Simple multithreaded data access and atomic variables
Author: Alexander Sandler , original article (December 23, 2008)
In this article I would like to continue the topic begun in my previous posts (see below - note of the translation). A question that I will try to answer is what is the most effective and secure way to access variables of simple data type from two or more streams. That is, how to change a variable from two threads at the same time without violating its value.
In my first post ( “Do I need a mutex to protect int” ), I showed how easy it is to turn a variable's value into garbage, changing it from two or more threads. In my second article ( “spin-lock pthread” ), I talked about spin-locks (spinlocks), the latest addition to the pthread library. Spin-blocking can really help solve the problem. However, they are more suitable for protecting small data structures than simple data types, such as int and long . On the other hand, atomic variables are ideal for these tasks.
The key point about atomic variables is that as soon as someone starts to read or write them, nothing can interrupt the process and happen in the middle. That is, nothing can break the access to the atomic variable into two parts. Therefore, they are called so.
')
On the practical side, atomic variables are the best solution for the problem of simultaneous access to a simple variable of two or more threads.
In fact, very simple. The architectures of the Intel x86 and x86_64 processors (as well as the vast majority of other modern processor architectures) have instructions for blocking the FSB during any memory access operation. FSB stands for Front Side Bus ( "front tire" - approx. Lane.). This is the bus that the processor uses to communicate with the RAM. That is, blocking the FSB will prevent any other processor (core) and process running on this processor from gaining access to the RAM. And this is exactly what we need to implement atomic variables.
Atomic variables are widely used in the Linux kernel, but for some reason no one bothered to implement them for the human user mode. Up to GCC 4.1.2.
For practical reasons, gurus from Intel did not implement FSB locks with every possible memory access. For example, to save time, Intel processors allow the memcpy () and memcmp () implementations to be implemented in the same processor instruction. But locking the FSB when copying a large memory buffer may be too expensive.
In practice, you can block the FSB by accessing integers of 1, 2, 4, and 8 bytes. GCC allows you to do atomic operations almost transparently with int , long, and long long (and their unsigned equivalents).
Increasing a variable, knowing that no one else will damage its value is good, but not enough. Consider the following pseudocode fragment.
Imagine that the value of an atomic variable is 1. What happens if two threads try to execute this part of the pseudo-C at the same time?
Let's return to our modeling. It is possible that flow 1 will execute line 1 and stop, while flow 2 will execute line 1 and continue execution of line 2. Later, flow 1 will wake up and execute line 2.
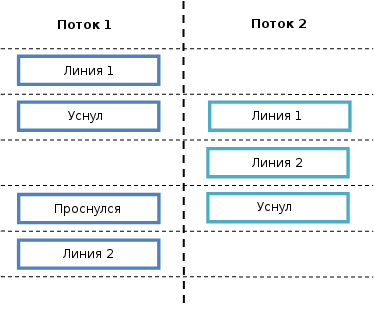
When this happens, none of the threads start the fire_a_gun () procedure (line 3). Obviously, this is an incorrect behavior, and if we protected this part of the code with a mutex or spinlock, this would not have happened.
As I already said, we could solve this problem by rejecting atomic variables and using a spin lock or mutex instead. Fortunately, we can still use atomic variables. GCC developers thought about our needs and this particular problem and offered a solution. Let's look at the actual procedures that operate on atomic variables.
There are some simple functions that make this work. First of all, there are twelve (yes, twelve - 12) functions that make atomic addition, replacement, and logical atomic or, and, xor, and nand. There are two functions for each operation. One that returns the value of a variable before changing it, and another that returns the value of a variable after changing it.
Here are the actual functions:
These are functions that return the value of a variable before changing. The following functions, on the other hand, return the value of a variable after changing it.
The type in each of the expressions can be one of the following:
These are called built-in functions, which means that you do not need to include any header files to use them.
Returning to the example that I started in the first post, which was mentioned earlier.
Let me remind you that this is a small program that opens several threads. The number of threads is equal to the number of processors in the computer. Then it binds each of the threads to one of the processors. Finally, each thread starts the loop and increments the global integer one million times.
Notice lines 36 and 37. Instead of simply increasing the variable, I use the built-in function __ sync_fetch_and_add () . Running this code obviously yields the expected results — that is, the global_int value is 4,000,000, as expected (the number of processors in the machine multiplied by one million — in my case, a quad-core machine). Remember, when I launched this code snippet, leaving line 36 as it is , the result was 1,908,090, not 4,000,000, as we expected.
When using atomic variables, some additional precautions must be taken. One of the serious problems with the implementation of the atomic variable in the GCC is that it allows you to perform atomic operations on ordinary variables. That is, there is no clear distinction between atomic and ordinary variables. Nothing prevents you from increasing the value of an atomic variable with __ sync_fetch_and_add () , as I just demonstrated, and then in the code, do the same with the usual ++ operator.
Obviously, this can be a serious problem. Things tend to be forgotten and it is only a matter of time until someone from your project or even you yourself begin to change the value of a variable using ordinary operators instead of atomic functions provided by GCC.
To solve this problem, I strongly recommend wrapping atomic functions and variables either using ADT (Abstract Data Type) in C, or using the C ++ class.
This article concludes a series of articles and posts where research and study of the latest technologies in the world of multi-threaded programming for Linux is conducted. I hope you find these posts and posts helpful. As usual, in case you have additional questions, please feel free to email me (specified in the original - approx. Lane)
Translator's Note
This and other articles of the author do not pretend to be complete coverage of the material on the topic, but they have a good introductory style of presentation.
I note that at the moment atomic variables:
Introduction
In this article I would like to continue the topic begun in my previous posts (see below - note of the translation). A question that I will try to answer is what is the most effective and secure way to access variables of simple data type from two or more streams. That is, how to change a variable from two threads at the same time without violating its value.
In my first post ( “Do I need a mutex to protect int” ), I showed how easy it is to turn a variable's value into garbage, changing it from two or more threads. In my second article ( “spin-lock pthread” ), I talked about spin-locks (spinlocks), the latest addition to the pthread library. Spin-blocking can really help solve the problem. However, they are more suitable for protecting small data structures than simple data types, such as int and long . On the other hand, atomic variables are ideal for these tasks.
The key point about atomic variables is that as soon as someone starts to read or write them, nothing can interrupt the process and happen in the middle. That is, nothing can break the access to the atomic variable into two parts. Therefore, they are called so.
')
On the practical side, atomic variables are the best solution for the problem of simultaneous access to a simple variable of two or more threads.
How atomic variables work
In fact, very simple. The architectures of the Intel x86 and x86_64 processors (as well as the vast majority of other modern processor architectures) have instructions for blocking the FSB during any memory access operation. FSB stands for Front Side Bus ( "front tire" - approx. Lane.). This is the bus that the processor uses to communicate with the RAM. That is, blocking the FSB will prevent any other processor (core) and process running on this processor from gaining access to the RAM. And this is exactly what we need to implement atomic variables.
Atomic variables are widely used in the Linux kernel, but for some reason no one bothered to implement them for the human user mode. Up to GCC 4.1.2.
Limiting the size of atomic variables
For practical reasons, gurus from Intel did not implement FSB locks with every possible memory access. For example, to save time, Intel processors allow the memcpy () and memcmp () implementations to be implemented in the same processor instruction. But locking the FSB when copying a large memory buffer may be too expensive.
In practice, you can block the FSB by accessing integers of 1, 2, 4, and 8 bytes. GCC allows you to do atomic operations almost transparently with int , long, and long long (and their unsigned equivalents).
Application options
Increasing a variable, knowing that no one else will damage its value is good, but not enough. Consider the following pseudocode fragment.
decrement_atomic_value(); if (atomic_value() == 0) fire_a_gun(); Imagine that the value of an atomic variable is 1. What happens if two threads try to execute this part of the pseudo-C at the same time?
Let's return to our modeling. It is possible that flow 1 will execute line 1 and stop, while flow 2 will execute line 1 and continue execution of line 2. Later, flow 1 will wake up and execute line 2.
When this happens, none of the threads start the fire_a_gun () procedure (line 3). Obviously, this is an incorrect behavior, and if we protected this part of the code with a mutex or spinlock, this would not have happened.
In case you are wondering what the likelihood is that something like this happens, be sure - this is very likely. When I first started working with multithreaded programming, I was amazed to learn that despite the fact that our intuition tells us that the scenario I described earlier is unlikely - it happens extremely often.
As I already said, we could solve this problem by rejecting atomic variables and using a spin lock or mutex instead. Fortunately, we can still use atomic variables. GCC developers thought about our needs and this particular problem and offered a solution. Let's look at the actual procedures that operate on atomic variables.
In the reality...
There are some simple functions that make this work. First of all, there are twelve (yes, twelve - 12) functions that make atomic addition, replacement, and logical atomic or, and, xor, and nand. There are two functions for each operation. One that returns the value of a variable before changing it, and another that returns the value of a variable after changing it.
Here are the actual functions:
type __sync_fetch_and_add (type *ptr, type value); type __sync_fetch_and_sub (type *ptr, type value); type __sync_fetch_and_or (type *ptr, type value); type __sync_fetch_and_and (type *ptr, type value); type __sync_fetch_and_xor (type *ptr, type value); type __sync_fetch_and_nand (type *ptr, type value); These are functions that return the value of a variable before changing. The following functions, on the other hand, return the value of a variable after changing it.
type __sync_add_and_fetch (type *ptr, type value); type __sync_sub_and_fetch (type *ptr, type value); type __sync_or_and_fetch (type *ptr, type value); type __sync_and_and_fetch (type *ptr, type value); type __sync_xor_and_fetch (type *ptr, type value); type __sync_nand_and_fetch (type *ptr, type value); The type in each of the expressions can be one of the following:
int unsigned int long unsigned long long long unsigned long long These are called built-in functions, which means that you do not need to include any header files to use them.
It's time to see this in action.
Returning to the example that I started in the first post, which was mentioned earlier.
Let me remind you that this is a small program that opens several threads. The number of threads is equal to the number of processors in the computer. Then it binds each of the threads to one of the processors. Finally, each thread starts the loop and increments the global integer one million times.
Source code
#include <stdio.h> #include <pthread.h> #include <unistd.h> #include <stdlib.h> #include <sched.h> #include <linux/unistd.h> #include <sys/syscall.h> #include <errno.h> #define INC_TO 1000000 // ... int global_int = 0; pid_t gettid( void ) { return syscall( __NR_gettid ); } void *thread_routine( void *arg ) { int i; int proc_num = (int)(long)arg; cpu_set_t set; CPU_ZERO( &set ); CPU_SET( proc_num, &set ); if (sched_setaffinity( gettid(), sizeof( cpu_set_t ), &set )) { perror( "sched_setaffinity" ); return NULL; } for (i = 0; i < INC_TO; i++) { // global_int++; __sync_fetch_and_add( &global_int, 1 ); } return NULL; } int main() { int procs = 0; int i; pthread_t *thrs; // procs = (int)sysconf( _SC_NPROCESSORS_ONLN ); if (procs < 0) { perror( "sysconf" ); return -1; } thrs = malloc( sizeof( pthread_t ) * procs ); if (thrs == NULL) { perror( "malloc" ); return -1; } printf( "Starting %d threads...\n", procs ); for (i = 0; i < procs; i++) { if (pthread_create( &thrs[i], NULL, thread_routine, (void *)(long)i )) { perror( "pthread_create" ); procs = i; break; } } for (i = 0; i < procs; i++) pthread_join( thrs[i], NULL ); free( thrs ); printf( " , global_int value : %d\n", global_int ); printf( " : %d\n", INC_TO * procs ); return 0; } Notice lines 36 and 37. Instead of simply increasing the variable, I use the built-in function __ sync_fetch_and_add () . Running this code obviously yields the expected results — that is, the global_int value is 4,000,000, as expected (the number of processors in the machine multiplied by one million — in my case, a quad-core machine). Remember, when I launched this code snippet, leaving line 36 as it is , the result was 1,908,090, not 4,000,000, as we expected.
Precautions
When using atomic variables, some additional precautions must be taken. One of the serious problems with the implementation of the atomic variable in the GCC is that it allows you to perform atomic operations on ordinary variables. That is, there is no clear distinction between atomic and ordinary variables. Nothing prevents you from increasing the value of an atomic variable with __ sync_fetch_and_add () , as I just demonstrated, and then in the code, do the same with the usual ++ operator.
Obviously, this can be a serious problem. Things tend to be forgotten and it is only a matter of time until someone from your project or even you yourself begin to change the value of a variable using ordinary operators instead of atomic functions provided by GCC.
To solve this problem, I strongly recommend wrapping atomic functions and variables either using ADT (Abstract Data Type) in C, or using the C ++ class.
Conclusion
This article concludes a series of articles and posts where research and study of the latest technologies in the world of multi-threaded programming for Linux is conducted. I hope you find these posts and posts helpful. As usual, in case you have additional questions, please feel free to email me (specified in the original - approx. Lane)
Translator's Note
This and other articles of the author do not pretend to be complete coverage of the material on the topic, but they have a good introductory style of presentation.
I note that at the moment atomic variables:
- described in standards C11 (clause 7.17) and C ++ 11 (clause 29) - their implementations are available in most cases (true, for C11, there are still problems);
- described and implemented for Boost as Boost.Atomic (however, this implementation was never included in boost 1.50);
- implemented in Intel Threading Building Blocks .
Source: https://habr.com/ru/post/147099/
All Articles