Reference counting by atomic variables in C / C ++ and GCC
Author: Alexander Sandler , original article (May 27, 2009)
Suppose we have a data structure that manages objects and we would like to work with it and objects from two or more streams. To achieve maximum performance, we must distinguish between the mechanism used to protect the data structure itself and the mechanism used to protect current objects.
To explain why these two mechanisms provide the best performance and how atomic variables can be useful, consider the following situation.
The first stream (manipulator) must find a specific object in the data structure and modify it. The second stream (eraser) deletes obsolete objects. From time to time, the first thread tries to operate on an object that the second thread is trying to delete. This is a classic script that can be found in almost any multi-threaded program.
')
Obviously, the two streams should work with some kind of mutual exclusion mechanism. Suppose we protect the entire data structure with one mutex. In this case, the manipulator thread has to keep the mutex blocked until it finds the object and processes it. This means that the eraser stream will not have access to the data structure until the manipulator stream completes its work. If all that the manipulator stream does is search for records and process them, then the eraser stream simply cannot access the data structure.
Depending on the circumstances, this may become an imperceptible destruction for the system. And as already mentioned, the only way to solve this problem is the separation between the mechanisms protecting the data structure and protecting the actual objects.
If we do this, the manipulator thread will block the mutex only when searching for an object. As soon as he gets the object, he can release the mutex, which protects the data structure and allows the eraser to do its work.
But now, how can we be sure that the eraser thread will not delete the same object that is being changed by the first thread?
It would be possible to use another mutex protecting the contents of the actual object. But then there is an important question that we must ask ourselves. How many mutexes are needed to protect the contents of an object?
If we use one mutex for all objects, then we encounter the same congestion that we have just avoided. On the other hand, if we use a mutex for each object, we face a slightly different problem.
Suppose we created a mutex for each object. How should we manage mutexes for objects? We can put a mutex in the object itself, but this will create the following additional problem. In the event that the eraser decides to delete the object, but an instant before the manipulator stream decides to check the object and tries to block its mutex. Since the mutex has already taken the flow of the eraser, the manipulator will hibernate. But immediately after this exit, the eraser will delete the object and its mutex, leaving the manipulator asleep on a non-existent object. Oh.
In fact, there are a few things we can do. One of them is the use of object reference counting. However, we must protect the link counter itself . Fortunately, thanks to atomic variables, we do not need to use a mutex to protect the counter.
First, we initialize our object reference count to one. When the manipulator thread starts using it, it should increase the unit reference count. Having finished working with an object, it should decrease the reference count. That is, as long as the manipulator uses the object, it must keep the reference count incremented.
As soon as the eraser decides to delete an object, it must first remove it from the data structure. To do this, it must retain the mutex protecting the data structure. After that, it should decrease by one the counter of references to the object.
Now let's remember that we initialized the reference count by one. Thus, if an object is not used, its reference count should become zero. If it is zero, we can safely delete the object. This is all because, since the object is no longer in the data structure, we can be sure that the first stream will no longer use it.
And if its reference count is more than one? In this case, we must wait until the thread reference count is zero. But how to do that?
To answer this question can be very difficult. I usually consider one of two approaches. The naive approach or the approach that I call the RCU approach (Read-copy update).
Naive approach is as follows. We create a list of objects that we want to delete. Each time the eraser flow is activated, it goes through the list and deletes all objects whose reference count is zero.
Depending on the circumstances, there may be problems in this decision. The list of deleted objects can grow and a full pass through it can overload the processor. Depending on how often objects are deleted, this may be a good enough solution, but if this is not the case, then the RCU approach is worth considering.
RCU is another synchronization mechanism. It is mainly used in the Linux kernel. You can read about it here . I call this the RCU approach because it has some similarities with how the RCU synchronization mechanism works.
The idea comes from the assumption that the flow of the manipulator takes some time to work with the object. That is, basically, the manipulator continues to use the object for a certain time. After this time period, the object should cease to be used and the eraser stream should be able to delete it.
Assume that a manipulator flow basically takes one minute to complete its manipulations. Here I specifically exaggerate. When the eraser thread tries to delete an object, all it has to do is grab a mutex or spinlock that protects the data structure containing the objects and remove the object from this data structure.
Next, it should get the current time and save it in the object. The object must have methods that allow you to remember the time of your own deletion. Then the eraser thread will add it to the end of the list of deleted objects. This is a special list that contains all the objects that we want to delete - just like in the naive approach.
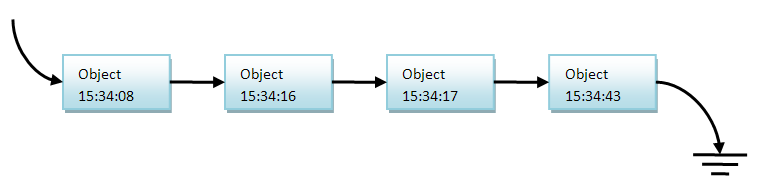
Note that adding objects to the end of the list makes them sorted by the time they were deleted. Earlier in the list are those objects that have earlier deletion time.
Next, the eraser should return to the top of the list, grab the object, and make sure that one minute has passed since it was removed from the data structure. If so, he should check his reference count and make sure that he is truly zero. If not, he should update his delete time to the current one and add it to the end of the list. Note that usually this should not happen. If the link counter of the eraser thread is zero, then it should remove the object from the list and delete it.
To show how this works, look at the picture above. Suppose now 15:35:12. This is more than one minute after we deleted the first object. Therefore, as soon as the eraser is activated and checks the list, it will immediately see that the first object in the list has been deleted more than a minute ago. It's time to remove the object from the list and check the next one.
He will check the next object, see that he is on the list for less than a minute and leave him on the list. Now - an interesting feature of this approach. The eraser thread should not check the rest of the list. Because we always add objects to the end of the list, the list is sorted and the eraser stream can be sure that other objects should not be deleted either.
So, instead of going through the entire list, as we did in a naive approach, we can use timestamps to create a sorted list of objects and check only a few objects at the top of the list. Depending on the circumstances, it will save a lot of time.
Starting with version 4.1.2, gcc has built-in support for atomic variables. They work on most architectures, but before using them, please check that your architecture supports them.
There is a set of functions that operate on atomic variables.
To use these functions, you do not need to include any header file. If your architecture does not support them, the linker will give an error, as if there was a call to a non-existent function.
Each of these functions operates on a variable of a certain type . A type can be either char , short , int , long , long long , or their unsigned equivalents.
A good idea is to wrap these functions with something that hides the implementation details. It can be a class that represents an atomic variable or an abstract data type.
Finally, there is my good example on the use of atomic variables in the article simple multi-threaded data access type and atomic variables .
I hope that the article will be interesting. For additional questions, please write to e-mail (specified in the original - approx. Lane.).
Translator's Note
This and other articles of the author do not pretend to be complete coverage of the material on the topic, but they have a good introductory style of presentation.
I note that at the moment atomic variables:
In addition to the author’s link to the RCU document, the Userspace RCU project, implementing RCU for userspace, is worth noting.
Introduction
Suppose we have a data structure that manages objects and we would like to work with it and objects from two or more streams. To achieve maximum performance, we must distinguish between the mechanism used to protect the data structure itself and the mechanism used to protect current objects.
Why do you need reference counting?
To explain why these two mechanisms provide the best performance and how atomic variables can be useful, consider the following situation.
The first stream (manipulator) must find a specific object in the data structure and modify it. The second stream (eraser) deletes obsolete objects. From time to time, the first thread tries to operate on an object that the second thread is trying to delete. This is a classic script that can be found in almost any multi-threaded program.
')
Obviously, the two streams should work with some kind of mutual exclusion mechanism. Suppose we protect the entire data structure with one mutex. In this case, the manipulator thread has to keep the mutex blocked until it finds the object and processes it. This means that the eraser stream will not have access to the data structure until the manipulator stream completes its work. If all that the manipulator stream does is search for records and process them, then the eraser stream simply cannot access the data structure.
Depending on the circumstances, this may become an imperceptible destruction for the system. And as already mentioned, the only way to solve this problem is the separation between the mechanisms protecting the data structure and protecting the actual objects.
If we do this, the manipulator thread will block the mutex only when searching for an object. As soon as he gets the object, he can release the mutex, which protects the data structure and allows the eraser to do its work.
But now, how can we be sure that the eraser thread will not delete the same object that is being changed by the first thread?
It would be possible to use another mutex protecting the contents of the actual object. But then there is an important question that we must ask ourselves. How many mutexes are needed to protect the contents of an object?
If we use one mutex for all objects, then we encounter the same congestion that we have just avoided. On the other hand, if we use a mutex for each object, we face a slightly different problem.
Suppose we created a mutex for each object. How should we manage mutexes for objects? We can put a mutex in the object itself, but this will create the following additional problem. In the event that the eraser decides to delete the object, but an instant before the manipulator stream decides to check the object and tries to block its mutex. Since the mutex has already taken the flow of the eraser, the manipulator will hibernate. But immediately after this exit, the eraser will delete the object and its mutex, leaving the manipulator asleep on a non-existent object. Oh.
In fact, there are a few things we can do. One of them is the use of object reference counting. However, we must protect the link counter itself . Fortunately, thanks to atomic variables, we do not need to use a mutex to protect the counter.
How we will use atomic variables to count object references
First, we initialize our object reference count to one. When the manipulator thread starts using it, it should increase the unit reference count. Having finished working with an object, it should decrease the reference count. That is, as long as the manipulator uses the object, it must keep the reference count incremented.
As soon as the eraser decides to delete an object, it must first remove it from the data structure. To do this, it must retain the mutex protecting the data structure. After that, it should decrease by one the counter of references to the object.
Now let's remember that we initialized the reference count by one. Thus, if an object is not used, its reference count should become zero. If it is zero, we can safely delete the object. This is all because, since the object is no longer in the data structure, we can be sure that the first stream will no longer use it.
And if its reference count is more than one? In this case, we must wait until the thread reference count is zero. But how to do that?
To answer this question can be very difficult. I usually consider one of two approaches. The naive approach or the approach that I call the RCU approach (Read-copy update).
Naive approach
Naive approach is as follows. We create a list of objects that we want to delete. Each time the eraser flow is activated, it goes through the list and deletes all objects whose reference count is zero.
Depending on the circumstances, there may be problems in this decision. The list of deleted objects can grow and a full pass through it can overload the processor. Depending on how often objects are deleted, this may be a good enough solution, but if this is not the case, then the RCU approach is worth considering.
RCU approach
RCU is another synchronization mechanism. It is mainly used in the Linux kernel. You can read about it here . I call this the RCU approach because it has some similarities with how the RCU synchronization mechanism works.
The idea comes from the assumption that the flow of the manipulator takes some time to work with the object. That is, basically, the manipulator continues to use the object for a certain time. After this time period, the object should cease to be used and the eraser stream should be able to delete it.
Assume that a manipulator flow basically takes one minute to complete its manipulations. Here I specifically exaggerate. When the eraser thread tries to delete an object, all it has to do is grab a mutex or spinlock that protects the data structure containing the objects and remove the object from this data structure.
Next, it should get the current time and save it in the object. The object must have methods that allow you to remember the time of your own deletion. Then the eraser thread will add it to the end of the list of deleted objects. This is a special list that contains all the objects that we want to delete - just like in the naive approach.
Note that adding objects to the end of the list makes them sorted by the time they were deleted. Earlier in the list are those objects that have earlier deletion time.
Next, the eraser should return to the top of the list, grab the object, and make sure that one minute has passed since it was removed from the data structure. If so, he should check his reference count and make sure that he is truly zero. If not, he should update his delete time to the current one and add it to the end of the list. Note that usually this should not happen. If the link counter of the eraser thread is zero, then it should remove the object from the list and delete it.
To show how this works, look at the picture above. Suppose now 15:35:12. This is more than one minute after we deleted the first object. Therefore, as soon as the eraser is activated and checks the list, it will immediately see that the first object in the list has been deleted more than a minute ago. It's time to remove the object from the list and check the next one.
He will check the next object, see that he is on the list for less than a minute and leave him on the list. Now - an interesting feature of this approach. The eraser thread should not check the rest of the list. Because we always add objects to the end of the list, the list is sorted and the eraser stream can be sure that other objects should not be deleted either.
So, instead of going through the entire list, as we did in a naive approach, we can use timestamps to create a sorted list of objects and check only a few objects at the top of the list. Depending on the circumstances, it will save a lot of time.
When did atomic variables appear?
Starting with version 4.1.2, gcc has built-in support for atomic variables. They work on most architectures, but before using them, please check that your architecture supports them.
There is a set of functions that operate on atomic variables.
type __sync_fetch_and_add (type *ptr, type value); type __sync_fetch_and_sub (type *ptr, type value); type __sync_fetch_and_or (type *ptr, type value); type __sync_fetch_and_and (type *ptr, type value); type __sync_fetch_and_xor (type *ptr, type value); type __sync_fetch_and_nand (type *ptr, type value); type __sync_add_and_fetch (type *ptr, type value); type __sync_sub_and_fetch (type *ptr, type value); type __sync_or_and_fetch (type *ptr, type value); type __sync_and_and_fetch (type *ptr, type value); type __sync_xor_and_fetch (type *ptr, type value); type __sync_nand_and_fetch (type *ptr, type value); To use these functions, you do not need to include any header file. If your architecture does not support them, the linker will give an error, as if there was a call to a non-existent function.
Each of these functions operates on a variable of a certain type . A type can be either char , short , int , long , long long , or their unsigned equivalents.
A good idea is to wrap these functions with something that hides the implementation details. It can be a class that represents an atomic variable or an abstract data type.
Finally, there is my good example on the use of atomic variables in the article simple multi-threaded data access type and atomic variables .
Conclusion
I hope that the article will be interesting. For additional questions, please write to e-mail (specified in the original - approx. Lane.).
Translator's Note
This and other articles of the author do not pretend to be complete coverage of the material on the topic, but they have a good introductory style of presentation.
I note that at the moment atomic variables:
- described in standards C11 (clause 7.17) and C ++ 11 (clause 29) - their implementations are available in most cases (true, for C11, there are still problems);
- described and implemented for Boost as Boost.Atomic (however, this implementation was never included in boost 1.50);
- implemented in Intel Threading Building Blocks .
In addition to the author’s link to the RCU document, the Userspace RCU project, implementing RCU for userspace, is worth noting.
Source: https://habr.com/ru/post/147107/
All Articles