Cloning objects in Node.js: Faster, deeper, more tender!
Not so long ago, after reading the article by idoroshenko “Why eval is not always bad,” I wondered whether it was possible to use the approach with generating the function body for cloning objects. Even wrote a small library for this. Benchmarks gave incredible results, but the applicability of this approach was limited only to multiple cloning of identical objects.
Therefore, I had a question: is there really no other way in v8 to avoid the costs associated with the multiple re-creation of hidden classes? After all, this is a major waste of resources when we clone objects. As it turned out, this possibility really exists: in v8 objects themselves there is a method v8 :: Object :: Clone . This method clones objects in the broad sense of the word, that is, the objects themselves, as well as arrays, dates, regular expressions, functions, etc., while preserving all their properties, including non-standard (for example, named properties of arrays) and even hidden.
There was only one small problem. This method was used only in the depths of node.js, and was not open to the outside, for javascript.
Without thinking, I went into the documentation of node.js for creating extensions in c ++ and wrote a trial version of the module, which simply reveals this function.
')
Having received acceleration for different objects about 10-100 times, I realized that this technique has a lot of potential, and began to implement it in the node-v8-clone ( npm ) module, trying not to lose this potential along the way, using a mixture TDD and benchmark driven development. This allowed us to monitor the speed in developing and correcting problems, as well as to monitor regressions during optimizations. At the same time, since the benchmarks and tests were ready, I decided to compare my module with others:
One of the goals was to maximize the quality of the cloning. I had to straighten the imagination in order to come up with enough unpleasant situations for the cloning process. These include, for example, functions, closures, arguments, regular expressions with the current state and properties added by the user. My module handles these situations like this:

How are the competitors, you can evaluate here .
I think it turned out very worthy.
It would be quite natural to assume that because of the support of high quality cloning, the speed should have dropped. And the speed really fell, but not so much that the node-v8-clone lost the primacy in most situations.
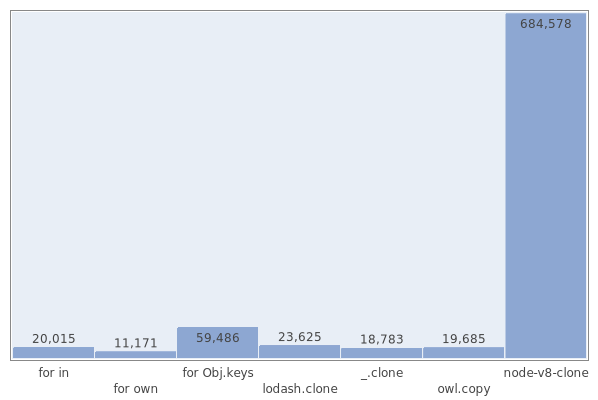
For example, here are the results of the surface cloning of an object of
Deep cloning of 500 nested arrays located in 4 levels of nesting, which contain 900 lines (the optimized version of cloning from node-v8-clone is also compared here, which does not pass another test, but significantly speeds up the work by deeply cloning arrays):
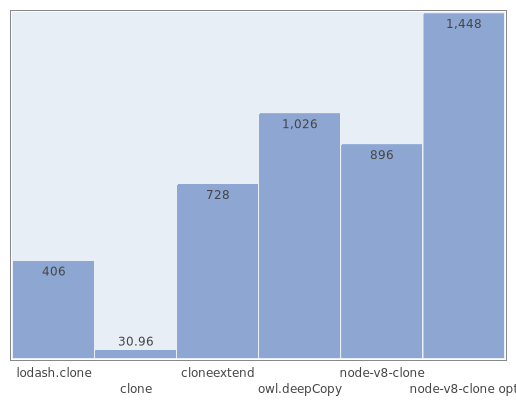
But with small arrays things are somewhat worse. This is due to the high cost of accessing the c ++ module, so simple algorithms, such as for, have an advantage.

All benchmark results.
I am going to repair cloning of node.js-ovsky buffers. Now they are cloned (a! == b), but they point to the same memory area and their contents are still bound.
I would like to fix the cloning of arguments. When a function has arguments, the arguments object is bound to the context of the function, and when cloned, they too are related to each other.
I would like to come up with even more tricky incoming data, such as file descriptors, modules, timers ... I do not expect that I will be able to really clone them, but at least I would like to understand how this module will behave with them.
I will be glad to any reviews, suggestions, bugs and patches. Well, fork me on GitHub :)
Therefore, I had a question: is there really no other way in v8 to avoid the costs associated with the multiple re-creation of hidden classes? After all, this is a major waste of resources when we clone objects. As it turned out, this possibility really exists: in v8 objects themselves there is a method v8 :: Object :: Clone . This method clones objects in the broad sense of the word, that is, the objects themselves, as well as arrays, dates, regular expressions, functions, etc., while preserving all their properties, including non-standard (for example, named properties of arrays) and even hidden.
There was only one small problem. This method was used only in the depths of node.js, and was not open to the outside, for javascript.
Without thinking, I went into the documentation of node.js for creating extensions in c ++ and wrote a trial version of the module, which simply reveals this function.
')
Having received acceleration for different objects about 10-100 times, I realized that this technique has a lot of potential, and began to implement it in the node-v8-clone ( npm ) module, trying not to lose this potential along the way, using a mixture TDD and benchmark driven development. This allowed us to monitor the speed in developing and correcting problems, as well as to monitor regressions during optimizations. At the same time, since the benchmarks and tests were ready, I decided to compare my module with others:
- lodash (about which I wrote recently )
- underscore
- owl-deepcopy
- clone
- cloneextend
Cloning quality
One of the goals was to maximize the quality of the cloning. I had to straighten the imagination in order to come up with enough unpleasant situations for the cloning process. These include, for example, functions, closures, arguments, regular expressions with the current state and properties added by the user. My module handles these situations like this:
How are the competitors, you can evaluate here .
I think it turned out very worthy.
Speed
It would be quite natural to assume that because of the support of high quality cloning, the speed should have dropped. And the speed really fell, but not so much that the node-v8-clone lost the primacy in most situations.
For example, here are the results of the surface cloning of an object of
{'_0': '_0', ..., '_99': '_99'} elements {'_0': '_0', ..., '_99': '_99'} (in operations per second):Deep cloning of 500 nested arrays located in 4 levels of nesting, which contain 900 lines (the optimized version of cloning from node-v8-clone is also compared here, which does not pass another test, but significantly speeds up the work by deeply cloning arrays):
But with small arrays things are somewhat worse. This is due to the high cost of accessing the c ++ module, so simple algorithms, such as for, have an advantage.
All benchmark results.
What's next
I am going to repair cloning of node.js-ovsky buffers. Now they are cloned (a! == b), but they point to the same memory area and their contents are still bound.
I would like to fix the cloning of arguments. When a function has arguments, the arguments object is bound to the context of the function, and when cloned, they too are related to each other.
I would like to come up with even more tricky incoming data, such as file descriptors, modules, timers ... I do not expect that I will be able to really clone them, but at least I would like to understand how this module will behave with them.
I will be glad to any reviews, suggestions, bugs and patches. Well, fork me on GitHub :)
Source: https://habr.com/ru/post/147124/
All Articles