is necessary to use this mechanism with caution, it is necessary to evaluate possible delays during read / write operations to the database.
- Files and documents uploaded by users should be stored on network file systems, such as NFS, Gluster Storage Pool or Amazon S3.
- Session commitments must be enabled at the Amazon ELB or reverse proxy level if sessions are not synchronized via a single repository, database, or other similar mechanism. This approach provides high availability but does not provide fault tolerance at the application level.
High availability at load balancing / DNS level
The DNS / Load Balancing level is the main entry point for the web application. There is no point in building complex clusters, heavy replicable web farms at the application level and database without building a highly available system at the DNS / LB level. If the load balancer is a single point of failure, its failure will render the entire system inaccessible. The following are the most common solutions for high availability at the load balancer level:
1) Use Amazon Elastic Load Balancer as a load balancer for high availability. Amazon ELB automatically distributes application load across multiple EC2 servers. This service gives you the opportunity to achieve more than the usual fault tolerance of the application, it allows you to smoothly increase the resources between which the load is distributed depending on the intensity of incoming traffic. This allows the maintenance of several thousand simultaneous connections and at the same time can flexibly expand as the load increases. ELB is essentially a fault-tolerant unit that can self-correct failures in its work. As the load increases, additional ELB EC2 virtual machines are automatically added at the ELB level. This automatically eliminates a single point of failure and the entire load distribution mechanism continues to work, even if some ELB EC2 virtual machines fail. Amazon ELB also automatically determines the availability of services between which it is necessary to distribute the load and in case of problems automatically sends requests to available servers. Amazon ELB can be configured to distribute the load using a random distribution of Round Robin, without checking the status of services, or using the mechanism of securing sessions and checking the state. If session synchronization is not implemented, even the use of session assignment cannot ensure the absence of application errors if one of the servers fails and users are redirected to an available server.
2) Sometimes applications require:
- Sophisticated load balancing with caching capability (Varnish)
- Using load sharing algorithms:
- at least connections - servers with fewer active connections receive more requests
- Minimum connections with weighting factors (Weighted Least-Connections) server with fewer active connections and more power receive more requests
- Distribution by source (Destination Hash Scheduling)
- Distribution by recipient (Source Hash Scheduling)
- Distribution based on the location and minimum of connections (Locality-Based Least-Connection Scheduling) - More requests will receive servers with a smaller number of active connections, taking into account the IP addresses of recipients
- Provide work with large short-term surges
- Presence of a fixed IP address with a load balancer
In all of the above cases, the use of Amazom ELB is not suitable. It is better to use third-party balancers or reverse proxies, such as: Nginx, Zeus, HAproxy, Varnish. But at the same time it is necessary to ensure the absence of a single point of failure, the simplest solution to this problem is to use several balancers. Zeus reverse proxy already has built-in functionality for working in a cluster, for other services it is necessary to use a round-robin DNS round robin distribution. Let's take a closer look at this mechanism, but first, let's define a few key points that need to be taken into account when building a reliable load sharing system within AWS:
- Multiple Nginx or HAproxy services can be configured to provide high availability in AWS, these services can determine service availability and distribute requests between available servers
- Nginx or HAproxy can be configured for cyclic load balancing, in case the application does not support state availability checking. Also, these services support work using the session consolidation mechanism, but if the synchronization of sessions is not properly provided, this does not guarantee the absence of errors at the application level when one server fails
- Horizontal scaling load balancers vertical scaling. Horizontal scaling increases the number of individual machines performing the balancing function, eliminating the presence of a single point of failure. To scale load balancers such as Nginx and HAproxy, you need to develop your own scripts and system images; using Amazon AutoScaling for scaling is not recommended in this case.
- To determine the availability of balancer servers, you can use the Amazon CloudWatch monitoring system or third-party monitoring services, such as Nagios, Zabbix, Icinga, and if one of the servers is unavailable using EC2 management scripts and command line utilities, launch a new server instance for the balancer within a few minutes .
Now let's discuss the level that stands above the balancer - DNS. Amazon Route 53 is a highly affordable, reliable and scalable DNS service. This service can effectively distribute user requests to all Amazon services, such as EC2, S3, ELB, as well as outside the AWS infrastructure. Route 53 is essentially a DNS-managed DNS server and can be configured either via the command line interface or through the web console. The service supports both cyclic and weight load balancing and can distribute requests between individual EC2 servers included in the balancer and for Amazon ELB. When using cyclic distribution, the availability check of the service and switching requests to available servers does not work and should be moved to the application level.
High availability at the database level
Data is the most valuable part of any application and designing high availability at the database level is top priority in any highly accessible system. To eliminate a single point of failure at the database level, it is common practice to use multiple database servers with data replication between them. This can be either a use, a cluster, or the use of a Master-Slave scheme. Let's look at the most popular solutions to this problem within AWS:
1) Using Master-Slave replication.
We can use one EC2 server as the main (master) and one or more as the secondary servers (slave). If these servers are in a public cloud, you must use ElastcIP, but if you use a private cloud (VPC), access between servers can be done via private IP addresses. In this mode, the server databases can use asynchronous replication. When the primary database server goes down, we can switch the secondary server to Master mode using our own scripts, thereby ensuring high availability. We can start replication between servers in Active-to-Active mode or Active-to-Passive mode. In the first case, write operations, intermediate write and read operations must be performed on the primary server, and read operations must be performed on the secondary server. In the second case, all read and write operations should be performed only on the primary server, and on a secondary server only if the primary server is unavailable after the secondary server switches to Master mode. It is recommended to use EBS images for EC2 database servers to ensure reliability and stability at the disk level. For additional performance and data integrity, you can configure the EC2 database server with various RAID array options within AWS.
2) MySQL NDBCluster
We can configure two or more MySQL EC2 servers as SQLD and data nodes for data storage and one MySQL server managing to create a cluster. All data nodes in a cluster can use asynchronous replication to synchronize data between themselves. Read and write operations can be simultaneously distributed across all storage nodes. When one of the storage nodes in the cluster fails, the other becomes active and processes all incoming requests. If you use a public cloud, you need ElasticIP addresses for each server in the cluster, if you use a private cloud, you can use internal IP addresses. It is recommended to use EBS images for EC2 database servers to ensure reliability and stability at the disk level. For additional performance and data integrity, you can configure the EC2 database server with various RAID array options within AWS.
3) Use of availability zones with RDS
If we use Amazon RDS MySQL at the database level, we can create one Master server in one availability zone and one Hot Standby server in another availability zone. Additionally, we have a modem to have several minor Read Replica servers in several availability zones. The primary and secondary RDS nodes can use synchronous data replication between themselves; Read Replica server uses asynchronous replication. When the Master RDS server is unavailable, Hot Standby becomes automatically available at the same address within a few minutes. All write, intermediate read and write operations must be performed on the Master server, read operations can be performed on the Read Replica servers. All RDS services use EBS images. Also, the RDS service provides automatic backup creation and with its help you can restore data from a specific point, RDS can also work within a private cloud.
The remaining points will be discussed in the second part:
- Build a highly available system between AWS availability zones
- Build a highly available system between AWS regions
- Building a highly available system between different cloud and hosting providers
Original article: harish11g.blogspot.in/2012/06/aws-high-availability-outage.html
Posted by: Harish Ganesan
Source: https://habr.com/ru/post/147390/
All Articles